1.本发明属于信息处理的领域,具体涉及一种基于时频掩蔽平滑策略的单声道噪声抑制方法和装置。
背景技术:
2.在语音会议系统等诸多应用中,麦克风采集的语音信号会被信道噪声和各种背景噪声所干扰。这些平稳噪声,传输到对方网络经过扬声器播放之后,会降低通话系统的通信质量。通过算法来抑制麦克风采集到的噪声信号,同时语音信号失真控制在非常低的水平,是目前通话系统的常规方法。
3.现有技术中,为了改善会议系统或者会议设备中语音通讯质量,如何抑制噪声一直是一项关键技术。传统信号处理的方法是追踪信号中的噪音功率谱密度和语音功率谱密度,然后基于维纳滤波在频域构建一个0到1的掩蔽值,对麦克风信号掩蔽之后,达到抑制背景噪声的目的。然而,纯粹采用信号处理的方法,无非有效追踪背景中的非平稳噪声,其次在强背景噪音场景下,有较大的语音失真。随着深度学习技术的发展和成熟,在噪声抑制领域应用也越来越广泛。为了解决传统信号处理方法无法处理非平稳噪声的问题,越来越多基于深度学习的方法被提出来,主要思路是通过训练带噪声数据集到纯净语音信号,直接从混合信号中估计时频掩蔽值。
4.目前,基于深度学习在噪声抑制的效果上优于传统信号处理方法,然而也存在一些问题;1)实际应用中数据如果和训练数据集不匹配,会存在泛化性的问题;2)采用传统信号处理方案,无法有效处理环境中普遍存在的非平稳噪声;3)基于深度学习估计时频掩蔽的方法,存在泛化性不足的风险,并且噪声抑制过于干净,存在相对较大的语音失真。
5.有鉴于此,特提出本发明。
技术实现要素:
6.本发明的目的是提供一种基于时频掩蔽平滑策略的单声道噪声抑制方法和装置,其基于时频掩蔽平滑策略,并设计了新的时频掩蔽,该平滑策略可以有效降低语音失真,同时对原掩蔽值的误差可以有效平滑,提高原时频掩蔽估计的泛化性。
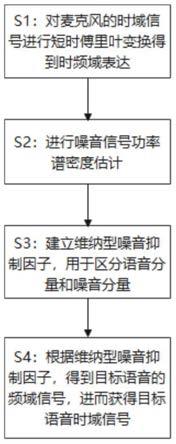
7.为了实现上述目的,本发明提供的一种基于时频掩蔽平滑策略的单声道噪声抑制方法,包括以下步骤:
8.s1:对麦克风的时域信号进行短时傅里叶变换得到时频域表达;
9.s2:进行噪音信号功率谱密度估计,其具体包括:噪音功率谱密度初估计、平稳噪音功率谱密度估计、语音功率谱密度估计以及计算平滑后的噪音功率谱密度;
10.s3:建立维纳型噪音抑制因子,用于区分语音分量和噪音分量;
11.s4:根据维纳型噪音抑制因子,得到目标语音的频域信号,进而获得目标语音时域信号。
12.进一步地,所述步骤s1之前还包括:获取麦克风的语音信号x(n);
13.所述步骤s1包括:
14.对时域信号x(n)进行短时傅里叶变换得到时频域表达:
[0015][0016]
进一步地,所述步骤s2具体包括以下步骤:
[0017]
s201:假设采用深度学习估计的时频掩蔽值为m(l,k),对每一个频带k,计算噪音功率谱密度初估计ρ
v
(k);其中,噪音功率谱密度初估计ρ
v
(k)的计算公式如下:
[0018]
ρ
v
(k)=αρ
v
(k)+(1
‑
α)(1
‑
m(l,k))x(l,k)|2;
[0019]
s202:估计平稳噪音功率谱密度ρ
min
(k);其中,平稳噪音功率谱密度ρ
min
(k)的计算公式如下:
[0020]
ρ
min
(k)=αρ
min
(k)+(1
‑
α)min(ρ
v
(k),|x(l,k)|2);
[0021]
s203:估计语音功率谱密度ρ
y
(k);其中,语音功率谱密度ρ
y
(k)的计算公式如下:
[0022]
ρ
y
(k)=αρ
y
(k)+(1
‑
α)m(l,k)|x(l,k)|2;
[0023]
s204:计算平滑后的噪音功率谱密度ρ
s
(k);其中,平滑后的噪音功率谱密度ρ
s
(k)的计算公式如下:
[0024][0025]
其中,α为相邻帧间的平滑因子。
[0026]
进一步地,所述相邻帧间的平滑因子α的取值为0.95。
[0027]
更进一步地,所述维纳型噪音抑制因子g(l,k)的计算公式如下:
[0028][0029]
其中,公式中的第一项为语音分量,第二项为噪音分量。
[0030]
本发明还提供了一种基于时频掩蔽平滑策略的单声道噪声抑制装置,包括初始化模块、信号功率谱密度估计模块、噪音抑制因子计算模块和目标语音估计模块:
[0031]
初始化模块用于对麦克风的时域信号进行短时傅里叶变换得到时频域表达;
[0032]
信号功率谱密度估计模块用于进行噪音信号功率谱密度估计,其具体包括:噪音功率谱密度初估计、平稳噪音功率谱密度估计、语音功率谱密度估计以及计算平滑后的噪音功率谱密度;
[0033]
噪音抑制因子计算模块用于建立维纳型噪音抑制因子,用于区分语音分量和噪音分量;
[0034]
目标语音估计模块用于根据维纳型噪音抑制因子,得到目标语音的频域信号,进而获得目标语音时域信号。
[0035]
进一步地,所述初始化模块还用于获取麦克风的语音信号x(n);
[0036]
所述初始化模块用于对时域信号x(n)进行短时傅里叶变换得到时频域表达:
[0037][0038]
进一步地,所述信号功率谱密度估计模块中,
[0039]
所述噪音功率谱密度初估计包括:假设采用深度学习估计的时频掩蔽值为m(l,
k),对每一个频带k,计算噪音功率谱密度初估计ρ
v
(k);其中,噪音功率谱密度初估计ρ
v
(k)的计算公式如下:
[0040]
ρv(k)=αρv(k)+(1
‑
α)(1
‑
m(l,k))|x(l,k)|2;
[0041]
所述平稳噪音功率谱密度ρ
min
(k)的计算公式如下:
[0042]
ρ
min
(k)=αρ
min
(k)+(1
‑
α)min(ρ
v
(k),|x(l,k)|2);
[0043]
所述语音功率谱密度ρ
y
(k)的计算公式如下:
[0044]
ρ
y
(k)=αρ
y
(k)+(1
‑
α)m(l,k)|x(l,k)|2;
[0045]
所述平滑后的噪音功率谱密度ρ
s
(k)的计算公式如下:
[0046][0047]
其中,α为相邻帧间的平滑因子。
[0048]
进一步地,所述相邻帧间的平滑因子α的取值为0.95。
[0049]
更进一步地,所述维纳型噪音抑制因子g(l,k)的计算公式如下:
[0050][0051]
其中,公式中的第一项为语音分量,第二项为噪音分量。
[0052]
本发明提供的一种基于时频掩蔽平滑策略的单声道噪声抑制方法和装置,具有如下有益效果:
[0053]
1、本发明对基于深度学习得到的时频掩蔽信息再次平滑,对噪音功率谱密度估计进行3次平滑,得到更为鲁棒的噪音估计,避免语音失真。
[0054]
2)本发明采用新型的维纳型噪音抑制因子,考虑了语音通讯的特点,在语音失真与噪音抑制权衡中,优先保证语音不失真,具有更好的通讯质量。
附图说明
[0055]
图1为本具体实施方式中的基于时频掩蔽平滑策略的单声道噪声抑制方法的流程图。
[0056]
图2为本具体实施方式中的使用的汉明窗函数的示意图。
[0057]
图3为本具体实施方式中的基于时频掩蔽平滑策略的单声道噪声抑制装置的示意图。
具体实施方式
[0058]
为了使本技术领域的人员更好地理解本发明方案,下面结合具体实施方式对本发明作进一步的详细说明。
[0059]
如图1所示,本发明的一实施方式为一种基于时频掩蔽平滑策略的单声道噪声抑制方法。
[0060]
具体包括以下四个实施步骤:
[0061]
s1:对麦克风的时域信号进行短时傅里叶变换得到时频域表达。
[0062]
在步骤s1之前,还包括获取麦克风的语音信号,获取的语音信号如下:假设x(n)代表麦克风阵元实时拾取的原始时域信号,其中,n代表时间标签。
[0063]
具体地,进行短时傅里叶变换的方法如下:
[0064]
对时域信号x(n)进行短时傅里叶变换得到时频域表达:
[0065][0066]
其中,n为帧长,n=512;w(n)为长度512的汉明窗,其中,n代表时间标签,即时间序号,因此w(n)代表每一个对应时间序号n上的值;l为时间帧序号,以帧为单位;k为频带序号,其中,频带是指某个频率对应的信号分量;j代表虚数单位x(l,k)为第m个麦克风信号,在第l帧,第k个频带的频谱。本发明中,使用的汉明窗函数如图2所示。
[0067]
通过上述步骤s1,能够完成时域信号到时频域的变换。
[0068]
s2:进行噪音信号功率谱密度估计,其具体包括:噪音功率谱密度初估计、平稳噪音功率谱密度估计、语音功率谱密度估计以及计算平滑后的噪音功率谱密度。
[0069]
在本步骤中,能够对噪音功率谱密度估计进行3次平滑操作,得到鲁棒性更好的噪音估计,提高语音的真实性。
[0070]
具体地,本步骤s2包括以下步骤:
[0071]
s201:假设采用深度学习估计的时频掩蔽值为m(l,k),对每一个频带k,计算噪音功率谱密度初估计ρ
v
(k)。其中,时频掩蔽值m(l,k)是采用深度学习方法估计得到的0
‑
1之间的掩蔽值,是通过现有模型中采用的方法得到的掩蔽值。
[0072]
噪音功率谱密度初估计ρ
v
(k)的计算公式如下:
[0073]
ρ
v
(k)=αρ
v
(k)+(1
‑
α)(1
‑
m(l,k))|x(l,k)|2[0074]
上述公式表示新的数据输入之后,对噪音功率谱密度的更新。
[0075]
其中,|.|代表取复数的模;α为相邻帧间的平滑因子,其取值范围在0和1之间。
[0076]
在本发明中,优选α=0.95,如果平滑因子的值过小会导致功率谱密度估计变化幅度过大,存在不稳定的缺陷,如果平滑因子的值过高,则能量估计过于平稳,对非平稳噪声建模能力下降。选择该优选的值能够平衡稳定性和对非平稳噪声建模能力。
[0077]
该步骤能够基于时频掩蔽计算噪音功率谱密度初估计,其结果在后续步骤中用于计算噪音功率谱密度的最终结果。
[0078]
s202:估计平稳噪音功率谱密度ρ
min
(k)。
[0079]
平稳噪音功率谱密度ρ
min
(k)的计算公式如下:
[0080]
ρ
min
(k)=αρ
min
(k)+(1
‑
α)min(ρ
v
(k),|x(l,k)|2)
[0081]
上述公式表示新的数据输入之后,对平稳噪音功率谱密度的更新。
[0082]
其中,min()代表取二者中间的小值;α为相邻帧间的平滑因子,与步骤s201中相同。
[0083]
通过该步骤能够追踪信号中的较为平稳的噪音能量,其结果在后续步骤中用于计算噪音功率谱密度的最终结果。
[0084]
s203:估计语音功率谱密度ρ
y
(k)。
[0085]
语音功率谱密度ρ
y
(k)的计算公式如下:
[0086]
ρ
y
(k)=αρ
y
(k)+(1
‑
α)m(l,k)|x(l,k)|2[0087]
上述公式表示新的数据输入之后,对语音功率谱密度的更新。
[0088]
其中,α为相邻帧间的平滑因子,与步骤s201和s202中相同。
[0089]
通过该步骤s203,得到了语音功率谱密度的估计结果。该步骤的结果用以步骤s3计算维纳型噪音抑制因子。
[0090]
s204:计算平滑后的噪音功率谱密度ρ
s
(k)。
[0091]
平滑后的噪音功率谱密度ρ
s
(k)的计算公式如下:
[0092][0093]
在该步骤s203中,采用上述步骤s201和s202得到的噪音功率谱密度初估计和平稳噪音功率谱密度的几何平均值作为最终的平滑后的噪音功率谱密度。该步骤的结果用以步骤s3计算维纳型噪音抑制因子。
[0094]
采用本步骤对噪音功率谱密度进行平滑,其噪音估计结果可以避免噪音功率谱密度过估计,也可以避免对非平稳噪音追踪能力不足的问题,有效平衡噪音抑制与语音失真之间的矛盾。
[0095]
s3:建立维纳型噪音抑制因子,用于区分语音分量和噪音分量。
[0096]
维纳型噪音抑制因子g(l,k)的计算公式如下:
[0097][0098]
其中,max()代表取二者中的大值,其中,第一项为完全根据平滑后的功率谱密度得到的抑制因子,第二项为结合掩蔽估计和平滑后的噪音功率谱密度得到的控制因子,二者选择其中的较大者,可以有效避免语音失真。
[0099]
通过该步骤,能够得到的噪音抑制因子直接作为掩蔽值,用于步骤s4中以得到语音频谱估计。
[0100]
如果在维纳型噪音抑制因子中,语音分量占主导,该抑制因子接近1,噪音的大部分能量被保留;反之,噪音分量占主导,该抑制因子接近0,大部分能量被抑制。因此,通过该抑制因子可以在不破坏语音的前提下,抑制背景噪音。
[0101]
s4:根据维纳型噪音抑制因子,得到目标语音的频域信号,进而获得目标语音时域信号。
[0102]
具体包括以下步骤:
[0103]
s401:根据求解得到的分离矩阵,得到目标语音的频域估计信号:
[0104][0105]
在该步骤中,通过直接对麦克风信号频谱乘以抑制因子,可以达到抑制背景噪音,同时保留语音信号的目的。
[0106]
s402:对频域估计信号进行傅里叶逆变换得到目标语音的时域信号:
[0107][0108]
在该步骤中,时域估计的信号可以通过数模转换直接转为电压信号由扬声器播放出增强后的语音。
[0109]
通过该步骤s4,能够实现目标语音的时域信号的获取。
[0110]
通过本发明的上述步骤s1
‑
s4,可以实现麦克风矩阵信号的分解、信号功率谱密度估计、噪音抑制因子计算和目标语音估计,最终提取目标语音。
[0111]
如图3所示,本发明的一实施方式为一种基于时频掩蔽平滑策略的单声道噪声抑制装置,包括初始化模块1、信号功率谱密度估计模块2、噪音抑制因子计算模块3和目标语音估计模块4。
[0112]
初始化模块1,用于对麦克风的时域信号进行短时傅里叶变换得到时频域表达。
[0113]
初始化模块1还能够用于获取每个麦克风的语音信号,获取的语音信号如下:假设x(n)代表麦克风阵元实时拾取的原始时域信号,其中,n代表时间标签。
[0114]
具体地,进行短时傅里叶变换的方法如下:
[0115]
对时域信号x(n)进行短时傅里叶变换得到时频域表达:
[0116][0117]
其中,n为帧长,n=512;w(n)为长度512的汉明窗,其中,n代表时间标签,即时间序号,因此w(n)代表每一个对应时间序号n上的值;l为时间帧序号,以帧为单位;k为频带序号,其中,频带是指某个频率对应的信号分量;j代表虚数单位x(l,k)为第m个麦克风信号,在第l帧,第k个频带的频谱。本发明中,使用的汉明窗函数如图2所示。
[0118]
通过初始化模块1,能够完成时域信号到时频域的变换。
[0119]
信号功率谱密度估计模块2,用于进行噪音信号功率谱密度估计,其具体包括:噪音功率谱密度初估计、平稳噪音功率谱密度估计、语音功率谱密度估计以及计算平滑后的噪音功率谱密度。
[0120]
在信号功率谱密度估计模块2中,能够对噪音功率谱密度估计进行3次平滑操作,得到鲁棒性更好的噪音估计,提高语音的真实性。
[0121]
具体地,3次平滑操作分别为:
[0122]
1、假设采用深度学习估计的时频掩蔽值为m(l,k),对每一个频带k,计算噪音功率谱密度初估计ρ
v
(k)。其中,时频掩蔽值m(l,k)是采用深度学习方法估计得到的0
‑
1之间的掩蔽值,是通过现有模型中采用的方法得到的掩蔽值。
[0123]
噪音功率谱密度初估计ρ
v
(k)的计算公式如下:
[0124]
ρ
v
(k)=αρ
v
(k)+(1
‑
α)(1
‑
m(l,k))|x(l,k)|2[0125]
上述公式表示新的数据输入之后,对噪音功率谱密度的更新。
[0126]
其中,|.|代表取复数的模;α为相邻帧间的平滑因子,其取值范围在0和1之间。
[0127]
在本发明中,优选α=0.95,如果平滑因子的值过小会导致功率谱密度估计变化幅度过大,存在不稳定的缺陷,如果平滑因子的值过高,则能量估计过于平稳,对非平稳噪声建模能力下降。选择该优选的值能够平衡稳定性和对非平稳噪声建模能力。
[0128]
该步骤能够基于时频掩蔽计算噪音功率谱密度初估计,其结果用于计算噪音功率谱密度的最终结果。
[0129]
2、平稳噪音功率谱密度估计ρ
min
(k):
[0130]
平稳噪音功率谱密度ρ
min
(k)的计算公式如下:
[0131]
ρ
min
(k)=αρ
min
(k)+(1
‑
α)min(ρ
v
(k),|x(l,k)|2)
[0132]
上述公式表示新的数据输入之后,对平稳噪音功率谱密度的更新。
[0133]
其中,min()代表取二者中间的小值;α为相邻帧间的平滑因子,与噪音功率谱密度初估计中相同。
[0134]
通过该步骤能够追踪信号中的较为平稳的噪音能量,其结果在后续步骤中用于计算噪音功率谱密度的最终结果。
[0135]
3、语音功率谱密度估计ρ
y
(k):
[0136]
语音功率谱密度ρ
y
(k)的计算公式如下:
[0137]
ρ
y
(k)=αρ
y
(k)+(1
‑
α)m(l,k)|x(l,k)|2[0138]
上述公式表示新的数据输入之后,对语音功率谱密度的更新。
[0139]
其中,α为相邻帧间的平滑因子,与噪音功率谱密度初估计和平稳噪音功率谱密度估计中相同。
[0140]
通过估计语音功率谱密度,得到了语音功率谱密度的估计结果。该步骤的结果用以计算维纳型噪音抑制因子。
[0141]
此外,对于平滑后的噪音功率谱密度ρ
s
(k):
[0142]
平滑后的噪音功率谱密度ρ
s
(k)的计算公式如下:
[0143][0144]
采用上述得到的噪音功率谱密度初估计和平稳噪音功率谱密度的几何平均值作为最终的平滑后的噪音功率谱密度。其结果用以计算维纳型噪音抑制因子。
[0145]
采用信号功率谱密度估计模块2对噪音功率谱密度进行平滑,其噪音估计结果可以避免噪音功率谱密度过估计,也可以避免对非平稳噪音追踪能力不足的问题,有效平衡噪音抑制与语音失真之间的矛盾。
[0146]
分离矩阵计算模块3用于估计维纳型噪音抑制因子。
[0147]
具体地,维纳型噪音抑制因子g(l,k)的计算公式如下:
[0148][0149]
其中,max()代表取二者中的大值,其中,第一项为语音分量,第二项为噪音分量。
[0150]
通过分离矩阵计算模块3,能够得到的噪音抑制因子直接作为掩蔽值,用于得到语音频谱估计。
[0151]
如果在维纳型噪音抑制因子中,语音分量占主导,该抑制因子接近1,噪音的大部分能量被保留;反之,噪音分量占主导,该抑制因子接近0,大部分能量被抑制。因此,通过该抑制因子可以在不破坏语音的前提下,抑制背景噪音。
[0152]
目标语音估计模块4,用于根据维纳型噪音抑制因子,得到目标语音的频域信号,进而得到目标语音时域信号。
[0153]
具体地,目标语音估计模块4的操作步骤如下:
[0154]
首先,根据求解得到的分离矩阵,得到目标语音的频域估计信号:
[0155][0156]
在该步骤中,通过直接对麦克风信号频谱乘以抑制因子,可以达到抑制背景噪音,同时保留语音信号的目的。
[0157]
其次,对频域估计信号进行傅里叶逆变换得到目标语音的时域信号:
[0158]
[0159]
在该步骤中,时域估计的信号可以通过数模转换直接转为电压信号由扬声器播放出增强后的语音。
[0160]
通过目标语音估计模块4,能够实现目标语音的时域信号的获取。
[0161]
上述实施方式中,初始化模块1、信号功率谱密度估计模块2、噪音抑制因子计算模块3和目标语音估计模块4的这4个模块缺一不可,任一模块的缺失,都会导致目标语音无法提取。
[0162]
本文中应用了具体个例对发明构思进行了详细阐述,以上实施例的说明只是用于帮助理解本发明的核心思想。应当指出,对于本技术领域的普通技术人员来说,在不脱离该发明构思的前提下,所做的任何显而易见的修改、等同替换或其他改进,均应包含在本发明的保护范围之内。