1.本公开涉及计算机技术领域,进一步涉及语音技术、自然语言处理等人工智能技术领域,尤其涉及一种模型生成方法、情绪识别方法、装置、电子设备及存储介质。
背景技术:
2.随着计算机技术的发展,人们可以通过计算机实现更多的新功能,情绪识别就是其中一种。
3.通过计算机进行情绪识别,包括通过检测外在可观测到的信息,对情绪状态进行判断。由于情绪是人类复杂的心理活动,因此,情绪识别的准确性的提高仍是一个需要长期关注的问题。
技术实现要素:
4.本公开提供了一种模型生成方法、情绪识别方法、装置、电子设备及存储介质。
5.根据本公开的一方面,提供了一种模型生成方法,包括:
6.将音频数据输入待训练的识别模型,获取针对音频数据输出的性别识别结果和情绪识别结果;
7.基于性别识别结果、情绪识别结果和标注结果,调整待训练的识别模型,得到情绪识别模型。
8.根据本公开的另一方面,提供了一种情绪识别方法,包括:
9.将待识别的音频数据输入识别模型,得到情绪识别结果,识别模型为本公开任意一项实施例所提供的情绪识别模型。
10.根据本公开的另一方面,提供了一种模型生成装置,包括:
11.识别模块,用于将音频数据输入待训练的识别模型,获取针对音频数据输出的性别识别结果和情绪识别结果;
12.训练模块,用于基于性别识别结果、情绪识别结果和标注结果,调整待训练的识别模型,得到情绪识别模型。
13.根据本公开的另一方面,提供了一种情绪识别装置,包括:
14.将待识别的音频数据输入识别模型,得到情绪识别结果,识别模型为本公开任意一项实施例所提供的情绪识别模型。
15.根据本公开的另一方面,提供了一种电子设备,包括:
16.至少一个处理器;以及
17.与该至少一个处理器通信连接的存储器;其中,
18.该存储器存储有可被该至少一个处理器执行的指令,该指令被该至少一个处理器执行,以使该至少一个处理器能够执行本公开任一实施例中的方法。
19.根据本公开的另一方面,提供了一种存储有计算机指令的非瞬时计算机可读存储介质,该计算机指令用于使计算机执行本公开任一实施例中的方法。
20.根据本公开的另一方面,提供了一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现本公开任一实施例中的方法。
21.根据本公开的技术,在识别情绪时,融入了性别信息,从而能够提高情绪识别结果的准确性。
22.应当理解,本部分所描述的内容并非旨在标识本公开的实施例的关键或重要特征,也不用于限制本公开的范围。本公开的其它特征将通过以下的说明书而变得容易理解。
附图说明
23.附图用于更好地理解本方案,不构成对本公开的限定。其中:
24.图1是根据本公开一实施例的模型生成方法示意图;
25.图2是根据本公开另一实施例的模型生成方法示意图;
26.图3是根据本公开又一实施例的模型生成方法示意图;
27.图4是根据本公开一实施例的识别方法示意图;
28.图5是根据本公开一示例的模型生成方法示意图;
29.图6是根据本公开一示例的待训练的识别模型生成示意图;
30.图7是根据本公开一实施例的模型生成装置示意图;
31.图8是根据本公开另一实施例的模型生成装置示意图;
32.图9是根据本公开又一实施例的模型生成装置示意图;
33.图10是根据本公开又一实施例的模型生成装置示意图;
34.图11是根据本公开又一实施例的模型生成装置示意图;
35.图12是根据本公开又一实施例的模型生成装置示意图;
36.图13是根据本公开又一实施例的模型生成装置示意图;
37.图14是用来实现本公开实施例的模型生成方法的电子设备的框图。
具体实施方式
38.以下结合附图对本公开的示范性实施例做出说明,其中包括本公开实施例的各种细节以助于理解,应当将它们认为仅仅是示范性的。因此,本领域普通技术人员应当认识到,可以对这里描述的实施例做出各种改变和修改,而不会背离本公开的范围和精神。同样,为了清楚和简明,以下的描述中省略了对公知功能和结构的描述。
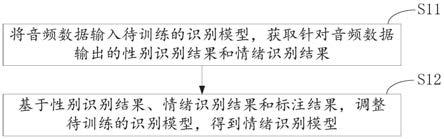
39.本公开实施例首先提供一种模型生成方法,如图1所示,包括:
40.步骤s11:将音频数据输入待训练的识别模型,获取针对音频数据输出的性别识别结果和情绪识别结果;
41.步骤s12:基于性别识别结果、情绪识别结果和标注结果,调整待训练的识别模型,得到情绪识别模型。
42.本实施例中,音频数据可以是包含人或动物声音的任何音频数据。比如,可以是人说话的音频数据、唱歌的音频数据或者人嗓子发出声音产生的其它音频数据。
43.音频数据可以包括一个发声者发出的声音,也可以包括两个以上不同发声者发出的声音。
44.音频数据可以包括采用单独种类的语言说话产生的音频,还可以包括采用多种语
言说话产生的音频,比如,可以是发声者采用汉语说话产生的音频、采用外语说话产生的音频、汉语和外语夹杂使用产生的音频以及不同外语夹杂使用产生的音频。
45.针对音频数据输出的性别识别结果和情绪识别结果,包括针对音频数据中至少一个发声者的声音,输出关于发声者的性别的识别结果和关于发声者的情绪的识别结果。
46.性别识别结果可以包括音频数据的发声者属于各种性别的概率,比如,发声者属于男性的概率为60%,属于女性的概率为40%。性别识别结果也可以包括单独的一种性别的识别结果,比如第一发声者属于男性,第二发声者属于女性。
47.情绪识别结果可以包括音频数据的发声者处于各种情绪状态的概率,比如,发声者处于高兴情绪状态的概率为80%,处于伤心情绪状态的概率为20%。情绪识别结果也可以包括单独、明确的情绪识别结果,比如,发声者处于高兴情绪,或者发声者处于高兴与紧张结合的情绪。
48.在另一种实现方式中,如果情绪识别结果中包括两种完全冲突的情绪,则可在完全冲突的两种情绪中选择一种情绪输出,如果情绪识别结果中包括可共同出现的两种以上的情绪,如开心和放松,则可同时输出两种以上可共同出现的情绪。
49.本实施例中,获取针对音频数据输出的性别识别结果和情绪识别结果,可以包括针对音频数据获取性别识别的中间数据和情绪识别的中间数据;基于性别识别的中间数据和情绪识别的中间数据获取针对音频数据的情绪识别结果,基于性别识别的中间数据湖区针对音频数据的性别识别结果。
50.本实施例中,标注结果可以包括性别标注结果和情绪标注结果。
51.性别标注结果可以为男性或女性。
52.在其它实施方式中,性别识别结果和性别标注结果也可以在性别大类下对应按照年龄等信息分为更多的小类,比如,男性儿童、男性青年、女性少年等。
53.情绪标注结果可以为预设的多个情绪中的至少一种,如,喜、怒、哀、乐。
54.本实施例中,基于性别识别结果、情绪识别结果和标注结果,调整待训练的识别模型,可以包括:基于性别识别结果和关于性别的标注结果,优化或调整待训练的识别模型;以及,基于情绪识别结果和关于情绪的标注结果,优化或调整待训练的识别模型。
55.语音是人类交流中情感的重要载体,语音识别的关注点在于说话者说的内容,而情绪识别的关注点在于说话者说话的方式,人们在不同情绪状态下的语言表达方式会有所不同,呈现在人们所发出的音频信息中的特征也有所不同。例如,人们高兴时说话的语调会比较欢快,而烦躁伤心时语气比较沉闷。在一般情况下,人们说话发出的声音,通过语速、语调、音量等信息,能够确定声音中体现出的情绪信息;深度学习技术的发展更是加速了从语音中检测情绪的进展。但是通过音频或者语音识别发声者的情绪,仍然存在一些不足,音频中的情感与音频的发声者之间存在者很大的联系。且不同的收听者,在收听到音频时,从中理解出的情绪也会有所不同,同时,文化差异等因素,更是增加了从音频中识别情绪的困难。通过研究发现,语速、音调、音量等信息相同的情况下,不同性别的人发出的声音中所表达的情绪也会有所差别。通常情况下,语音情绪的表现在不同性别上是不一样的,即女性的生气与男性的生气可能在语调语气上有所不同,其他情绪如激动,恐惧,伤心等也类似。具体比如,同样语调、同样内容的话语,一种性别的人发出时可能表达了烦躁的情绪,而另一种性别的人发出时可能表达了傲慢的情绪。
56.因此,本实施例中,在设计特征以及模型网络时,考虑了音频数据中的性别信息。根据音频数据,能够获得性别识别结果和情绪识别结果。根据待训练的识别模型输出的性别识别结果和情绪识别结果,以及针对性别和情绪的标注结果,对待训练的识别模型进行训练或调整,得到情绪识别模型。由于在情绪识别的过程中结合了性别信息,可以增加情绪识别时所参考的信息,提高情绪识别结果的准确性。
57.在一种实施方式中,将音频数据输入待训练的识别模型,获取针对音频数据输出的性别识别结果和情绪识别结果,如图2所示,包括:
58.步骤s21:采用待训练的识别模型的前处理层,根据音频数据获取至少融合了情绪信息和性别信息的第一数据;
59.步骤s22:采用待训练的识别模型的性别识别输出层,根据第一数据获得性别识别结果;
60.步骤s23:采用待训练的识别模型的情绪识别输出层,根据第一数据获得情绪识别结果;
61.前处理层为待训练的识别模型中,性别识别输出层和情绪识别输出层之前的数据处理层。
62.本实施例中,步骤s22和步骤s23可以同时执行,也可以按照任意顺序先后执行。
63.本实施例中,除了最后的输出层之外,识别模型用于获取情绪识别结果的部分和用于获取性别识别结果的部分可以共用。比如,输入层、输入层和输出层之间的数据处理层可以为情绪识别处理和性别识别处理的共用数据处理层。
64.本实施例中,前处理层可以不包括输入层。
65.本实施例中,用于识别音频数据的情绪信息的数据处理层和用于识别音频数据的数据处理层可以共用,从而在识别情绪的时候能够充分考虑音频中的性别信息。
66.在一种实施方式中,根据音频数据获取至少融合了情绪信息和性别信息的第一数据,如图3所示,包括:
67.步骤s31:对音频数据进行频域信息提取,获取第二数据;
68.步骤s32:对第二数据进行卷积和池化计算,获取第三数据;
69.步骤s33:采用双向长短期记忆神经网络(long short term memory,lstm)对第三数据进行处理,获取第四数据;
70.步骤s34:对第四数据进行自注意力(self attention)权值计算,获取第一数据。
71.本实施例中,频域信息可以是声音的频谱,有助于更为直观地认识音频数据。频谱可以是频率谱密度的简称,可以用频率的分布曲线体现。复杂振荡可以分解为振幅不同和频率不同的谐振荡,这些谐振荡的幅值按频率排列的图形可以叫做频谱。频谱可以体现音频信号是频域信息。
72.对第二数据进行卷积和池化计算,获取第三数据,可以包括对第二数据线进行卷积计算后进行池化计算,获取第三数据;也可以包括对第二数据先进性池化计算后进行卷积计算,获取第三数据。
73.对音频数据进行频域信息提取,可以是通过待训练的识别模型的频谱提取层,对音频数据进行频域信息的提取。
74.本实施例中,采用双向长短期记忆神经网络对第三数据进行处理,可以包括采用
双向长短期记忆神经网络对第三数据进行前向计算处理,在进行反向计算处理。
75.对第四数据进行自注意力权值计算,可以是采用待训练的识别模型的自注意力机制层,对第四数据进行计算,赋予第四数据中较为重要的信息以相对较高的权值。
76.本实施例中,能够通过频域信息的提取、双向长短期记忆神经网络、自注意力机制信息,获得音频数据中关于性别和情感的丰富的数据,从而能够对情绪进行更为准确的判断。
77.同时,在待训练的识别模型对音频数据进行频谱提取层、卷积层、池化层、双向长短期记忆神经网络、自注意力层的计算时,还能够同时处理和保留音频中的性别信息和情绪信息,使得后续的情绪识别结果与性别识别结果相关。
78.在一种实施方式中,模型生成方法还包括通过以下方式获取音频数据:
79.对获取到的原始音频数据进行预处理,得到预处理结果;
80.对预处理结果进行数据增强操作,获取原始音频数据的增强数据;
81.将原始音频数据以及增强数据,作为音频数据。
82.本实施例中,预处理可以包括降噪、过滤背景声音、调整音量、声音剪辑等操作。
83.预处理结果可以是预处理后的原始音频数据。
84.原始音频数据可以是采用音频录制设备获取的原始的音频数据。也可以是视频数据中的音频部分。
85.对预处理结果进行数据增强操作,可以是对预处理结果进行数据扩增,在不实质性的增加数据的情况下,产生与实质增加更多的训练数据基本等同的结果,让有限的数据产生等价于更多数据的训练效果,提升训练模型所用的数据的覆盖度。
86.本实施例中,数据增强可以是有监督的数据增强,即可以是采用预设的数据变换规则,在已有数据的基础上进行数据的扩增。数据增强也可以是无监督的数据增强。另外,数据增强可以包括单样本数据增强和多样本数据增强,还可以包括生成新的数据增强和学习增强策略增强。
87.本实施例中,将原始音频数据以及原始音频数据的增强数据作为音频数据,从而能够充分利用有限的原始音频数据,提高训练集的利用率。
88.在一种实施方式中,在数据增强操作为差分增强操作的情况下,对预处理结果进行数据增强操作,获取原始音频数据的增强数据,包括:
89.提取原始音频数据的目标音频特征;
90.对目标音频特征执行差分增强操作,获取原始音频数据的增强数据。
91.本实施例中,原始音频数据的目标音频特征,可以是在待训练的识别模型的排序为前序的数据处理层提取出的初级音频特征,具体可以包括在原始音频数据中可以直接提取出的音频特征还可以包括对经过处理(降噪等)的原始音频数据进行提取得到的音频特征。
92.本实施例中,初级音频特征可以与音频数据的波形相关,可以是语音数据的等价表现形式,包含情绪、性别、语种等多方面信息。可以通过尝试不同的特征组合来获取不同的初级音频特征(或前端特征),比如mfcc(mel
‑
frequency cepstral coefficients,梅尔倒频谱系数)与plp(perceptual linear predictive,感知线性预测系数),或不同的维度的特征比如40
‑
80(音频文件单元的大小)等。
93.对目标音频特征执行差分增强操作,可以包括对目标音频特征进行部分差分增强和全部差分增强。
94.本实施例中,能够根据原始音频数据进行差分增强,从而提高音频的数据量,提高有限的原始音频数据在训练待训练的识别模型时的使用效果。
95.在一种实施方式中,对获取到的原始音频数据进行预处理,得到预处理结果,包括:
96.对原始音频数据执行下述操作至少之一,以对原始音频数据进行预处理:
97.改变原始音频数据的播放速率;
98.在原始音频数据中添加混响;
99.去除原始音频数据中的噪音;
100.对原始音频数据进行时域通道掩盖操作;
101.对原始音频数据进行频域通道掩盖操作。
102.本实施例中,改变原始音频数据的播放速率,可以是将原始音频的速率调高或者降低。
103.在原始音频数据中添加混响,可以是在原始音频中增加被反射或被吸收的效果。
104.去除原始音频数据中的噪音,可以是去除原始音频数据中的背景音,也可以是将原始音频数据中与情绪分析无关的非背景音进行去除,还可以是从原始音频数据中提取出需要分析的声音作为预处理后的原始音频数据。
105.对原始音频数据进行时域通道掩盖操作,可以是在时域通道上,对原始音频数据进行部分信号消除操作。
106.对原始音频数据进行频域通道掩盖操作,可以是在频域通道上,对原始音频数据进行部分信号消除操作。
107.本实施例,对原始音频进行一定的预处理,从而有助于将一份原始音频数据转化为多份原始音频数据,提高原始音频数据的利用率。
108.在一种实施方式中,基于性别识别结果、情绪识别结果和标注结果,调整待训练的识别模型,包括:
109.基于性别识别结果、情绪识别结果和标注结果进行损失计算,获取损失值;
110.根据损失值,调整待训练的识别模型。
111.本实施例中,基于性别识别结果、情绪识别结果和标注结果进行损失计算,获取损失值,可以包括下述至少之一:
112.基于性别识别结果和关于性别的标注结果,获取第一损失值,将第一损失值作为损失值;
113.基于情绪识别结果和关于情绪的标注结果,获取第二损失值,将第二损失值作为损失值;
114.基于情绪识别结果、关于情绪的标注结果和关于性别的标注结果,获取第三损失值,将第三损失值作为损失值;
115.基于性别识别结果、关于性别的标注结果和关于情绪的标注结果,获取第四损失值,将第四损失值作为损失值;
116.基于性别识别结果和关于性别的标注结果,获取第一损失值;基于情绪识别结果
和关于情绪的标注结果,获取第二损失值,基于第一损失值和第二损失值,获取损失值。
117.本实施例中,能够根据性别识别结果、情绪识别结果和标注结果进行损失计算,从而在优化或调整模型时,能够根据性别和情绪的双重识别结果进行优化,使得模型能够学习到识别性别的最优参数。同时,根据识别性别最优参数和情绪识别结果,使得模型能够学习到识别情绪的最优参数,提高情绪识别的准确性。
118.在一种实施方式中,标注结果包括性别标注结果和情绪标注结果,对基于性别识别结果、情绪识别结果和标注结果进行损失计算,获取损失值,包括:
119.基于性别标注结果和性别识别结果,进行交叉熵损失(cross entropy)计算,获取第一损失值;
120.基于情绪标注结果和情绪识别结果,进行交叉熵损失计算,获取第二损失值;
121.对第一损失值和第二损失值进行加权求和,将求和结果作为损失值。
122.本实施例中,基于性别标注结果和性别识别结果,进行交叉熵损失计算,可以是利用交叉熵损失函数,根据性别识别结果和性别标注结果进行计算。
123.基于情绪标注结果和情绪识别结果,进行交叉熵损失计算,可以是利用交叉熵损失函数,根据情绪识别结果和情绪标注结果进行计算。
124.在一些实施方式中,交叉熵损失可以是典型的交叉熵损失函数;还可以是由典型的交叉熵损失函数推导出的扩展类型的交叉熵损失函数;又可以是二分类的交叉熵损失函数或多分类的交叉熵损失函数。
125.在其它实施方式中,还可以将情绪识别结果和性别识别结果转换为一个融合结果,根据融合结果和标注结果,进行交叉熵损失计算。
126.本实施例中,针对性别识别结果和情绪识别结果分别计算损失值后,根据各自的权重计算总损失值,能够在损失值中融合情绪识别信息和性别识别信息,提高识别结果的准确性。
127.本公开实施例还提供一种情绪识别方法,如图4所示,包括:
128.步骤s41:将待识别的音频数据输入识别模型,得到情绪识别结果,识别模型为本公开任意一项实施例所提供的情绪识别模型。
129.本公开实施例能够应用于智能机器人对话、智能教学、智能客服、心理分析、移动服务等多种场景。例如心理学家可以在会诊过程中,录制患者的语音,后续可根据患者语音得到的音频数据中表达的情绪来设计治疗方案。
130.本公开示例中,采用音频数据中的性别信息,对情绪识别过程进行辅助。具体而言,识别结果中的情绪可以包含基本情绪,也可以包含生活中可能遇到的其它复杂情绪,也可以由训练模型所采用的音频数据的数据集决定。比如,生气、开心、中立、伤心、愤怒、暴怒、暴躁、烦恼、担忧、恐惧、惊讶、胆怯等等。在具体示例中,如图5所示,模型生成方法可以包括如下步骤:
131.步骤s51:构建用于训练识别模型的音频数据集,并对音频数据集进行情绪和性别标注。
132.本实例中,收集一定量(例如,可以是10万)的原始音频数据构建音频数据集,可以对原始音频数据进行情绪信息标注和性别信息标注。
133.步骤s52:音频数据集中的原始音频数据进行预处理。具体可以包括通过去除噪声
静音、分帧等方式进行初步处理,后对初步处理的数据进行数据增强,例如添加混响,改变速率等。
134.在预处理原始音频数据的过程中,可以通过去除环境噪声、忙音、彩铃等信息,得到干净的原始音频数据。
135.步骤s53:对预处理后的原始音频数据进行初级音频特征提取。初级音频特征可以包括基音频率(pitch)、梅尔倒谱(mfcc)、plp、fbank(filter bank,过滤库)、fft(fast fourier transformation,快速傅里叶变换)特征等等。
136.步骤s54:对初级音频特征进行差分增强,将差分增强后的初级音频特征和原始音频数据一起,作为音频数据。
137.具体的,可以对初级音频特征进行二阶差分增强,对数据进行打乱顺序(shuffle)。
138.步骤s55:将音频数据输入待训练的识别模型。
139.在待训练的识别模型中,进行批量(batch)训练,根据音频数据一步一步进行前向计算,将原始音频数据以及初级音频特征不断的映射为高级特征。
140.步骤s56:根据输出层的输出数据计算损失值。
141.在待训练的识别模型最后的输出层,计算情绪识别结果和性别识别结果各自目标的损失。
142.具体的,可以通过控制二者的系数,来确定性别在情绪辨别过程中的影响程度,具体可以采用如下计算公式:
143.l=α
×
l
emotion
+β
×
l
gender
;
144.其中α和β可以为权重值,可以分别设为0.5、0.5。l
emotion
可以为情绪识别损失值,可以根据情绪识别结果和情绪标注结果计算得到,也可以根据情绪识别结果和情绪以及性别标注结果计算得到。l
gender
可以为性别识别结果,可以根据性别识别结果和性别标注结果计算得到。
145.损失计算完毕后,再反向更新整个待训练的识别模型的参数,迭代多轮至收敛,从而得到一个效果稳定的情绪识别模型。
146.步骤s57:模型测试。
147.在测试情绪识别模型的时候,性别的输出可以不用参与计算,音频预处理后,输入到网络,得到最终的情绪分类结果。
148.本公开一种示例中,待训练的识别模型的模型结构可以如图6所示,包括:频谱提取层(spectrum extraction)61、卷积层(convolution neural network,cnn)62、最大池化层(max pooling)63、双向长短期记忆层64、自注意力层(selfattention module)65。此外,待训练的识别模型还可包括情绪输出层(emotion output layer)66和性别输出层(gender output layer)67,由情绪输出层66和性别输出层67构成待训练的识别模型的输出层。情绪与性别识别过程共用了待训练的识别模型中,除输出层之外的所有网络。
149.其中,频谱提取层61的参数可以包括特征维度feature num,取值dspec。卷积层62的参数可以包括过滤维度filter num=dcnn、步长strides、窗口大小window size=ncw,步长取值可以为1。最大池化层63的参数可以包括步长strides=npw、窗口大小,窗口大小可以与步长相等,即可以有:window size=npw。双向长短期记忆层64的参数可以包括隐藏
大小hidden size=dlstm。自注意力层65的参数可以包括隐藏大小hidden size=dattn、头部维度head num=nattn。频谱提取层61输出的信息的维度可以为dspec,卷积层输出的信息维度可以为dcnn,池化层输出的信息的维度可以为dcnn,双向长短期记忆神经网络输出的信息维度可以为2dlstm,自注意力层输出的信息维度可以为2nattn
×
dlstm。
150.本实例中,情绪输出层66的输出结果可以为音频数据包含各种情绪的概率,比如,针对不耐烦、悲伤、高兴、紧张四种情绪,概率分别为{0.0,0.5,0.2,0.3}。性别输出层67的输出结果可以为音频数据的发声者为各种性别的概率,比如,音频数据为男性、女性的概率分别为:{0.9,0.1}。
151.本公开示例中的模型结构中各层的数目,可根据提高情绪识别的准确性的目的进行设置,比如,通过实验发现,设置两层双向lstm层时识别结果准确性增强,则可设置两层双向lstm。再如,通过实际应用发现,设置两层卷积层和/或池化层,识别结果的准确性增强,则可设置两层卷积层和/或池化层。数据可经过第一层双向lstm层的处理后,输入到第二层双向lstm层进行处理。还可以经过第一层卷积层的处理后,输入到第二层卷积层进行处理。还可以经过第一层池化层的处理后,输入到第二层池化层进行处理。
152.本公开实施例提供的模型结构,能够通过性别的信息的学习,去分辨找出不同性别下的情绪特征。通过卷积神经网络层,提高局部信息挖掘效果,通过双向lstm能够更好地刻画长时依赖信息,通过自注意力层能够依据关注的重要性关系进行识别,同时,本实例中,情绪识别与性别识别共用了大部分网络,在分辨情绪的时候,利用了音频数据中间的性别特征,提升了情绪特征之间的差异性,进而本公开实施例提供的情绪识别模型提升了情绪识别的准确率。
153.本公开实施例还提供了一种模型生成装置,如图7所示,包括:
154.识别模块71,用于将音频数据输入待训练的识别模型,获取针对音频数据输出的性别识别结果和情绪识别结果;
155.训练模块72,用于基于性别识别结果、情绪识别结果和标注结果,调整待训练的识别模型,得到情绪识别模型。
156.在一种实施方式中,如图8所示,识别模块包括:
157.第一数据单元81,用于采用待训练的识别模型的前处理层,根据音频数据获取至少融合了情绪信息和性别信息的第一数据;
158.性别识别单元82,用于采用待训练的识别模型的性别识别输出层,根据第一数据获得性别识别结果;
159.情绪识别单元83,用于采用待训练的识别模型的情绪识别输出层,根据第一数据获得情绪识别结果;
160.前处理层为性别识别输出层和情绪识别输出层之前的数据处理层。
161.在一种实施方式中,第一数据单元还用于:
162.对音频数据进行频域信息提取,获取第二数据;
163.对第二数据进行卷积和池化计算,获取第三数据;
164.采用双向长短期记忆神经网络对第三数据进行处理,获取第四数据;
165.对第四数据进行自注意力权值计算,获取第一数据。
166.在一种实施方式中,如图9所示,模型生成装置还包括:
167.预处理模块91,用于对获取到的原始音频数据进行预处理,得到预处理结果;
168.增强模块92,用于对预处理结果进行数据增强操作,获取原始音频数据的增强数据;
169.获取模块93,用于将原始音频数据以及增强数据,作为音频数据。
170.在一种实施方式中,如图10所示,在数据增强操作为差分增强操作的情况下,增强模块包括:
171.音频特征单元101,用于提取原始音频数据的目标音频特征;
172.差分增强单元102,用于对目标音频特征执行差分增强操作,获取原始音频数据的增强数据。
173.在一种实施方式中,如图11所示,预处理模块包括下述至少之一:
174.速率单元111,用于改变原始音频数据的播放速率;
175.混响单元112,用于在原始音频数据中添加混响;
176.噪音单元113,用于去除原始音频数据中的噪音;
177.时域单元114,用于对原始音频数据进行时域通道掩盖操作;
178.频域单元115,用于对原始音频数据进行频域通道掩盖操作。
179.在一种实施方式中,如图12所示,训练模块包括:
180.损失值获取单元121,用于基于性别识别结果、情绪识别结果和标注结果进行损失计算,获取损失值;
181.调整单元122,用于根据损失值,调整待训练的识别模型。
182.在一种实施方式中,标注结果包括性别标注结果和情绪标注结果,损失值单元还用于:
183.基于性别标注结果和性别识别结果,进行交叉熵损失计算,获取第一损失值;
184.基于情绪标注结果和情绪识别结果,进行交叉熵损失计算,获取第二损失值;
185.对第一损失值和第二损失值进行加权求和,将求和结果作为损失值。
186.本公开实施例还提供一种情绪识别装置,如图13所示,包括:
187.情绪识别模块131,用于将待识别的音频数据输入识别模型,得到情绪识别结果,识别模型为本公开任意一项实施例所提供的情绪识别模型。
188.本公开的技术方案通过多任务学习的方式,引入了对情绪识别影响比较大的因素之一,性别的辅助分类,从而来进一步提升情绪特征的提取准确性。
189.本公开实施例可以应用于计算机技术领域,尤其可以应用于自动驾驶、云计算、物联网、大数据、语音技术、智能搜索、信息流、以及深度学习等人工智能技术领域。
190.本公开实施例各装置中的各单元、模块或子模块的功能可以参见上述方法实施例中的对应描述,在此不再赘述。
191.根据本公开的实施例,本公开还提供了一种电子设备、一种可读存储介质和一种计算机程序产品。
192.图14示出了可以用来实施本公开的实施例的示例电子设备140的示意性框图。电子设备旨在表示各种形式的数字计算机,诸如,膝上型计算机、台式计算机、工作台、个人数字助理、服务器、刀片式服务器、大型计算机、和其它适合的计算机。电子设备还可以表示各种形式的移动装置,诸如,个人数字处理、蜂窝电话、智能电话、可穿戴设备和其它类似的计
算装置。本文所示的部件、它们的连接和关系、以及它们的功能仅仅作为示例,并且不意在限制本文中描述的和/或要求的本公开的实现。
193.如图14所示,电子设备140包括计算单元141,其可以根据存储在只读存储器(rom)142中的计算机程序或者从存储单元148加载到随机访问存储器(ram)143中的计算机程序来执行各种适当的动作和处理。在ram 143中,还可存储电子设备140操作所需的各种程序和数据。计算单元141、rom 142以及ram 143通过总线144彼此相连。输入输出(i/o)接口145也连接至总线144。
194.电子设备140中的多个部件连接至i/o接口145,包括:输入单元146,例如键盘、鼠标等;输出单元147,例如各种类型的显示器、扬声器等;存储单元148,例如磁盘、光盘等;以及通信单元149,例如网卡、调制解调器、无线通信收发机等。通信单元149允许电子设备140通过诸如因特网的计算机网络和/或各种电信网络与其他设备交换信息/数据。
195.计算单元141可以是各种具有处理和计算能力的通用和/或专用处理组件。计算单元141的一些示例包括但不限于中央处理单元(cpu)、图形处理单元(gpu)、各种专用的人工智能(ai)计算芯片、各种运行机器学习模型算法的计算单元、数字信号处理器(dsp)、以及任何适当的处理器、控制器、微控制器等。计算单元141执行上文所描述的各个方法和处理,例如模型生成方法。例如,在一些实施例中,模型生成方法可被实现为计算机软件程序,其被有形地包含于机器可读介质,例如存储单元148。在一些实施例中,计算机程序的部分或者全部可以经由rom 142和/或通信单元149而被载入和/或安装到电子设备140上。当计算机程序加载到ram 143并由计算单元141执行时,可以执行上文描述的模型生成方法的一个或多个步骤。备选地,在其他实施例中,计算单元141可以通过其他任何适当的方式(例如,借助于固件)而被配置为执行模型生成方法。
196.本文中以上描述的系统和技术的各种实施方式可以在数字电子电路系统、集成电路系统、场可编程门阵列(fpga)、专用集成电路(asic)、专用标准产品(assp)、芯片上系统的系统(soc)、负载可编程逻辑设备(cpld)、计算机硬件、固件、软件、和/或它们的组合中实现。这些各种实施方式可以包括:实施在一个或者多个计算机程序中,该一个或者多个计算机程序可在包括至少一个可编程处理器的可编程系统上执行和/或解释,该可编程处理器可以是专用或者通用可编程处理器,可以从存储系统、至少一个输入装置、和至少一个输出装置接收数据和指令,并且将数据和指令传输至该存储系统、该至少一个输入装置、和该至少一个输出装置。
197.用于实施本公开的方法的程序代码可以采用一个或多个编程语言的任何组合来编写。这些程序代码可以提供给通用计算机、专用计算机或其他可编程数据处理装置的处理器或控制器,使得程序代码当由处理器或控制器执行时使流程图和/或框图中所规定的功能/操作被实施。程序代码可以完全在机器上执行、部分地在机器上执行,作为独立软件包部分地在机器上执行且部分地在远程机器上执行或完全在远程机器或服务器上执行。
198.在本公开的上下文中,机器可读介质可以是有形的介质,其可以包含或存储以供指令执行系统、装置或设备使用或与指令执行系统、装置或设备结合地使用的程序。机器可读介质可以是机器可读信号介质或机器可读储存介质。机器可读介质可以包括但不限于电子的、磁性的、光学的、电磁的、红外的、或半导体系统、装置或设备,或者上述内容的任何合适组合。机器可读存储介质的更具体示例会包括基于一个或多个线的电气连接、便携式计
算机盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦除可编程只读存储器(eprom或快闪存储器)、光纤、便捷式紧凑盘只读存储器(cd
‑
rom)、光学储存设备、磁储存设备、或上述内容的任何合适组合。
199.为了提供与用户的交互,可以在计算机上实施此处描述的系统和技术,该计算机具有:用于向用户显示信息的显示装置(例如,crt(阴极射线管)或者lcd(液晶显示器)监视器);以及键盘和指向装置(例如,鼠标或者轨迹球),用户可以通过该键盘和该指向装置来将输入提供给计算机。其它种类的装置还可以用于提供与用户的交互;例如,提供给用户的反馈可以是任何形式的传感反馈(例如,视觉反馈、听觉反馈、或者触觉反馈);并且可以用任何形式(包括声输入、语音输入、或者触觉输入来接收来自用户的输入。
200.可以将此处描述的系统和技术实施在包括后台部件的计算系统(例如,作为数据服务器)、或者包括中间件部件的计算系统(例如,应用服务器)、或者包括前端部件的计算系统(例如,具有图形用户界面或者网络浏览器的用户计算机,用户可以通过该图形用户界面或者该网络浏览器来与此处描述的系统和技术的实施方式交互)、或者包括这种后台部件、中间件部件、或者前端部件的任何组合的计算系统中。可以通过任何形式或者介质的数字数据通信(例如,通信网络)来将系统的部件相互连接。通信网络的示例包括:局域网(lan)、广域网(wan)和互联网。
201.计算机系统可以包括客户端和服务器。客户端和服务器一般远离彼此并且通常通过通信网络进行交互。通过在相应的计算机上运行并且彼此具有客户端
‑
服务器关系的计算机程序来产生客户端和服务器的关系。
202.应该理解,可以使用上面所示的各种形式的流程,重新排序、增加或删除步骤。例如,本公开中记载的各步骤可以并行地执行也可以顺序地执行也可以不同的次序执行,只要能够实现本公开公开的技术方案所期望的结果,本文在此不进行限制。
203.上述具体实施方式,并不构成对本公开保护范围的限制。本领域技术人员应该明白的是,根据设计要求和其他因素,可以进行各种修改、组合、子组合和替代。任何在本公开的精神和原则之内所作的修改、等同替换和改进等,均应包含在本公开保护范围之内。