1.本发明涉及语音降噪识别,具体涉及一种具有语音降噪功能的鼠标。
背景技术:
2.鼠标发明到现在已经有几十年历史,其作为一种计算机的人机交互设备被广泛应用。当前,鼠标的基本功能是用来控制光标移动,以及实现一些简单的按键功能,例如左键、右键、滚轮等,严重制约了鼠标的人机交互能力,所以人们开始设计一些具备更多功能的鼠标。
3.具备语音识别功能的鼠标具有较高的实用价值,在很多发明专利中也有相关设计方案,概括起来主要有三大类:一是利用语音识别技术来实现鼠标的功能,解决一些残疾人无法手动操作鼠标的问题,该方案不是扩展鼠标的使用功能,而是一种替代鼠标的操作方式;二是在鼠标上集成语音识别处理模块,依赖鼠标上的语音识别处理模块实现语音识别,从而达到语音控制鼠标的目的,受到语音识别处理模块本身计算能力的限制,在识别准确率方面都受到严重制约,这也严重影响了语音交互效果;三是利用语音识别技术与其它交互技术融合来解决人机交互问题。
4.从上述三种使得鼠标具备语音识别功能的技术方案来看,限制与鼠标之间语音交互的主要因素在于语音识别的准确率。受到语音识别模块本身算力以及外部噪声干扰的影响,与鼠标进行语音交互的效果较差,如何有效提高语音识别的准确率是当前在鼠标语音交互方面亟待解决的技术问题。
技术实现要素:
5.(一)解决的技术问题
6.针对现有技术所存在的上述缺点,本发明提供了一种具有语音降噪功能的鼠标,能够有效克服现有技术所存在的与鼠标进行语音交互时语音识别准确率较低的缺陷。
7.(二)技术方案
8.为实现以上目的,本发明通过以下技术方案予以实现:
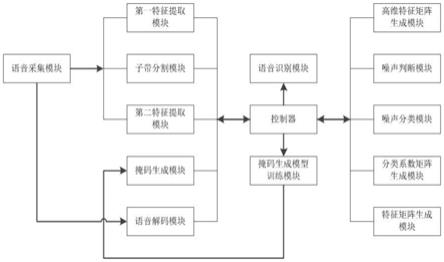
9.一种具有语音降噪功能的鼠标,包括设于鼠标内部的控制器,以及用于采集用户语音的语音采集模块,所述控制器通过语音增强单元对含噪语音进行语音增强,所述控制器通过降噪识别单元对增强后的语音进行语音识别;
10.所述语音增强单元对含噪语音进行语音特征提取,并基于提取语音特征得到掩码,结合掩码及含噪语音进行解码,得到增强语音;所述降噪识别单元对增强语音提取特征向量矩阵,并基于训练好的级联卷积神经网络对增强语音进行语音识别,得到语音识别结果。
11.优选地,所述语音增强单元包括第一特征提取模块、子带分割模块、掩码生成模型训练模块、掩码生成模块和语音解码模块;
12.第一特征提取模块,提取含噪语音中的语音特征;
13.子带分割模块,将含噪语音的频域划分为多个子带;
14.掩码生成模型训练模块,构建用于对频域划分为多个子带的含噪语音生成掩码的掩码生成模型,并对掩码生成模型进行模型训练;
15.掩码生成模块,将提取的语音特征输入训练好的掩码生成模型,以得到代表各子带增益的多维掩码;
16.语音解码模块,利用时域解码器对多维掩码、含噪语音进行解码,得到增强语音。
17.优选地,所述语音解码模块将多维掩码、含噪语音输入时域解码器,利用时域解码器对含噪语音在不同子带上对应的掩码进行滤波,得到增强语音。
18.优选地,所述时域解码器为iir带通滤波器或fir滤波器。
19.优选地,所述第一特征提取模块对含噪语音进行预加重、分帧、加窗以及短时傅里叶变换得到语音特征。
20.优选地,所述降噪识别单元包括第二特征提取模块、高维特征矩阵生成模块、噪声判断模块、噪声分类模块、分类系数矩阵生成模块、特征矩阵生成模块和语音识别模块;
21.第二特征提取模块,用于对增强语音进行特征提取,得到包含噪声的特征向量矩阵;
22.高维特征矩阵生成模块,将特征向量矩阵输入级联卷积神经网络,得到高维特征矩阵;
23.噪声判断模块,基于高维特征矩阵在全连接层判断是否为噪声;
24.噪声分类模块,基于高维特征矩阵在全连接层根据噪声分类标准判断噪声种类;
25.分类系数矩阵生成模块,根据噪声种类和预设各种类噪声的分类系数矩阵,得到特征向量矩阵对应的分类系数矩阵;
26.特征矩阵生成模块,对噪声种类和特征向量矩阵对应的分类系数矩阵进行运算,得到特征向量矩阵对应的特征矩阵;
27.语音识别模块,将特征向量矩阵对应的分类系数矩阵、特征矩阵输入级联卷积神经网络进行语音识别,得到语音识别结果。
28.优选地,所述高维特征矩阵生成模块将特征向量矩阵输入第一级卷积神经网络,所述第一级卷积神经网络利用不同尺寸的卷积核对特征向量矩阵进行一维卷积,得到高维特征矩阵。
29.优选地,所述语音识别模块将特征向量矩阵对应的分类系数矩阵、特征矩阵输入第二级卷积神经网络,得到特征向量矩阵对应的音频概率,所述语音识别模块使用解码图对最大音频概率对应的音频进行解码,得到语音识别结果。
30.优选地,所述第一级卷积神经网络、第二级卷积神经网络中均包含有残差网络,所述第二级卷积神经网络为包含注意力机制的卷积神经网络。
31.优选地,所述第二特征提取模块对增强语音进行预加重、分帧、傅里叶变换以及fbank特征提取,得到包含噪声的特征向量矩阵。
32.(三)有益效果
33.与现有技术相比,本发明所提供的一种具有语音降噪功能的鼠标,首先利用语音增强单元对含噪语音进行语音特征提取,并基于提取语音特征得到掩码,结合掩码及含噪语音进行解码,得到增强语音,能够对含噪语音进行初步降噪;通过降噪识别单元对增强语
音提取特征向量矩阵,并基于训练好的级联卷积神经网络对增强语音进行语音识别,能够在语音识别过程中对增强语音进行再次降噪,通过两次降噪能够有效滤除用户语音中的噪声,从而有效提升语音识别的准确率。
附图说明
34.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍。显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
35.图1为本发明的系统示意图;
36.图2为本发明中降噪识别单元对增强语音进行语音识别的流程示意图。
具体实施方式
37.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
38.一种具有语音降噪功能的鼠标,如图1和图2所示,包括设于鼠标内部的控制器,以及用于采集用户语音的语音采集模块,控制器通过语音增强单元对含噪语音进行语音增强,控制器通过降噪识别单元对增强后的语音进行语音识别。
39.语音增强单元对含噪语音进行语音特征提取,并基于提取语音特征得到掩码,结合掩码及含噪语音进行解码,得到增强语音。
40.语音增强单元包括第一特征提取模块、子带分割模块、掩码生成模型训练模块、掩码生成模块和语音解码模块;
41.第一特征提取模块,提取含噪语音中的语音特征;
42.子带分割模块,将含噪语音的频域划分为多个子带;
43.掩码生成模型训练模块,构建用于对频域划分为多个子带的含噪语音生成掩码的掩码生成模型,并对掩码生成模型进行模型训练;
44.掩码生成模块,将提取的语音特征输入训练好的掩码生成模型,以得到代表各子带增益的多维掩码;
45.语音解码模块,利用时域解码器对多维掩码、含噪语音进行解码,得到增强语音。
46.其中,第一特征提取模块对含噪语音进行预加重、分帧、加窗以及短时傅里叶变换得到语音特征。
47.其中,语音解码模块将多维掩码、含噪语音输入时域解码器,利用时域解码器对含噪语音在不同子带上对应的掩码进行滤波,得到增强语音,语音解码模块所采用的时域解码器为iir带通滤波器或fir滤波器。
48.本技术技术方案中,语音增强单元首先提取含噪语音中的语音特征,并将含噪语音的频域划分为多个子带;同时构建用于对频域划分为多个子带的含噪语音生成掩码的掩码生成模型,并对掩码生成模型进行模型训练;再将提取的语音特征输入训练好的掩码生
成模型,得到代表各子带增益的多维掩码;最后利用时域解码器对多维掩码、含噪语音进行解码,得到增强语音,实现了对含噪语音的初步降噪。
49.降噪识别单元对增强语音提取特征向量矩阵,并基于训练好的级联卷积神经网络对增强语音进行语音识别,得到语音识别结果。如图2所示,为降噪识别单元对增强语音进行语音识别的流程示意图。
50.降噪识别单元包括第二特征提取模块、高维特征矩阵生成模块、噪声判断模块、噪声分类模块、分类系数矩阵生成模块、特征矩阵生成模块和语音识别模块;
51.第二特征提取模块,用于对增强语音进行特征提取,得到包含噪声的特征向量矩阵;
52.高维特征矩阵生成模块,将特征向量矩阵输入级联卷积神经网络,得到高维特征矩阵;
53.噪声判断模块,基于高维特征矩阵在全连接层判断是否为噪声;
54.噪声分类模块,基于高维特征矩阵在全连接层根据噪声分类标准判断噪声种类;
55.分类系数矩阵生成模块,根据噪声种类和预设各种类噪声的分类系数矩阵,得到特征向量矩阵对应的分类系数矩阵;
56.特征矩阵生成模块,对噪声种类和特征向量矩阵对应的分类系数矩阵进行运算,得到特征向量矩阵对应的特征矩阵;
57.语音识别模块,将特征向量矩阵对应的分类系数矩阵、特征矩阵输入级联卷积神经网络进行语音识别,得到语音识别结果。
58.其中,第二特征提取模块对增强语音进行预加重、分帧、傅里叶变换以及fbank特征提取,得到包含噪声的特征向量矩阵。
59.其中,高维特征矩阵生成模块将特征向量矩阵输入第一级卷积神经网络,第一级卷积神经网络利用不同尺寸的卷积核对特征向量矩阵进行一维卷积,得到高维特征矩阵。
60.其中,语音识别模块将特征向量矩阵对应的分类系数矩阵、特征矩阵输入第二级卷积神经网络,得到特征向量矩阵对应的音频概率,语音识别模块使用解码图对最大音频概率对应的音频进行解码,得到语音识别结果。
61.第一级卷积神经网络、第二级卷积神经网络中均包含有残差网络,第二级卷积神经网络为包含注意力机制的卷积神经网络。
62.本技术技术方案中,降噪识别单元通过对增强语音进行特征提取,得到包含噪声的特征向量矩阵,并且依据特征向量矩阵得到高维特征矩阵,再利用高维特征矩阵判断噪声种类,同时后续得到的分类系数矩阵、特征矩阵中均包含噪声信息,从而能够在语音识别过程中对增强语音进行再次降噪,通过两次降噪能够有效滤除用户语音中的噪声,有效提升语音识别的准确率。
63.以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不会使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。