两阶段的用户可定制唤醒词检测
1.相关申请
2.本技术要求于2020年5月6日提交的美国临时专利申请第63/020,984号的优先权,该美国临时专利申请的全部公开内容特此被并入本文。
技术领域
3.本公开总体上涉及语音识别系统,并且更具体地涉及唤醒词检测。
背景技术:
4.越来越多的现代计算设备以语音识别能力为特征,允许用户经由话音命令和自然语音执行各种各样的计算任务。诸如移动电话或智能扬声器之类的设备提供集成虚拟助理,这些集成虚拟助理可以通过在局域网和/或广域网上通信来响应于用户的命令或自然语言请求,以取回被请求的信息或者控制其它设备,例如灯、暖气和空调控制、音频或视频装备等。具有语音识别能力的设备通常保持在低功耗模式下,直到说出了特定词或短语(即,唤醒词或唤醒短语),从而允许用户在设备因此被激活之后使用话音命令来控制设备。
5.为了发起基于话音的用户接口,通常会部署唤醒词检测(wwd)。这里,关键词或关键短语被连续地监测,并且当被检测到时,启用进一步的基于话音的交互。早期的wwd系统将高斯混合模型
‑
隐马尔可夫模型(gmm
‑
hmm)用于声学建模。最近,深度学习或深度神经网络(nn)由于其比传统方法更高的准确性而已经成为一种有吸引力的选择。
附图说明
6.本实施例在附图的图中通过示例而非限制的方式被示出。
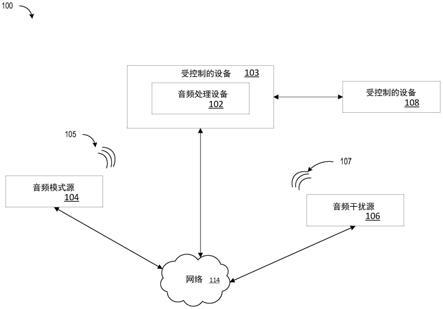
7.图1是示出根据本公开的一些实施例的系统的框图。
8.图2是示出根据本公开的一些实施例的音频处理设备的框图。
9.图3a
‑
3c示出了根据本公开的一些实施例的唤醒词识别模型推导过程。
10.图3d示出了根据本公开的一些实施例的传统唤醒词识别过程。
11.图4a示出了根据本公开的一些实施例的2阶段模型训练和2阶段唤醒词识别过程。
12.图4b示出了根据本公开的一些实施例的唤醒词识别模型。
13.图5示出了根据本公开的一些实施例的各种发声的状态序列的图。
14.图6示出了根据本公开的一些实施例的用于识别唤醒词的方法的流程图。
15.图7示出了根据本公开的一些实施例的用于识别唤醒词的方法的流程图。
16.图8示出了根据本公开的一些实施例的用于识别唤醒词的方法的流程图。
17.图9示出了可编程片上系统()处理设备的核心架构的实施例。
具体实施方式
18.在以下描述中,出于解释的目的,阐述了许多具体细节,以便提供对本实施例的透彻理解。然而,对于本领域的技术人员来说将显而易见的是,可以在没有这些具体细节的情
况下实践本实施例。在其它实例中,公知的电路、结构和技术没有被详细地示出,而是在框图中示出,以便避免不必要地模糊对此描述的理解。
19.在说明书中对“一个实施例”或“实施例”的引用意味着结合该实施例描述的特定的特征、结构或特性被包括在至少一个实施例中。位于本说明书中的各个位置中的短语“在一个实施例中”不一定是指相同的实施例。
20.如上面所讨论的,为了使用唤醒词来发起设备,通常利用唤醒词检测(wwd)。大多数方法都采用无法被用户修改的预先选定的唤醒词(例如,“hello”),并且需要数以万计的后端训练发声。这些预先选定的唤醒词是离线训练的,并且针对所有说话人奏效,并且因此,是与说话人无关的。唤醒词的检测可以在设备上被本地执行,并且然后可以在云中由更复杂的算法验证。说话人识别是一项附加功能,其可以提供某种程度的安全性或定制化(例如,用户特定的播放列表)。然而,说话人识别是一项复杂的任务,其通常在云中执行,并且需要繁琐的注册阶段(阅读文本)。
21.许多个人设备(例如,耳机、可听设备、可穿戴设备、照相机等)现在都以话音接口为特征。这些设备通常由很少的或者甚至单个用户使用。由于它们是电池供电的,因此到云的连接性受到限制,以节省电力。因此,期望功能保持在本地。尽管如此,诸如唤醒词检测和说话人识别之类的特征是期望的,这是由于免提是对于许多这些产品的重要优势。用于实现这些目标的一种方法是启用用户个性化的唤醒词。通过让用户训练他们自己的(或者可替代地几个说话人共享训练相同的)唤醒词,它变得依赖于说话人,并且因此被优化以供特定说话人或少数说话人使用。由于这些设备是由少数或者甚至单个用户使用的,因此与说话人无关不一定是一项要求。另外,唤醒词的定制化固有地识别用户,并且用户可定制的唤醒词的保密性提供了安全性级别,而不需要显式和代价高昂的说话人识别。然而,用尽可能少的训练发声来实现这种系统是有挑战性的。
22.与传统方法相比,深度学习或深度神经网络(nn)由于其提高的准确性而已经成为一种有吸引力的选择。然而,这些系统是针对固定的或给定的唤醒词(例如,“hello”)进行离线训练的。它们需要数以千计的说话人重复数以万计的发声。一些解决方案确实提供了一种在以后适应于用户的话音的选项(注册阶段,或基于使用的适应),但是通常不展示出仅利用少量训练发声来训练任意唤醒词(用户可定制的)的能力。其它可用的解决方案(例如,孤立词训练和检测)遭受对“欺骗”短语的敏感性的问题,所述“欺骗”短语与唤醒词共享重要音素(或构建块声音)。的确,这样的系统易在类似发音词的情况下遭受相对高程度的错误检测。
23.本文所描述的实施例针对用于从发出的语音中检测唤醒词的设备、方法和系统。处理设备可以确定用于使用训练发声集合基于似然比来进行唤醒词识别的第一模型。发声集合可以由第一模型分析以确定第二模型,该第二模型包括训练发声集合中的每一个的训练状态序列,并且其中,每个训练状态序列指示对应训练发声的每个时间间隔的可能状态。可以基于第一模型和第二模型的连结来确定检测到的发声是否对应于唤醒词。更具体地,处理设备可以测量每个训练状态序列和检测到的发声的状态序列之间的距离,以生成距离集合,并且可以确定该距离集合之中的最小距离。处理设备可以至少部分地基于检测到的发声的似然比和距离集合之中的最小距离,来确定检测到的发声是否对应于唤醒词。
24.图1是根据各种实施例的系统100的框图,其示出了通过一个或多个网络114通信
地耦合到其它设备的音频处理设备102。音频处理设备102用于促进音频模式识别,并且可以基于经识别的音频模式来控制诸如设备103之类的设备或应用。音频处理设备102被示为接收来自音频模式源104的声波105和来自音频干扰源106的声波107。音频处理设备102本身可以发射音频干扰(未示出)(例如,通过扬声器)。
25.音频处理设备102还被示出通过通信链路与网络114交互。为了促进模式识别,音频处理设备102使用通过网络114从音频干扰源106接收的或内部生成的对应音频数据,来提供噪声消除以移除音频干扰中的一些或全部。在实施例中,可以使用独立分量分析(ica)来实现噪声消除,其中,传入信号(例如,来自麦克风)按源(例如,来自音频模式源和音频干扰源的信号)进行分离,然后将音频数据与分离的信号进行比较,以确定哪些信号应当被移除以留下经估计的音频模式。其它实施例中的噪声消除可以利用自适应滤波器、神经网络、或可以用于使信号的非目标分量衰减的本领域中已知的任何技术。在一些实施例中,音频处理设备102可以与受控制的设备103集成,该受控制的设备可以基于经识别的音频模式来控制。
26.音频模式源104用于提供对应于可识别音频模式(例如,唤醒词)的声波105。在一些实施例中,音频模式源104可以通过通信链路与网络114交互。在一些实施例中,音频模式是预定音频模式和/或可由与音频处理设备102相关联的模式识别软件或固件识别的音频模式。音频模式源104可以是有生命的对象(例如,人)或无生命的对象(例如,机器)。
27.音频干扰源106可以是声波107的源,其干扰对应于声波105的音频模式的识别。音频干扰源106被示为通过通信链路与网络114交互。音频干扰源106可以通过网络114来向音频处理设备102提供对应于音频干扰的音频数据。音频干扰源可以包括扬声器、电视机、视频游戏、工业噪声源、或任何其它噪声源,其声音输出被数字化或可以被数字化并且经由网络114被提供给音频处理设备102。
28.受控制的第二设备108被示为经由链路耦合到网络114。受控制的设备108和103可以包括具有以下功能的任何设备:其可以响应于由音频处理设备102促进的音频模式识别而被发起。示例性的受控制的设备包括白色家电、家庭自动化控制器、恒温控制器、照明设备、自动百叶窗、自动门锁、汽车控制、窗户、工业控制和制动器。如本文所使用的,受控制的设备可以包括由受控制的设备110运行的任何逻辑、固件、或软件应用。
29.网络114可以包括一种或多种类型的有线和/或无线网络,以用于将图1的网络节点彼此通信地耦合。例如,但不限于,网络可以包括无线局域网(wlan)(例如,wi
‑
fi,符合802.11的)、pan(例如,蓝牙sig标准或zigbee,符合ieee 802.15.4的)、以及互联网。在实施例中,音频处理设备102通过wi
‑
fi和互联网来被通信地耦合到模式识别应用112。音频处理设备102可以通过蓝牙和/或wi
‑
fi来被通信地耦合到音频干扰源106和受控制的设备108。
30.图2是示出根据实施例的音频处理设备202的组件的框图。音频处理设备202可以是由加利福尼亚州圣何塞的赛普拉斯半导体公司开发的cypress psoc系列的微控制器。音频处理设备202被示为包括功能块,这些功能块包括麦克风阵列220、音频接口221、阈值计算模块222、语音起始检测器sod 223、音频接口控件224、缓冲器225、组合器226、以及中央处理单元(cpu)228。每个功能块可以被耦合到总线系统227(例如,i2c、i2s),并且可以使用硬件(例如,电路)、指令(例如,软件和/或固件)、或者硬件和指令的组合来实现。在一个实施例中,音频处理设备202中的一些或全部由集成电路设备(即,在单个集成电路基板上)或
单个设备封装中的电路实现。在替代实施例中,音频处理设备202的组件被分布在多个集成电路设备、设备封装、或其它电路中。
31.麦克风阵列220用于接收诸如图1的声波105和107之类的声波。麦克风阵列220中的每个麦克风包括换能器或其它机制(例如,包括振膜),以将声波的能量转换成电子信号或数字信号(例如,音频数据)。麦克风阵列220可以包括一个或多个麦克风,并且在本文中有时被称为麦克风220。当在公共周期期间接收到声波105和107时,音频数据包括对应于声波105和107二者的分量。在一些实施例中,阵列220的一个或多个麦克风可以是数字麦克风。麦克风阵列220可以是音频接口221的一部分,或者是在音频处理设备202外部但是被耦合到总线系统227的单独外围设备。在一些实施例中,麦克风阵列可以包括用于活动检测和测量的阈值/迟滞设置和/或处理逻辑,以确定由麦克风阵列220接收到的声波是否满足或超过激活阈值,以及是否应当将对应的音频数据传递给sod 223以用于处理。在各种实施例中,活动的阈值水平可以是声波的能量水平、幅度、频率、或任何其它属性。麦克风阵列220可以被耦合到存储激活阈值的存储器(未示出),该激活阈值可以是动态地可重新编程的(例如,通过阈值计算模块222)。
32.音频接口221包括用于处理和分析从麦克风阵列220接收的音频数据的电路。在实施例中,音频接口221将电子音频信号数字化。一旦被数字化,音频接口221就可以提供信号处理(例如,解调、混频、滤波)以分析或操纵音频数据的属性(例如,相位、波长、频率)。音频接口221还可以执行波束形成和/或其它噪声抑制或信号调节方法,以提高在存在噪声、混响等的情况下的性能。
33.在一个实施例中,音频接口221包括被连接到麦克风阵列220的脉冲密度调制器(pdm)前端。在pdm前端中,pdm基于来自麦克风阵列220的电子信号来生成脉冲密度调制的比特流。pdm向麦克风220提供确定初始采样率的时钟信号,然后从麦克风220接收表示从环境捕获的音频的数据信号。根据数据信号,pdm生成pdm比特流,并且可以将比特流提供给抽取滤波器,该抽取滤波器可以通过提供高质量音频数据或者通过将来自pdm的脉冲密度调制比特流的采样率降低到低质量音频数据,来生成被提供给总线系统227的音频数据。在替代实施例中,音频数据源是辅助模数转换器(aux adc)前端。在辅助adc前端中,模数转换器将来自麦克风220的模拟信号转换为数字音频信号。数字音频信号可以被提供给抽取滤波器,以通过提供高质量音频数据或者通过将来自adc的数字音频信号的采样率降低到低质量音频数据,来生成被提供给总线系统227的音频数据。
34.音频接口控件224用于控制音频接口221或麦克风阵列220的采样定时和音频接口221或麦克风阵列220的采样的采样率。例如,音频接口控件224可以控制被提供给sod 223和缓冲器225的音频数据的音频质量(例如,采样率),并且还可以控制应当被周期性地或连续地提供给总线系统227的这种音频数据的时间。尽管被示为单独的功能块,但是音频接口控件224的功能可以由sod 223和/或缓冲器225或任何其它功能块来执行。
35.sod 223用于确定从音频接口221接收的音频数据是否是语音起始。sod 223可以使用本领域的普通技术人员已知的任何语音起始检测算法或技术。在实施例中,具有降低的采样率(例如,2
‑
4khz)的音频数据足以用于检测语音起始(或其它声音起始事件),同时允许sod 223以较低的频率被计时,因此降低sod 223的功耗和复杂性。在检测到语音起始事件时,sod 223断言总线227上的状态信号,以将唤醒短语检测器(wupd)228从低功耗状态
(例如,睡眠状态)唤醒到高功耗状态(例如,活动状态),以执行短语检测,如下面将进一步讨论的。以这种方式对wupd 228块的选通通过使wupd 228所考虑的背景噪声和杂散音频最小化,来降低平均系统处理负载并降低错误接受率(far)。
36.阈值计算模块222监测环境噪声以动态地计算并潜在地重新调整应当触发语音起始检测的音频的激活阈值,以避免由sod 223进行不必要的处理。在实施例中,音频接口控件224使得音频接口221以间隔周期性地向阈值计算模块222提供音频数据(例如,环境噪声)。在实施例中,阈值计算模块222可以将激活阈值水平从低于当前环境噪声水平重置到高于当前环境噪声水平。
37.缓冲器225用于存储周期性采样的主要噪声音频数据。在实施例中,缓冲器225被调整大小以存储略大于250毫秒的音频数据(例如,253毫秒),以容纳如下所讨论的组合。可替代地,或者另外地,在sod 223已经检测到语音起始之后,缓冲器225可以充当信道,以传递包括唤醒短语和命令或查询的连续采样的音频数据。在实施例中,音频接口控件224使得音频接口221以间隔周期性地向缓冲器225提供主要噪声。一旦sod 223已经检测到类似语音的声音,音频接口控件224就可以使得音频接口221连续地向缓冲器提供剩余的音频数据。
38.组合器226用于使用周期性捕获的主要噪声和连续捕获的剩余音频数据来生成连续的音频数据。在实施例中,组合器226将最后周期性捕获的音频数据的结尾的一部分与连续捕获的音频数据的开头的一部分缝合。例如,组合器226可以使用重叠加法运算来将3毫秒的主要噪声与连续捕获的音频数据进行重叠。组合器226可以经由总线系统227将连续音频数据输出到wupd 228。
39.wupd 228可以确定由组合器226输出的连续音频数据是否包括唤醒词或唤醒短语。当wupd 228被激活时,它可以执行更高复杂性和功率更高的计算(例如,相对于sod 223),以确定是否已经说出唤醒词或短语,如关于图3a
‑
8进一步详细讨论的。wupd 228可以基于记录在缓冲器225中的音频数据(对应于语音起始之前的时间)和检测到语音起始之后接收到的高质量音频数据来进行此确定。
40.图3a示出了传统的高斯马尔可夫模型
‑
隐马尔可夫模型(gmm
‑
hmm)唤醒词或词辨别方法300的图,其中,使用诸如最大似然前向
‑
后向算法之类的任何适当算法来训练每个唤醒词的整词模型。高斯观察模型是通过使用对角结构或全协方差结构来确定的,其中,对角结构是主要的方法。词模型可以包括状态的“从左到右”线性序列,其中每个音素有例如大约三个状态。观察向量o是通过前端谱分析获得的,其中,mel
‑
频率倒谱系数(mfcc)及其导数是最常见的。在标准训练方法中,在离线训练中使用数十到数百个唤醒词的发声来产生最终词模型,如图3a所描绘的。在解码期间,用户可能希望在给定模型λ的情况下计算观察序列o=o1o2…
o
t
的概率,即,p(o|λ)。可以使用任何适当的算法(例如,viterbi算法)来执行此计算。
41.图3b示出了基于音素的训练方法310,其中,个体音素被离线训练以创建音素数据库。结果发现,大约50个最常见的音素的集合就足够了,其中,每个音素用3个hmm状态和每状态2个高斯混合进行模拟。在唤醒词训练期间,用户会发出几次(例如,1
‑
3次)定制的唤醒词。在图3c所示的后续训练过程中使用这些发声以及可选地扩充集合。
42.如图3c所示,音素识别块315用于确定所发出的唤醒词“abracadabra”的最可能的
音素分解,如图3c所示。检测到的音素的模型然后用于:使用基于音素转录的连结音素模型(发出的短语的每个实例有一个转录)来为唤醒词构建初始的基于词的模型λ1。
43.随后,可以再次利用训练发声来调整初始词模型以适应说话人,捕获音素间的依赖性,并且降低连结模型维数。此训练将与说话人无关的基于连结音素的模型提炼为依赖于说话人的基于词的模型。修剪和状态组合也发生在适应期间,以减小模型的大小,也如图3c所示。状态组合涉及两个或更多个类似的或相同的状态的合并,这些状态之间的转换可能性非常高。在图3c的示例中,对应于“r”和“r”的初始hmm词模型的第3和第4状态可以被组合成单个“r”状态,并且对应于“e”“r”和“r”的初始hmm词模型的状态11
‑
13可以被组合成单个“r”状态。
44.在标准方法中,一旦模型被获得,就使用它来评估语音观察结果(o)(在本文中也被称为发声),并且如果已经检测到观察序列的概率超过由概率(给定垃圾或背景模型λ
g
)标准化的阈值th(给定模型λ1),则检测到唤醒词。此过程在图3d中被描述。
45.似然比lr被定义为:
[0046][0047]
换言之,lr可以基于:与观察结果o与垃圾模型λ
g
的匹配多么接近相比,观察结果o与模型λ1的匹配程度。然而,此方法除了最终概率之外,不捕获有关λ1如何建模o的任何信息。在许多情况下,错误接受的词可能展示出部分音素匹配,或者包含完全匹配的音素子集。这种发声通常具有非常高的lr,这是因为所有的因素匹配并且保持了元音。在此实例中,仅仅依赖于lr将引起错误的接受。另一种常见的错误接受场景是词与唤醒词的一部分匹配。本公开的实施例通过以下方式来克服上述问题:将模型如何在输入观察序列的整个持续时间内被内部激发并入模型训练和决策过程中。在hmm
‑
gmm模型的情况下,一个这种激发是最可能的状态。
[0048]
图4a示出了根据本公开的一些实施例的模型生成训练方法。在获得了模型λ1(如上文关于图3b
‑
3d所讨论的)时,音频处理设备202可以通过利用模型λ1处理训练发声来进行训练的第二阶段,以针对每个训练发声获得状态序列,该状态系列指示在训练发声的过程期间在每个时间间隔处的最可能的状态(例如,特定的音素模型),其将形成阶段2模型λ2的基础。例如,每个训练发声可以持续420毫秒,并且可以以10毫秒帧(例如,10毫秒时间间隔)捕获。状态序列可以指示在发声的每个特定的帧处(例如,当我们通过模型转换时)训练发声将处于的最可能的状态(例如,特定的音素模型)。如图4b所示,模型λ1可以是以10毫秒时间间隔在420ms期间捕获的11状态模型。图4b还示出了每个状态的变化的时间长度。如图4b的示例所示,除了被示出持续30ms的第4状态(“a”)之外,每个状态可以持续20ms。状态序列可以指示在每个时间间隔保持在当前状态中或转换到新状态的可能性。
[0049]
返回参考图4a,音频处理设备202可以在时间t处求解n状态模型λ1中的个体地最可能的状态q
t
,如下所示:
[0050][0051]
如果u
k
是k个总训练发声中的第k个训练发声,并且是对应的观察序列,则音频
处理设备202可以在训练期间确定每个训练发声u
k
的最可能状态序列,如下所示:
[0052][0053]
音频处理设备202可以通过收集k个训练发声中的每一个的状态序列来创建第二阶段模型λ2:
[0054][0055]
音频处理设备202可以然后通过连结阶段1和阶段2(λ1和λ2)模型来生成最终模型λ:
[0056]
λ={λ1,λ2}
[0057]
尽管模型λ2是如上所描述获得的,但是可以使用任何适当的方法。例如,音频处理设备202可以利用统计方法来获得每个状态随时间的总和分布。图4a还示出了根据本公开的一些实施例的2阶段识别过程。音频处理设备202可以使用模型λ1(例如,基于lr)结合模型λ2来执行对检测到的发声的识别。例如,在使用模型λ1做出了识别决策时,音频处理设备202可以随后使用模型λ2验证使用模型λ1识别的结果。为了验证,音频处理设备202可以确定k个状态序列中的每一个与检测到的发声(例如,在被识别的发声)的状态序列之间的距离,从而生成k个距离,并且确定k个距离之中的最小距离,其被计算如下:
[0058][0059]
音频处理设备202可以将此最小距离测量合并到最终决策中:
[0060]
final decision=f(dqmin
u
,lr(o,λ1,λ
g
))
[0061]
音频处理设备202可以将dqmin
u
与阈值进行比较,并且如果dqmin
u
超过阈值,则它确定检测到的发声不是唤醒词。在一些实施例中,音频处理设备202可以将权重指派给dqmin
u
,使得它基于例如用户偏好对最终决策具有较多或较少的影响。应当注意的是,尽管上述示例是关于dqmin
u
和lr(o,λ1,λ
g
)的使用进行描述的,以确定检测到的发声是否对应于唤醒词,但是在一些实施例中,音频处理设备202可以在确定检测到的发声是否对应于唤醒词时仅利用模型λ2(例如,仅dqmin
u
)。
[0062]
图5示出了各种不同的发声的状态序列。针对“abracadabra”的训练发声中的一个的参考被标记为“参考”。“参考”可以对应于具有距正被识别的发声的状态序列的最小距离(dqmin
u
)的训练发声。与训练发声(例如,“abracadabra”)相同的识别唤醒词被标记为“ww”并且很好地跟随“参考”状态序列,如图所示。与训练发声相同但是受噪声影响的另一个唤醒词被标记为“ww
‑
噪声”。如可以看出的,“ww
‑
噪声”展示出一些微小的状态不匹配,但是总体上仍然很好地跟随“参考”的状态序列。在噪声环境中,lr通常比在安静环境中低,而状态序列仅展示出距离得分的微小增加,因此增强了在噪声环境中的检测能力。
[0063]
在许多情况下,错误接受词可能展示出部分音素匹配,或者包含完全匹配的音素子集。例如,发声“abraaaaaaaaaaaaabra”在图5中示出并且被标记为“abraaaaaaaaaaaaabra”。在这种情况下,“abraaaaaaaaaaaaabra”的状态序列在开头匹配良好,但是然后被保持在表示“a”的状态周围。状态序列在接近发声结尾处再次匹配良好。这种发声通常有非常高的lr,这是因为所有的因素匹配并且保持了元音。在此实例中,仅仅
依赖于lr可能引起错误接受。然而,使用dqmin
u
示出了在帧30
‑
63处的“abraaaaaaaaaaaaabra”的状态序列和帧30
‑
63处的“参考”的状态序列之间存在相当大的距离。因此,音频处理设备202可以拒绝发声“abraaaaaaaaaaaaabra”。另一种常见的错误接受场景是该发声匹配唤醒词的一部分。这通过图5中被标记为“updowncadabra”的状态序列来示出。“updowncadabra”的状态序列的不匹配部分在对应的帧处展示出与“参考”的状态序列的不良匹配,从而引起高距离得分和拒绝。最终地,被标记为“加利福尼亚”的完全不匹配的发声被示出。这种发声除了全程不佳地跟随“参考”的状态序列之外,还将可能地展示出非常低的lr。
[0064]
在一些实施例中,替代或附加于在k个状态序列中的每一个与正被识别的发声的状态序列之间的距离测量,模型λ2可以基于其它参数。一个这种参数可能是似然比lr如何随着每次观察结果o
t
而随时间演变。在获得了模型λ1时(如上面关于图3b
‑
3d所讨论的),音频处理设备202可以通过利用模型λ1处理训练发声u
k
来进行训练的第二阶段,以确定每个训练发声的似然比lr如何随着每个观察结果o
t
而随时间演变。在给定观察序列o
t
=o1,
…
,o
t
和模型λ1的情况下,在时间t处处于状态s
i
的概率由下式给出:
[0065]
γ
t
(i,o
t
,λ1)=p(q
t
=s
i
|o
t
,λ1)
[0066]
在时间t处,在模型λ1内的任何状态下的最大概率然后由下式给出:
[0067][0068]
然后,处理每个训练发声u
k
给出:
[0069][0070][0071]
并且因此,音频处理设备202可以将训练发声随时间的似然比(lr)确定为:
[0072][0073]
音频处理设备202可以然后生成第二阶段模型λ2,如下所示:
[0074][0075]
在对接收到的发声的识别期间,音频处理设备202可以计算每个和lr
t
之间的距离测量d(表示接收到的发声随时间的似然比),以生成k个距离量度(measure)。音频处理设备202可以然后使用在所有k个距离量度之中(例如,在所有训练发声之中)的最小距离dmin
u
连同似然比lr(o,λ1,λ
g
),以计算最终决策:
[0076][0077]
final decision=f(dmin
u
,lr(o,λ1,λ
g
))
[0078]
音频处理设备202可以将dmin
u
与阈值进行比较,并且如果dmin
u
超过阈值,则它确定检测到的发声不是唤醒词。在一些实施例中,音频处理设备202可以将权重指派给dmin
u
,使得其基于例如用户偏好对最终决策具有较多或较少的影响。在一些实施例中,音频处理设备202可以将上面讨论的两个阶段2识别参数合并到最终决策中:
[0079]
final decision=f(dqmin
u
,dmin
u
,lr(o,λ1,λ
g
))
[0080]
替代或附加于随时间的似然比和状态序列,也可以使用其它参数。这样的参数的示例可以包括发音量度、音调、以及帧能量,等等。另外,模型λ1和λ2可以不限于hmm
‑
gmm模型,但是还可以包括神经网络或任何其它适当的模型类型。
[0081]
图6是根据一些实施例的检测唤醒词的方法600的流程图。方法600可以通过处理逻辑来执行,该处理逻辑可以包括硬件(例如,电路、专用逻辑、可编程逻辑、处理器、处理设备、中央处理单元(cpu)、片上系统(soc)等)、软件(例如,在处理设备上运行/执行的指令)、固件(例如,微码)、或其组合。例如,方法600可以由执行唤醒词检测固件的音频处理设备202来执行。
[0082]
还参考图2,在框605处,音频处理设备202可以确定被配置为基于训练发声集合来识别唤醒词的第一模型。在框610处,音频处理设备202可以使用第一模型来分析训练发声集合以确定第二模型,该第二模型包括训练发声集合中的每一个的训练状态序列,并且其中,每个训练状态序列指示对应训练发声的每个时间间隔的可能状态。在框615处,音频处理设备202可以确定检测到的发声的状态序列,该状态序列指示检测到的发声的每个时间间隔的可能状态。在框620处,音频处理设备202可以确定每个训练状态序列和检测到的发声的状态序列之间的距离,以生成距离集合。在框625处,至少部分地基于检测到的发声的似然比和距离集合之中的最小距离,来确定检测到的发声是否对应于唤醒词。
[0083]
图7是根据一些实施例的用于检测唤醒词的方法700的流程图。方法700可以通过处理逻辑来执行,该处理逻辑可以包括硬件(例如,电路、专用逻辑、可编程逻辑、处理器、处理设备、中央处理单元(cpu)、片上系统(soc)等)、软件(例如,在处理设备上运行/执行的指令)、固件(例如,微码)、或其组合。例如,方法700可以由执行唤醒词检测固件的音频处理设备202来执行。
[0084]
同时参考图2,在框705处,音频处理设备202可以确定被配置为基于训练发声集合来识别唤醒词的第一模型。在框710处,音频处理设备202可以使用第一模型来分析训练发声集合以确定第二模型,该第二模型包括对每个训练发声的随时间的似然比的指示。在框715处,音频处理设备202可以确定检测到的发声的随时间的似然比,并且在框720处可以确定每个训练发声的随时间的似然比和检测到的发声的随时间的似然比之间的距离,以生成距离集合。在框725处,音频处理设备202可以至少部分地基于检测到的发声的似然比和距离集合之中的最小距离,来确定检测到的发声是否对应于唤醒词。
[0085]
图8是根据一些实施例的用于检测唤醒词的方法800的流程图。还参考图2,在框805处,音频处理设备202可以确定被配置为基于训练发声集合来识别唤醒词的第一模型。在框810处,音频处理设备202可以使用第一模型来分析训练发声集合,以确定第二模型,该第二模型包括训练发声集合中的每一个的训练状态序列,并且其中,每个训练状态序列指示对应训练发声的每个时间间隔的可能状态。第二模型可以进一步包括对每个训练发声的随时间的似然比的指示。在框815处,音频处理设备202可以确定检测到的发声的状态序列,该状态序列指示检测到的发声的每个时间间隔的可能状态。音频处理设备202可以进一步确定检测到的发声的随时间的似然比。在框820处,音频处理设备202可以确定每个训练状态序列和检测到的发声的状态序列之间的距离,以生成第一距离集合。音频处理设备202可以进一步确定每个训练发声的随时间的似然比和检测到的发声的随时间的似然比之间的
距离,以生成第二距离集合。在框825处,音频处理设备202可以至少部分地基于检测到的发声的似然比、第一距离集合之中的最小距离(dqmin
u
)、以及第二距离集合之中的最小距离(dmin
u
),来确定检测到的发声是否对应于唤醒词。
[0086]
图9示出了处理设备的核心架构900的实施例,例如由赛普拉斯半导体公司(加利福尼亚州圣何塞)提供的系列产品中使用的核心架构900。在一个实施例中,核心架构900包括微控制器1102。微控制器1102包括cpu(中央处理单元)核心1104(其可以对应于图1的处理设备130)、闪存程序存储装置1106、doc(片上调试)1108、预取缓冲器1110、专用sram(静态随机存取存储器)1112、以及特殊功能寄存器1114。在实施例中,doc 1108、预取缓冲器1110、专用sram 1112、以及特殊功能寄存器1114被耦合到cpu核心1104(例如,cpu核心1006),而闪存程序存储装置1106被耦合到预取缓冲器1110。
[0087]
核心架构1100还可以包括chub(核心集线器)1116,包括经由总线1122耦合到微控制器1102的桥接器1118和dma控制器1120。chub 1116可以提供以下二者之间的主要数据和控制接口:微控制器1102及其外围设备(例如,外设)和存储器;以及可编程核心1124。dma控制器1120可以被编程为在系统元件之间传送数据而不加重cpu核心1104的负担。在各种实施例中,微控制器1102和chub 1116的这些子组件中的每一个可以与cpu核心1104的每个选择或类型不同。chub 1116还可以被耦合到共享sram 1126和spc(系统性能控制器)1128。专用sram 1112独立于由微控制器1102通过桥接器1118访问的共享sram 1126。cpu核心1104在不通过桥接器1118的情况下访问专用sram 1112,因此允许本地寄存器和ram访问与对共享sram 1126的dma访问同时发生。尽管这里被标记为sram,但是在各种其它实施例中,这些存储器模块可以是任何合适类型的各种(易失性或非易失性)存储器或数据存储模块。
[0088]
在各种实施例中,可编程核心1124可以包括子组件(未示出)的各种组合,包括但不限于数字逻辑阵列、数字外围设备、模拟处理信道、全局路由模拟外围设备、dma控制器、sram和其它适当类型的数据存储装置、io端口、以及其它合适类型的子组件。在一个实施例中,可编程核心1124包括gpio(通用io)和emif(扩展存储器接口)块1130(用于提供扩展微控制器1102的外部片外访问的机制)、可编程数字块1132、可编程模拟块1134、以及特殊功能块1136,均被配置为实现子组件功能中的一个或多个。在各种实施例中,特殊功能块1136可以包括专用(非可编程的)功能块和/或包括到专用功能块的一个或多个接口,例如usb、晶体振荡器驱动器、jtag等。
[0089]
可编程数字块1132可以包括数字逻辑阵列,该数字逻辑阵列包括数字逻辑块阵列和相关联的路由。在一个实施例中,数字块架构由udb(通用数字块)组成。例如,每个udb可以包括alu连同cpld功能。
[0090]
在各种实施例中,可编程数字块1132的一个或多个udb可以被配置为执行各种数字功能,包括但不限于以下功能中的一个或多个:基本i2c从设备;i2c主设备;spi主设备或从设备;多线(例如,3线)spi主设备或从设备(例如,在单个引脚上复用的miso/mosi);定时器和计数器(例如,一对8位定时器或计数器、一个16位定时器或计数器、一个8位捕获定时器等);pwm(例如,一对8位pwm、一个16位pwm、一个8位死区pwm等);电平敏感的i/o中断发生器;正交编码器、uart(例如,半双工);延迟线;以及可以在多个udb中实现的任何其它合适类型的数字功能或数字功能的组合。
[0091]
在其它实施例中,可以使用一组两个或更多个udb来实现附加功能。仅仅出于说明
而非限制的目的,可以使用多个udb来实现以下功能:i2c从设备,其支持硬件地址检测以及在无cpu核心(例如,cpu核心1104)干预的情况下处理完整事务并帮助防止数据流中任何位上的强制时钟拉伸的能力;i2c多主设备,其可以在单个块中包括从选项;任意长度的prs或crc(高达32位);sdio;sgpio;数字相关器(例如,具有高达32位,具有4x过采样并支持可配置的阈值);linbus接口;delta
‑
sigma调制器(例如,对于具有差分输出对的d类音频dac);i2s(立体声);lcd驱动控制(例如,udb可以用于实现lcd驱动块的定时控制并提供显示ram寻址);全双工uart(例如,7、8或9位,具有1或2个停止位和奇偶校验,并支持rts/cts);irda(发送或接收);捕获定时器(例如,16位或类似的);死区pwm(例如,16位或类似的);smbus(包括在软件中用crc设置smbus分组的格式);无刷电机驱动器(例如,以支持6/12步换流);自动baud速率检测和生成(例如,自动地确定从1200到115200baud的标准速率的baud速率,并且在检测之后生成所需的时钟以生成baud速率);以及可以在多个udb中实现的任何其它合适类型的数字功能或数字功能的组合。
[0092]
可编程模拟块1134可以包括模拟资源,包括但不限于比较器、混频器、pga(可编程增益放大器)、tia(跨阻抗放大器)、adc(模数转换器)、dac(数模转换器)、电压基准、电流源、采样和保持电路、以及任何其它合适类型的模拟资源。可编程模拟块1134可以支持各种模拟功能,包括但不限于模拟路由、lcd驱动io支持、电容感测、电压测量、电机控制、电流到电压转换、电压到频率转换、差分放大、光测量、感应位置监测、滤波、音圈驱动、磁卡读取、声学多普勒测量、回声测距、调制解调器发送和接收编码、或任何其它合适类型的模拟功能。
[0093]
本文所描述的实施例可以用于相互电容感测系统、自电容感测系统、或二者的组合的各种设计中。在一个实施例中,电容感测系统检测在阵列中激活的多个感测元件,并且可以分析相邻感测元件上的信号模式以将噪声与实际信号分离。如受益于本公开的本领域的普通技术人员将理解的,本文所描述的实施例不绑定于特定的电容式感测解决方案,并且也可以与其它感测解决方案(包括光学感测解决方案)一起使用。
[0094]
在上述描述中,阐述了许多细节。然而,对于受益于本公开的本领域的普通技术人员来说将显而易见的是,可以在没有这些具体细节的情况下实践本公开的实施例。在一些实例中,为了避免使描述难以理解,以框图形式而不是详细地示出公知的结构和设备。
[0095]
在对计算机存储器内数据位的操作的算法和符号表示的方面,呈现了详细描述的一些部分。这些算法描述和表示是数据处理领域的技术人员用来最有效地将其工作的实质传达给本领域的其它技术人员的手段。算法在这里并且通常被构想为引起期望结果的步骤的自洽序列。这些步骤是需要对物理量进行物理操纵的步骤。通常,尽管不一定,这些量采取能够被存储、传送、组合、比较和以其它方式操纵的电信号或磁信号的形式。主要出于通用的原因,已经证明将这些信号称为位、值、元素、符号、字符、项、数字等有时是方便的。
[0096]
然而,应当牢记,所有这些和类似的术语都与适当的物理量相关联,并且仅仅是应用于这些量的方便标签。除非从上述讨论中显而易见地另有特别说明,否则应当理解的是,在整个描述中,利用诸如“确定”、“检测”、“比较”、“重置”、“添加”、“计算”等术语的讨论是指计算系统或类似的电子计算设备的动作和过程,计算系统或类似的电子计算设备操纵在计算系统的寄存器和存储器内被表示为物理(例如,电子)量的数据,并将其转换为在计算系统存储器或寄存器或其它这种信息存储、传输或显示设备内被类似地表示为物理量的其
它数据。
[0097]
在本文中使用词“示例”或“示例性”以表示充当示例、实例或说明。在本文中被描述为“示例”或“示例性”的任何方面或设计不一定被解释为相对于其它方面或设计是优选或有优势的。相反,词“示例”或“示例性”的使用旨在以具体的方式呈现构思。如在本技术中使用的,术语“或”旨在表示包含的“或”而不是排他的“或”。即,除非另有规定或根据上下文清楚,否则“x包括a或b”旨在表示任何自然的包含排列组合。即,如果x包括a;x包括b;或者x包括a和b二者,则在上述实例中的任一个下满足“x包括a或b”。另外,除非另有规定或根据上下文清楚地指向单数形式,否则本技术中使用的冠词“一(a)”和“一个(an)”以及所附权利要求书通常应当被解释为表示“一个或多个”。此外,在全文中使用术语“实施例”或“一个实施例”或“实施方式”或“一个实施方式”并不旨在表示相同的实施例或实施方式(除非如此描述)。
[0098]
本文所描述的实施例还可以涉及用于执行本文的操作的装置。此装置可以出于所需目的而被特别构造,或者其可以包括由存储在计算机中的计算机程序选择性地激活或重新配置的通用计算机。这种计算机程序可以被存储在非暂时性计算机可读存储介质中,例如但不限于任何类型的磁盘,包括软盘、光盘、cd
‑
rom和磁光盘、只读存储器(rom)、随机存取存储器(ram)、eprom、eeprom、磁卡或光卡、闪速存储器、或适用于存储电子指令的任何类型的介质。术语“计算机可读存储介质”应当被视为包括存储一个或多个指令集合的单个介质或多个介质(例如,集中式或分布式数据库和/或相关联的高速缓存和服务器)。术语“计算机可读介质”还应当被视为包括能够存储、编码或携带供机器执行的指令集合并且使得机器执行本实施例的方法中的任何一个或多个的任何介质。术语“计算机可读存储介质”应当相应地被视为包括但不限于固态存储器、光学介质、磁性介质、能够存储指令集合以供机器执行并且使得机器执行本实施例的方法中的任何一个或多个的任何介质。
[0099]
本文所提出的算法和显示与任何特定的计算机或其它装置不是固有地相关的。各种通用系统可以与根据本文的教导的程序一起使用,或者可以证明构造更专用的装置来执行所需的方法步骤是方便的。各种这些系统所需的结构将出现在上面的描述中。另外,不参考任何特定编程语言来描述本实施例。应当理解,可以使用各种编程语言来实现如本文所述的实施例的教导。
[0100]
上述描述阐述了许多具体细节,例如具体系统、组件、方法等的示例,以便提供对本公开的若干实施例的更好的理解。然而,对于本领域的技术人员来说将显而易见的是,可以在没有这些具体细节的情况下实践本公开的至少一些实施例。在其它实例中,为了避免不必要地使本实施例难以理解,公知的组件或方法没有被详细地描述或以简单框图格式呈现。因此,上面阐述的具体细节仅仅是示例性的。特定的实施方式可以不同于这些示例性细节,并且仍然被认为在本实施例的范围内。
[0101]
应当理解的是,上述描述旨在是说明性的而非限制性的。在阅读并理解了上述描述时,许多其它实施例对于本领域的技术人员来说将是显而易见的。因此,实施例的范围应当参考所附权利要求书连同这样的权利要求书有权享有的等同物的全部范围来确定。