1.本发明涉及智能毛绒玩具技术领域,尤其涉及一种语音交互毛绒玩具的智能唤醒方法及装置。
背景技术:
2.随着现代社会娱乐方式的发展,语音交互毛绒玩具比传统毛绒玩具更加生动形象,也就更受消费者喜爱,但是现有技术中语音交互毛绒玩具均采用的是被动唤醒的方式,比如硬件开关唤醒或者设定语音指令唤醒,这些方式是通过用户主动唤醒毛绒玩具进而实现语音交互,不能实现毛绒玩具的主动唤醒,缺乏毛绒玩具与人交互过程中的主动性。
技术实现要素:
3.有鉴于此,有必要提供一种语音交互毛绒玩具的智能唤醒方法及装置,用以解决现有技术中语音交互毛绒玩具缺乏主动性的问题。
4.为了解决上述问题,本发明提供一种语音交互毛绒玩具的智能唤醒方法,包括:
5.获取声音信息,根据所述声音信息构建人体行为声音识别模型;
6.根据获取的实时声音信息和所述人体行为声音识别模型判断是人体行为声音还是非人体行为声音;
7.若为人体行为声音则在设定时长内识别所述毛绒玩具有无振动,若有则唤醒语音交互。
8.进一步地,获取声音信息,根据所述声音信息构建人体行为声音识别模型,包括:
9.获取不同的人体行为声音和非人体行为声音,根据所述不同的人体行为声音和非人体行为声音得到对应的梅尔频率倒谱系数;
10.构建初始深度神经网络模型;
11.根据所述梅尔频率倒谱系数和所述初始深度神经网络模型得到人体行为声音识别模型。
12.进一步地,获取不同的人体行为声音和非人体行为声音,根据所述不同的人体行为声音和非人体行为声音得到对应的梅尔频率倒谱系数,包括:
13.获取人体行为声音音频和对应的音频标记、以及非人体行为声音音频和对应的音频标记,根据所述人体行为声音音频和非人体行为声音音频得到对应的梅尔频率倒谱系数。
14.进一步地,根据所述梅尔频率倒谱系数和所述初始深度神经网络模型得到人体行为声音识别模型,包括:
15.利用所述梅尔频率倒谱系数、所述人体行为声音音频标记以及非人体行为声音音频标记构建训练样本集,将所述训练样本集输入所述初始深度神经网络模型中进行训练得到所述人体行为声音识别模型。
16.进一步地,利用所述梅尔频率倒谱系数、所述人体行为声音音频标记以及非人体
行为声音音频标记构建训练样本集,包括:
17.获取不同的说话声音频、脚步声音频、咳嗽声音频和非人体行为声音频,以及不同的说话声音频、脚步声音频、咳嗽声音频和非人体行为声音频对应的音频标记,根据所述说话声音频、脚步声音频、咳嗽声音频和非人体行为声音频得到对应的梅尔频率倒谱系数;
18.利用所述梅尔频率倒谱系数和所述音频标记形成多组子训练样本集,利用所述子训练样本集构建训练样本集。
19.进一步地,所述初始深度神经模型包含输入层、隐含层及输出层,所述输入层用于输入梅尔频率倒谱系数,所述输出层用于输出人体行为声音对应数值和非人体行为声音对应数值。
20.进一步地,根据获取的实时声音信息和所述人体行为声音识别模型判断是人体行为声音还是非人体行为声音,包括:
21.获取设定时长的实时声音信息放入所述人体行为声音识别模型进行识别,得到模型输出,若所述模型输出是人体行为声音对应数值则识别结果为人体行为声音,若所述模型输出是非人体行为声音对应数值则识别结果为非人体行为声音。
22.本发明还提供一种语音交互毛绒玩具的智能唤醒装置,包括信息获取模块、数据处理模块及语音交互模块;
23.所述信息获取模块,用于获取声音信息,根据所述声音信息构建人体行为声音识别模型;
24.所述数据处理模块,根据获取的实时声音信息和所述人体行为声音识别模型判断是人体行为声音还是非人体行为声音;
25.所述语音交互模块,若为人体行为声音则在设定时长内识别所述毛绒玩具有无振动,若有则唤醒语音交互。
26.进一步地,所述数据处理模块包含麦克风和语音识别芯片,所述麦克风用于获取实时声音信息,所述语音识别芯片内置有基于深度神经网络的人体行为声音识别模型程序用于识别获取的实时声音信息;
27.所述语音交互模块包含振动传感器和扬声器,所述振动传感器用于识别所述毛绒玩具有无振动,所述扬声器用于语音交互。
28.进一步地,还包括电源模块和主控模块,所述电源模块用于给装置供能,所述主控模块包含主控芯片用于控制整个装置的正常运行。
29.采用上述实施例的有益效果是:本发明提供的语音交互毛绒玩具的智能唤醒方法,通过构建人体行为声音识别模型,利用模型识别实时获取到的声音信息,若为人体行为声音则能够主动唤醒毛绒玩具进行语音交互,使语音交互毛绒玩具具有主动性,提升了用户体验。
附图说明
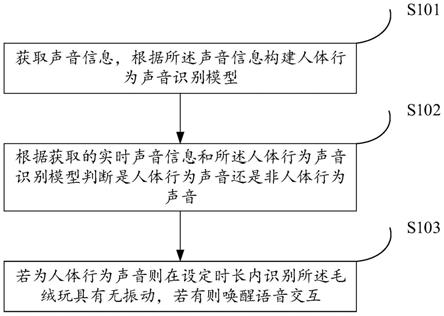
30.图1为本发明提供的语音交互毛绒玩具的智能唤醒方法一实施例的流程示意图;
31.图2为本发明实施例中提供的人体行为声音识别模型的结构示意图;
32.图3为本发明提供的语音交互毛绒玩具的智能唤醒装置一实施例的结构框图;
33.图4为本发明提供的语音交互毛绒玩具的智能唤醒装置一实施例的结构示意图。
具体实施方式
34.下面结合附图来具体描述本发明的优选实施例,其中,附图构成本技术一部分,并与本发明的实施例一起用于阐释本发明的原理,并非用于限定本发明的范围。
35.本发明提供了一种语音交互毛绒玩具的智能唤醒方法及装置,以下分别进行详细说明。
36.本发明实施例提供了一种语音交互毛绒玩具的智能唤醒方法,其流程示意图,如图1所示,所述语音交互毛绒玩具的智能唤醒方法包括:
37.步骤s101、获取声音信息,根据所述声音信息构建人体行为声音识别模型;
38.步骤s102、根据获取的实时声音信息和所述人体行为声音识别模型判断是人体行为声音还是非人体行为声音;
39.步骤s103、若为人体行为声音则在设定时长内识别所述毛绒玩具有无振动,若有则唤醒语音交互。
40.需要说明的是,通过构建人体行为声音识别模型,利用模型识别实时获取到的声音信息,若为人体行为声音则能够主动唤醒毛绒玩具进行语音交互,不是被动地等待人的手动或语音唤醒,而是能够智能地识别周围声音信息,从而主动进行语音交互,使毛绒玩具的语音交互具有主动性,提升了用户体验。
41.作为一个优选的实施例,获取声音信息,根据所述声音信息构建人体行为声音识别模型,包括:
42.获取不同的人体行为声音和非人体行为声音,根据所述不同的人体行为声音和非人体行为声音得到对应的梅尔频率倒谱系数;
43.构建初始深度神经网络模型;
44.根据所述梅尔频率倒谱系数和所述初始深度神经网络模型得到人体行为声音识别模型。
45.作为一个优选的实施例,获取不同的人体行为声音和非人体行为声音,根据所述不同的人体行为声音和非人体行为声音得到对应的梅尔频率倒谱系数,包括:
46.获取人体行为声音音频和对应的音频标记、以及非人体行为声音音频和对应的音频标记,根据所述人体行为声音音频和非人体行为声音音频得到对应的梅尔频率倒谱系数。
47.一个具体的实施例中,采集2000组不同的说话声音频片段包含男声、女声及不同年龄段、不同音色、不同内容的音频片段,音频片段时长均为3秒;
48.采集2000组不同的脚步声音频片段包含轻走、重走、慢跑、快跑及在不同地面环境下的音频片段,音频片段时长均为3秒;
49.采集2000组不同的咳嗽声音频片段包含男声、女声及不同年龄段、不同音调、不同轻重的音频片段,音频片段时长均为3秒;
50.采集8000组不同的非人体行为声音片段包含日常环境常见声音的音频片段,音频片段时长均为3秒,本实施例中日常环境常见声音选择2000组不同的汽车鸣笛声、2000组不同的汽车行驶声、1000组不同的电钻声、1000组不同的雷声、1000组不同的下雨声及1000组不同的环境白噪声。
51.作为一个优选的实施例,根据所述梅尔频率倒谱系数和所述初始深度神经网络模
型得到人体行为声音识别模型,包括:
52.利用所述梅尔频率倒谱系数、所述人体行为声音音频标记以及非人体行为声音音频标记构建训练样本集,将所述训练样本集输入所述初始深度神经网络模型中进行训练得到所述人体行为声音识别模型。
53.一个具体的实施例中,说话声、脚步声、咳嗽声均为人体行为声音,人体行为声音的音频标记为1,汽车鸣笛声、汽车行驶声、电钻声、雷声、下雨声及环境白噪声均为非人体行为声音,非人体行为声音的音频标记为2。
54.作为一个优选的实施例,利用所述梅尔频率倒谱系数、所述人体行为声音音频标记以及非人体行为声音音频标记构建训练样本集,包括:
55.获取不同的说话声音频、脚步声音频、咳嗽声音频和非人体行为声音频,以及不同的说话声音频、脚步声音频、咳嗽声音频和非人体行为声音频对应的音频标记,根据所述说话声音频、脚步声音频、咳嗽声音频和非人体行为声音频得到对应的梅尔频率倒谱系数;
56.利用所述梅尔频率倒谱系数和所述音频标记形成多组子训练样本集,利用所述子训练样本集构建训练样本集。
57.一个具体的实施例中,所述训练样本集为
58.s
train
={mfcc
m1-i
|1,mfcc
m2-j
|1,mfcc
m3-k
|1,mfcc
m4-s
|2},
59.其中,mfcc
m1-i
|1(i=1,2,
…
,2000)、mfcc
m2-j
|1(j=1,2,
…
,2000)、mfcc
m3-k
|1(k=1,2,
…
,2000)、mfcc
m4-s
|2(s=1,2,
…
,8000)分别为包含对应梅尔频率倒谱系数的子样本数据集m1、m2、m3、m4,mfcc
m1-i
为子样本数据集m1中第i组说话声对应的梅尔频率倒谱系数,mfcc
m2-j
为子样本数据集m2中第j组脚步声对应的梅尔频率倒谱系数,mfcc
m3-k
为子样本数据集m3中第k组咳嗽声对应的梅尔频率倒谱系数,mfcc
m4-s
为子样本数据集m4中第s组非人体行为声音对应的梅尔频率倒谱系数。
60.作为一个优选的实施例,所述初始深度神经网络模型包含输入层、隐含层及输出层,所述输入层用于输入梅尔频率倒谱系数,所述输出层用于输出人体行为声音对应数值和非人体行为声音对应数值。具体的,当输入层输入梅尔频率倒谱系数以及上述训练样本集后,经过隐含层的处理,输出层输出人体行为声音对应数值和非人体行为声音对应数值,可得到人体行为声音识别模型。
61.一个具体的实施例中,所述人体行为声音识别模型也包含输入层、隐含层及输出层,所述人体行为声音识别模型包含1层输入层,6层隐含层及1层输出层,隐含层的节点数从第一层至第六层分别为32、32、16、16、16、8。
62.作为一个优选的实施例,根据获取的实时声音信息和所述人体行为声音识别模型判断是人体行为声音还是非人体行为声音,包括:
63.获取设定时长的实时声音信息放入所述人体行为声音识别模型进行识别,得到模型输出,若所述模型输出是人体行为声音对应数值则识别结果为人体行为声音,若所述模型输出是非人体行为声音对应数值则识别结果为非人体行为声音。
64.一个具体的实施例中,人体行为声音识别模型的结构示意图,如图2所示,根据实时声音信息得到对应的梅尔频率倒谱系数,输入梅尔频率倒谱系数,输出识别结果,输出数值1表示识别结果为人体行为声音,输出数值2表示识别结果为非人体行为声音。
65.另一个具体的实施例中,当识别结果为人体行为声音时,获取交互询问音频“主人
是你吗?我想和你说说话,快来抱抱我吧”,并开始计时得到起始时间,在所述起始时间至设定时长的结束时间的过程中识别有无振动,设定时长10秒,在10秒内识别有无振动。
66.本发明实施例提供一种语音交互毛绒玩具的智能唤醒装置,其结构框图,如图3所示,所述语音交互毛绒玩具的智能唤醒装置包括信息获取模块301、数据处理模块302及语音交互模块303;
67.所述信息获取模块301,用于获取声音信息,根据所述声音信息构建人体行为声音识别模型;
68.所述数据处理模块302,根据获取的实时声音信息和所述人体行为声音识别模型判断是人体行为声音还是非人体行为声音;
69.所述语音交互模块303,若为人体行为声音则在设定时长内识别所述毛绒玩具有无振动,若有则唤醒语音交互。
70.作为一个优选的实施例,所述数据处理模块包含麦克风和语音识别芯片,所述麦克风用于获取实时声音信息,所述语音识别芯片内置有基于深度神经网络的人体行为声音识别模型程序用于识别获取的实时声音信息;
71.所述语音交互模块包含振动传感器和扬声器,所述振动传感器用于识别所述毛绒玩具有无振动,所述扬声器用于语音交互。
72.一个具体的实施例中,麦克风不间断采集时长3秒的声音音频,并实时送入语音识别芯片。
73.作为一个优选的实施例,还包括电源模块和主控模块,所述电源模块用于给装置供能,所述主控模块包含主控芯片用于控制整个装置的正常运行。
74.一个具体的实施例中,语音交互毛绒玩具的智能唤醒装置的结构示意图,如图4所示,麦克风用于获取实时声音信息,获取到的声音信息在语音识别芯片中进行识别处理,处理结果输入至主控芯片,由主控芯片进行判断是人体行为声音还是非人体行为声音,并决定是否开启振动传感器感应功能识别所述毛绒玩具的振动情况,扬声器用于语音交互,电源模块用于给装置供能。
75.综上所述,本发明提供的语音交互毛绒玩具的智能唤醒方法及装置通过构建人体行为声音识别模型,利用模型识别实时获取到的声音信息,若为人体行为声音则能够主动唤醒毛绒玩具进行语音交互,若为非人体行为声音则继续获取实时声音信息,不需要被动地等待人的手动或语音唤醒,能够智能地识别周围声音信息,从而主动进行语音交互,增强了毛绒玩具在与人交互过程中的主动性,提升了语音交互毛绒玩具的用户体验。
76.以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。