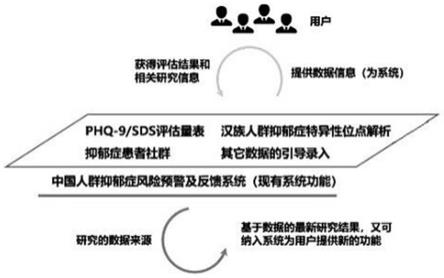
1.本发明具体涉及一种基于多维健康数据的中国人群抑郁症风险预警及反馈系统。
背景技术:
2.抑郁症是一种容易使人衰弱的精神疾病,但它对人的伤害却远远没有字面上说的那么轻巧。在全球范围内,致残的主要原因不是别的,竟然是因为抑郁症。不仅如此,抑郁症的患病几率也是惊人的,有研究估算,全球大约有1/6的人,在一生中都至少会患上一次抑郁症,而更可怕的是,他们之中有很多人甚至都不会察觉自己原来抑郁了。也正是因为此,研究抑郁症的发病机制,一直都是全球范围内的一项研究热点。早在10几年前,就有研究人员通过双胞胎实验,发现抑郁症也具有相当的遗传程度,但由于条件的限制,尤其是抑郁症人群样本的收集难度较大,在18年之前一直没有在基因层面挖掘出关联度较强,及有价值的突变位点。目前在抑郁症上的研究主要存在以下几方面的主要问题:
3.1、抑郁症为多基因疾病,与抑郁症发病相关联的基因,多为微效基因,单独的突变基因型并不能起到显著的作用,抑郁症风险的增加,往往由多个基因突变型同决定。而因此,想要挖掘出更有价值的结果,需要非常大量的研究样本。
4.2、基于目前的研究结果,抑郁症在遗传层面,在不同的人群之间具有很大的特异性,比如一些高风险基因位点,被发现为汉族人群特异性位点,在欧美人群中的突变频率很低,且并无显著性关联。因此,基于不同遗产背景的人群进行分群研究,是目前抑郁症研究领域一个难点。
5.基于与i中描述类似的原因,目前抑郁症在治疗,具体发病机制,与脑部相关区域的研究上,都在一定程度上受到了限制。而在2019年,一项发表在国际顶级期刊的研究论文,在一定程度上,揭示了商业公司在抑郁症研究上的潜在重要性。该项研究结果纳入了超过80万样本人群的数据,而如此庞大的数据量,如果没有商业公司的反馈系统与数据库的支持,是很难通过传统的科研机构实现的。
技术实现要素:
6.本发明的目的在于针对现有技术的不足,提供一种基于多维健康数据的人群抑郁症风险预警及反馈系统,该基于多维健康数据的人群抑郁症风险预警及反馈系统可以很好地解决上述问题。
7.为达到上述要求,本发明采取的技术方案是:提供一种基于多维健康数据的人群抑郁症风险预警及反馈系统,该基于多维健康数据的人群抑郁症风险预警及反馈系统包括如下步骤:
8.s1:进行关于人群抑郁症目前相关研究信息的收集的步骤;
9.s2:进行系统用户界面及功能构建的步骤;
10.s3:进行基于深度学习算法的预测模型构建的步骤;
11.s4:进行模型验证的步骤。
12.该基于多维健康数据的人群抑郁症风险预警及反馈系统具有的优点如下:
13.该系统构建具有高信息展示度,并具有良好用户体验反馈的,是一种适合中国人群的抑郁症风险预警与反馈系统。
附图说明
14.此处所说明的附图用来提供对本技术的进一步理解,构成本技术的一部分,在这些附图中使用相同的参考标号来表示相同或相似的部分,本技术的示意性实施例及其说明用于解释本技术,并不构成对本技术的不当限定。在附图中:
15.图1示意性地示出了根据本技术一个实施例的基于多维健康数据的人群抑郁症风险预警及反馈系统的示意图。
16.图2示意性地示出了pca模型示意图。
17.图3示意性地示出了gwas统计学关联位点的示意图。
具体实施方式
18.为使本技术的目的、技术方案和优点更加清楚,以下结合附图及具体实施例,对本技术作进一步地详细说明。
19.在以下描述中,对“一个实施例”、“实施例”、“一个示例”、“示例”等等的引用表明如此描述的实施例或示例可以包括特定特征、结构、特性、性质、元素或限度,但并非每个实施例或示例都必然包括特定特征、结构、特性、性质、元素或限度。另外,重复使用短语“根据本技术的一个实施例”虽然有可能是指代相同实施例,但并非必然指代相同的实施例。
20.为简单起见,以下描述中省略了本领域技术人员公知的某些技术特征。
21.根据本技术的一个实施例,提供一种基于多维健康数据的人群抑郁症风险预警及反馈系统,如图1所示,包括如下步骤:
22.step1:关于中国人群抑郁症目前相关研究信息的收集
23.对于系统的构建基础,首先需要为用户提供有价值的反馈结果,才有可能吸引大量用户的使用,因此系统最初提供的功能,都是基于现有的研究成果。比如,已有的sds(self-rating depression scale)自评量表,是目前广泛应用于门诊病人的粗筛、情绪状态评定以及调查、科研等的一套评价体系。其特点是使用简便,同时能相当直观的反应抑郁患者的主观感受及其在治疗中的变化。与之相似的还有phq-9抑郁症筛查量表。这两套量表体系本身是一套独立的评判体系,既能作为提供给用户的一个评估结果,也能作为后期筛选原创性研究,患者人群判断的一个标准。
24.step2:系统的用户界面及功能的构建(it工作)
25.step3:基于深度学习算法的预测模型构建
26.基于用户的基因芯片数据,问卷数据,体检指标数据,及量表的评估结果。基于深度学习(deep learning)算法构建预测模型,确定最佳数据集(最大化 sensitivity和specificity),用模型阈值风险分群结果,作为推荐人群预防控制的数据基础
27.step4:模型验证(application phase)
28.分阶段性的,利用最新的用户数据定期对模型进行优化与评估,在基于样板量持续增加的情况下,保证模型的预测性能稳步提升。
29.根据本技术的一个实施例,该基于多维健康数据的人群抑郁症风险预警及反馈系统的具体方案如下:
30.数据整合:
31.合并所有样本的基因型数据,总共712229个变异位点,其中600190个snp。
32.数据过滤:
33.根据maf、missing-rate、hwe等参数对snp进行过滤。
34.经过不同参数的过滤以及后续基因型填充和关联分析,最终结果使用没有进行数据过滤的版本。
35.基因型填充:
36.使用beagle软件对缺失基因型进行填充,参考数据使用的是1000g汉族人基因型。
37.关联分析:
38.使用plink软件进行关联分析,采用逻辑回归模型。为了得到相对关联性比较显著的snp,同时对pca做协变量和无协变量两种模型进行关联分析如下:
39.qq-plot:
40.qq plot的全称是quantile-quantile plot,即分位数-分位数图。这个图形的形式非常简单,它们本质上就是做两组数据的比较,判断它们是否基本一致。即它比较的是p value观测值(y轴)和p value期望值的一致性。
41.在统计检验中,p value代表的是我们观测值偏离期望值的概率。假设观测值符合标准正态分布,当我们观测次数越大,出现极端观测值(偏离期望值更加剧烈)的概率也越大,当我们观察n次之后,那么这些观测值的分布就应该符合正态分布,而那么这些观测值对应的离群概率(pvalue)应该符合均匀分布 (uniform distribution),即p value分布在0~1之间的各个区段的概率是相同的。
42.实际上,对于大部分统计方法,如果我们的数值符合某一种统计模型,那么当我们统计若干次后,得到的p value的分布是可以预期的,其应该符合均匀分布——这就是p value的期望分布。
43.注:qq plot是两组数值的比较。这两组数值分布是期望的p value和观测到的p value,分别对应图中的x轴和y轴,qq-plot主要展示了关联分析结果中性状与变异位点相关显著性p值的评估,如果我们的统计模型正确,两组p value值应该是一致的。那么,两组值(取-log10)从小到大排列后绘制在散点图上,所有点应该位于45
°
对角线上,红色斜直线为x=y,所以判断图形中点的分布是否合理(是否位于对角线上),进而推断目前的统计模型获得的p值是否符合期望值以及统计模型是否合理。
44.在图2中,pca模型明显偏向对角线的下方,说明p value被过度校正,导致p value显著性过低,因此该模型不适合。
45.在图3中,无协变量逻辑回归模型中,大部分位点贴近对角线,p value观察值和期望值基本相同,说明分析模型是合理的。但大部分的p value观测值都没有明显超过期望值,仅有少量位点有关联效应,可能原因包括:性状由微效多基因控制,效应太弱;群体大小不够;芯片数据检测的位点中未包含显著关联效应的位点。在图形的右上角则是显著性较高的位点,是潜在与性状相关的候选位点。这些点位于对角线的上方,即位点的p value观测值超过了期望值,说明这些位点的效应超过了随机效应,进而说明这些位点是与性状显
著相关的。该情况也与下面曼哈顿图相互吻合。
46.曼哈顿图:
47.曼哈顿图最普遍的应用就是在全基因组关联分析(gwas)中,展示全基因组水平所有snp的与某个性状相关性的p value。
[0048][0049]
关联分析结果
[0050]
使用填充后的所有位点进行分析,32069657位点参与最后的关联分析。
[0051][0052][0053]
以上所述实施例仅表示本发明的几种实施方式,其描述较为具体和详细,但并不能理解为对本发明范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明保护范围。因此本发明的保护范围应该以所述权利要求为准。