对话检测器
1.相关申请案的交叉引用
2.本技术案要求2019年4月18日申请的第pct/cn2019/083173号pct专利申请案、2019年4月30日申请的第62/840,839号美国临时专利申请案及2019年8月20日申请的第19192553.6号ep专利申请案的优先权,其每一者的全部内容以引用的方式并入本文中。
技术领域
3.本技术案公开大体上涉及音频信号处理,且特定来说涉及对话检测器。
背景技术:
4.对话检测器是多个音频信号处理算法中的关键组件,例如对话增强、降噪及响度计。通常,在当前对话检测器中,输入音频信号首先通过采样率转化或向下混合等手段在预处理组件中转化为统一格式。例如,作为预处理,输入音频信号可经向下混合为单声道音频信号。接下来,将经处理的音频信号分割成短时间帧,并从包含固定数量帧的上下文窗口提取音频特征以描述每一帧的特性。然后,使用机器学习方法构建的分类器经应用以将音频特征自动映射到表示对话的存在的概率的置信度分数。最后,后处理(例如中值或均值滤波器)可经应用以移除或平滑化所获得的置信度分数的非期望的波动。如果置信度分数较高,那么信号将被分类为对话。然后,对话信号可被发送到音频改进装置,例如对话增强器。
技术实现要素:
5.本发明的第一方面涉及一种响应于输入音频信号在对话检测器中提取音频特征的方法,所述方法包括:将所述输入音频信号划分为多个帧;从每一帧提取帧音频特征;确定一组上下文窗口,每一上下文窗口包含环绕当前帧的若干帧;针对每一上下文窗口,基于每一相应上下文中的所述帧的所述帧音频特征,导出所述当前帧的相关上下文音频特征;及串接每一上下文音频特征以形成组合的特征向量以表示所述当前帧。
6.因此,本发明提议使用若干上下文窗口,每一者包含不同数量的帧,以表示不同上下文中的帧,其中具有不同长度的所述上下文窗口将在表示目标帧的音频性质中发挥不同的作用。具有所述不同长度的所述上下文窗口可改进响应速度并改进稳健性。为此目的,本技术案引入一种新的过程,即组合期上下文确定,以确定具有不同长度或范围的多个(例如三个)上下文窗口,例如,短期上下文、中期上下文及长期上下文;然后在所述音频特征提取组件处的所述上下文中提取所述音频特征。
7.在一些实施方案中,帧特征提取组件从划分自所述输入音频信号的多个帧中的每一帧提取帧音频特征(即,帧的音频特征),且组合期上下文确定组件确定每一上下文窗口的长度或范围。然后,基于每一确定的上下文中的所述帧音频特征导出相关的上下文音频特征。然后将每一上下文音频特征串接并形成组合的特征向量以表示当前帧。
8.在一些实施方案中,所述上下文窗口包含短期上下文、中期上下文及长期上下文。所述短期上下文表示所述当前帧周围的局部信息。所述中期上下文进一步含有多个回溯
帧。所述长期上下文进一步含有多个长期历史帧。
9.在一些实施方案中,可预定一或多个上下文的长度或范围(即,相应上下文窗口中的帧数)。例如,如果前瞻缓冲器可用,那么所述短期上下文可含有所述当前帧及前瞻帧。所述中期上下文可含有所述当前帧、所述前瞻帧及所述回溯帧。所述长期上下文可含有所述当前帧、所述前瞻帧、所述回溯帧及所述长期历史帧。在一个实施方案中,所述前瞻帧的长度或范围可经预定为长达23帧,且所述回溯帧的长度或范围可经预定为长达24帧,以及所述长期历史帧的长度或范围可经预定为长达48到96帧。在另一实例中,如果所述前瞻缓冲器不可用,那么所述短期上下文可含有所述当前帧及所述回溯帧的第一部分。所述中期上下文可含有所述当前帧、所述回溯帧的所述第一部分及所述回溯帧的第二部分。所述长期上下文可含有所述当前帧、所述回溯帧的所述第一部分、所述回溯帧的所述第二部分及所述长期历史帧。因此,所述回溯帧的所述第一部分的长度或范围可经预定为长达23帧,且所述回溯帧的所述第二部分的长度或范围可经预定为长达24帧,以及所述长期历史帧的长度或范围可经预定为长达48到96帧。
10.在一些实施方案中,通过分析帧级特征的平稳性,可自适应地确定一或多个上下文的长度或范围。例如,所述自适应确定基于与所述输入音频信号的振幅相关的信息。明确来说,一种自适应地确定所述短期上下文的所述长度或范围的方式是基于强起始点或瞬态检测。在另一实例中,所述自适应确定基于与所述输入音频信号的频谱相关的信息。明确来说,一种自适应确定所述短期上下文的所述长度或范围的方式是基于通过使用贝叶斯(bayesian)信息准则来标识最大频谱不一致性。另外,所述短期上下文可延伸到前瞻及回溯方向两者,或在所述自适应确定实施方案中仅延伸到一个方向。在一些实施方案中,可结合所述自适应确定来预定义所述上下文的所述长度或范围。
11.另外,本技术案提议一种预清洁方法以移除信号中的不相关噪声,以便改进低snr对话中的检测准确度。为此目的,本技术案利用具有时间频率相关增益的向下混合,其中更强调相关信号。
12.在一些实施方案中,首先将输入音频信号划分为多个帧,且然后将左声道及右声道中的帧转化为帧的频谱表示。通过分别将所述频率相关增益应用到所述左声道及所述右声道中的所述频谱来移除所述左声道及所述右声道中的不相关信号,以获得向下混合之后的信号。在一些实施方案中,所述频率相关增益可从协方差矩阵估计。
13.此外,本技术案引入音乐内容检测器,使得可联合考虑音乐置信度分数及语音置信度分数来校正原始对话置信度分数并获得最终校正的对话置信度分数,以显著减少音乐中的假警报。
14.在一些实施方案中,语音内容检测器接收通过使用所述上下文窗口提取的特征,且然后,所述语音内容检测器确定所述语音置信度分数。接下来,所述音乐内容检测器接收通过使用所述上下文窗口提取的特征,且然后,所述音乐内容检测器确定所述音乐置信度分数。所述语音置信度分数与所述音乐置信度分数经组合以获得所述最终对话置信度分数。在一些实施方案中,所述最终对话置信度分数可通过上下文相关参数进行精细化,所述上下文相关参数可基于所述历史上下文中经标识为语音或音乐的帧的比例进行计算。在一些实施方案中,所述历史上下文可长达或长于10秒。
附图说明
15.所包含的附图用于说明的目的,且仅用于提供用于所公开的发明方法、系统及计算机可读媒体的可能的实例及操作。这些附图绝不以任何方式限制所属领域的技术人员在不脱离所公开的实施方式的精神及范围的情况下可作出的形式及细节上的任何改变。
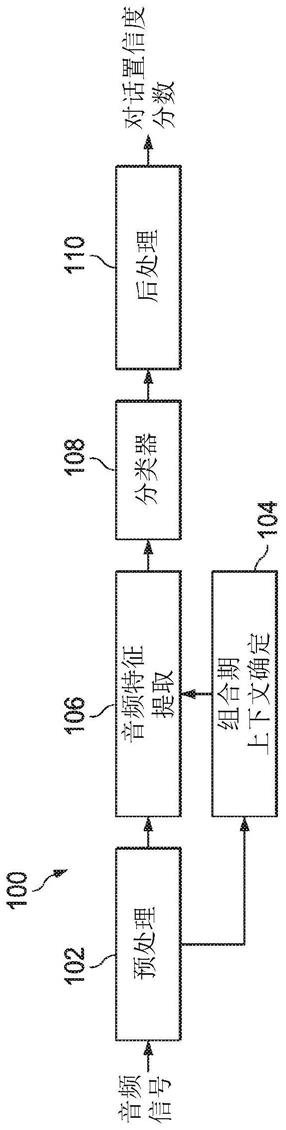
16.图1展示根据一些实施方案的并入组合期上下文确定组件104的对话检测器100的框图。
17.图2展示根据一些实施方案的对话检测器100中的音频特征提取组件102的框图。
18.图3展示用于通过使用组合期上下文确定组件104预定组合期上下文的长度或范围的一些实施方案的方法200的流程图。
19.图4a展示根据一些实施方案的在前瞻缓冲器可用的情况下组合期上下文的预定长度或范围的实例。
20.图4b展示根据一些实施方案的在前瞻缓冲器不可用的情况下组合期上下文的预定长度或范围的实例。
21.图5a展示用于通过使用组合期上下文确定组件104自适应地确定组合期上下文的长度或范围的一些实施方案的方法300的实例的流程图。
22.图5b展示上下文边界搜索范围中所说明的方法300的示意图。
23.图6a展示用于通过使用组合期上下文确定组件104自适应地确定组合期上下文的长度或范围的一些实施方案的方法400的另一实例的流程图。
24.图6b展示贝叶斯信息准则窗口中所说明的方法400的示意图。
25.图7展示根据一些实施方案的在前瞻缓冲器可用的情况下组合期上下文的自适应确定长度或范围的实例。
26.图8展示根据一些实施方案执行的向下混合对话检测器的输入音频信号的方法500的实例的流程图。
27.图9展示根据一些实施方案的进一步集成音乐内容检测器606的对话检测器600的框图。
具体实施方式
28.如上面所提及的,在常规的当前对话检测器中,每一帧由上下文表示,即,包括若干帧(例如32或48帧)的窗口,并依据从此上下文窗口中的帧提取的音频特征进行分类。然而,此类常规对话检测器的一个问题是,它有时可能在检测中引入大的延迟,因为检测器仅可在标识可能对实时应用产生负面影响的若干对话帧之后确定对话是否存在。另外,它不能提取更稳健的节奏特征,这可能有助于区分语音与歌唱或说唱,且因此其可能对对话检测中的稳健性具有负面影响。
29.为了解决这些问题,本技术案公开并入一组不同长度的上下文窗口以在若干尺度上表示帧的技术,其中具有不同长度的上下文窗口将在表示目标帧的音频性质中发挥不同的作用。下面公开实施用于响应于输入音频信号对对话检测器进行音频特征提取的所述技术的方法、系统及计算机可读媒体的一些实例。
30.图1描绘根据一些实施方案的并入组合期上下文窗口确定组件104的对话检测器100的框图。在图1中,预处理组件102接收输入音频信号。在预处理组件102处,输入音频信
号可经向下混合为单声道音频信号。然后将其划分为帧。接下来,组合期上下文确定组件104及音频特征提取组件106分别从预处理组件102接收帧。然后,在音频特征提取组件106处,从每一帧提取帧音频特征。另外,在组合期上下文确定组件104处,确定每一上下文窗口的长度或范围。然后,音频特征提取组件106从组合期确定组件104接收确定结果。接下来,在音频特征提取组件106处,每一上下文窗口中的帧音频特征用于取决于所确定的上下文窗口导出每一上下文特征。然后串接或组合每一上下文特征组并形成联合特征向量。接下来,分类器108从音频特征提取组件106接收所提取的特征向量。在分类器108处,获得表示对话的存在的概率的置信度分数。最后,在后处理组件110处,可通过例如中值滤波器或均值滤波器来平滑化所获得的置信度分数,以移除其非期望的波动。
31.图2描绘根据一些实施方案的对话检测器100中的音频特征提取组件106的框图。明确来说,它描述组合期上下文特征提取及组合。在图2中,在音频特征提取组件106处,通过帧特征提取组件1060从每一所接收的帧提取帧音频特征。然后,在组合期上下文确定组件104处,确定每一上下文窗口(在这种情况下,短期上下文窗口、中期上下文窗口及长期上下文窗口)的长度或范围。接下来,分别基于短期上下文窗口、中期上下文窗口及长期上下文窗口中的帧音频特征导出短期上下文音频特征、中期上下文音频特征及长期上下文音频特征。最后,将这三个上下文特征组串接并形成大维特征向量。例如,假设每一上下文特征是100维,那么所串接的特征将是300维。
32.因此,本技术案使用多个上下文窗口,而不是一个上下文窗口来表示当前帧。在一个实施例中,存在三个上下文窗口,即具有不同长度或范围的短期上下文窗口、中期上下文窗口及长期上下文窗口,以表示当前帧。特定来说,短期上下文表示目标帧周围的局部信息,使得检测器在对话出现时可更快地响应。中期上下文是现存检测器中使用的对应物,因为它可提供用于音频内容分析的合理时间跨度。长期上下文窗口表示更全局的信息,其中仅提取节奏特征,因为短期上下文或中期上下文窗口通常未长至足以提取稳健的节奏特征。也就是说,本技术案添加短期上下文窗口以改进响应速度,并添加长期上下文窗口以改进稳健性。因此,应在特征提取期间确定这三个上下文窗口的长度。为此目的,本技术案引入组合期确定组件以确定短期上下文窗口、中期上下文窗口及长期上下文窗口的长度。
33.在实例中,帧音频特征可包括子带特征或全带特征中的至少一者。子带特征的实例包含:子带频谱能量分布、子带频谱对比度、子带部分突出、梅尔频率倒谱系数(mfcc)、mfcc流量及低音能量。全带特征的实例包含:频谱流量、频谱残差及短时能量。
34.在实例中,上下文音频特征可从一或多个帧音频特征导出。例如,上下文音频特征可包含帧音频特征的统计信息,例如均值、众数、中值、方差或标准差。
35.此外或替代地,上下文音频特征可包含节奏相关特征,例如2d调制特征、节奏强度、节奏清晰度、节奏规律性、平均节奏及/或窗口级相关性(即,上下文级相关性)。
36.帧音频特征及上下文音频特征的上述实例并非详尽的,且可使用各种其它帧音频特征及上下文音频特征来代替所列特征或作为所列特征的补充。
37.图3展示用于通过使用组合期上下文确定组件104预定组合期上下文的长度或范围的一些实施方案的方法200的流程图。在此示范性实施例中,组合期上下文的长度或范围可预定。在一个实例中,如果前瞻缓冲器可用,那么在202处,短期上下文可经确定以仅含有当前帧及少数前瞻帧,其中前瞻帧的长度或范围可经预定义为23帧,因此,短期上下文的总
长度或范围为24帧,以便分析最新的内容。在204处,中期上下文可经确定以含有当前帧、少数前瞻帧及少数回溯帧,其中回溯帧的长度或范围可经预定义为24帧,因此,中期上下文的总长度或范围为48帧。接下来,在206处,长期上下文可经确定以含有当前帧、少数前瞻帧、少数回溯帧及更多的历史帧,其中长期历史帧的长度或范围可经预定义为从48到96帧,因此,长期上下文的总长度或范围为从96帧到144帧,以便具有稳定的节奏特征分析。图4a展示组合期上下文的预定长度或范围的此实例。在另一实例中,如果前瞻缓冲器不可用,那么在208处,短期上下文可经确定以仅含有当前帧及回溯帧的部分,其中回溯帧的部分的长度或范围可经预定义为23帧,因此,短期上下文的总长度或范围为24帧。在210处,中期上下文可经确定以含有当前帧、回溯帧的部分及进一步回溯帧,其中进一步回溯帧的长度或范围可经预定义为24帧,因此,中期上下文的总长度或范围为48帧。接下来,在212处,长期上下文可经确定以含有当前帧、回溯帧的部分、进一步回溯帧及更多的历史帧,其中长期历史帧的长度或范围可经预定义为从48到96帧,因此,长期上下文的总长度或范围为从96帧到144帧。图4b展示组合期上下文的预定长度或范围的此实例。在方法200中,前瞻缓冲器、回溯缓冲器及长期历史的长度或范围都可经预定义。替代地,除了上述数量的帧之外,还可使用其它数量的帧,只要它确保短期上下文仅含有与当前帧具有类似性质的帧,且长期上下文含有足够的历史帧以提取稳健的节奏特征。
38.替代地,通过分析帧级特征的平稳性并相应地将音频帧分组,可在组合期上下文确定组件104中自适应地确定一或多个上下文窗口的长度或范围。图5a描绘用于通过使用组合期上下文确定组件104来自适应地确定组合期上下文窗口的长度或范围的一些实施方案的方法300的实例的流程图。特定来说,以短期上下文为实例来描述方法300。
39.方法300基于强瞬态检测。首先,在302处,使用以下等式(1)计算帧k的短时能量s(k):
[0040][0041]
其中[x
k,0
,
…
,x
k,n
‑1]是帧k的pcm样本。在计算能量之前,还可对样本加窗/加权,且能量可从全带或子带信号导出。
[0042]
然后,在304处,帧能量s(k)被非对称地平滑化,当能量增加时具有快速跟踪系数,且当能量减少时具有缓慢衰减,如等式(2)中所表示:
[0043][0044]
其中是第k个音频帧中的经平滑化的短期能量。参数α是平滑因子。
[0045]
接下来,在306处,在经平滑化的能量包络上应用差分滤波器,且超过给定阈值δ的值可被视为起始点e
onset
(k),如等式(3)中所表示:
[0046][0047]
然后,在308处,e
onset
(k)可使用搜索范围内的短期能量的平均值进一步归一化。接
下来,可在310、312或314处确定用于短期上下文的长度或范围的边界。在310处,将具有最大e
onset
(k)的位置作为上下文边界。在312处,可挑选高于特定阈值(例如0.3)(其可在0到1之间调谐)的峰值e
onset
(k)作为上下文边界。在314处,可考虑e
onset
(k)与先前标识的强峰值之间的距离,而不是阈值。也就是说,只有当它与先前强瞬态具有一定的距离(例如1秒)时,它才将被确定为强瞬态,并被挑选为上下文边界。另外,在314处,如果在搜索范围中没有发现强瞬态,那么将使用整个回溯帧及/或前瞻帧。图5b描绘上下文边界搜索范围中所说明的方法300的示意图。特定来说,它说明音频信号的原始波形、短时能量、归一化之后的差分短时能量及所确定的短期上下文的范围。
[0048]
代替使用振幅信息来确定上下文的范围,上下文的范围的自适应确定也可基于频谱信息。例如,通过使用贝叶斯信息准则(bic),可发现最大的频谱不一致性以确定上下文的范围。图6a描绘基于bic的边界确定的方法400。它还以短期上下文为实例来描述方法400。首先,在402处,bic窗口中的时间戳记t被假设为真实边界,且最好通过在时间t分割的两个分离的高斯模型来表示窗口。然后,在404处,bic窗口中的时间戳记t被假设为不是真实边界,且最好通过仅一个高斯模型来表示窗口。接下来,在406处,使用以下等式(4)计算δbic:
[0049]
δbic(t)=bic(h0)
‑
bic(h1)
ꢀꢀ
(4)
[0050]
其中h0是402处的假设,且h1是404处的假设。图6b展示bic窗口中的实例δbic(t)曲线,其是两个假设之间的对数似然差。然后,在408处,可归一化δbic。接下来,在410处,如果δbic(t)的峰值大于阈值(其可在0到1之间调谐),可选择峰值作为上下文边界的最可能位置。
[0051]
图7展示根据一些实施方案的在前瞻缓冲器可用的情况下自适应确定组合期上下文窗口的长度或范围的实例。特定来说,基于方法300或方法400自适应地确定短期上下文窗口的长度或范围,并基于方法200预定义中期上下文及长期上下文的长度或范围。如图7中所展示,如果前瞻缓冲器可用,那么短期上下文可延伸到前瞻方向及回溯方向两者。替代地,例如,如果前瞻缓冲器不可用(未展示),那么短期上下文可仅延伸到一个方向。根据本技术案的方法300或方法400以短期上下文为实例来描述自适应确定,然而,中期的长度或范围也可以与上述方法300或400类似的方式自适应地确定。
[0052]
如上面所提及的,当前对话检测器应用到立体声信号的l/r上或5.1信号的l/r/c上的单声道向下混合,以便降低计算复杂度。然而,将所有声道混合在一起可降低对话的snr,并损害对话检测准确度。例如,在检测中可能漏掉具有大噪音的对话(例如,在体育比赛中)或密集动作场景中的对话。为了解决这个问题,如公式(5)中所表示,应用中心声道主导向下混合以减少对话拖尾(smearing),因为大多数对话都在5.1信号中的声道c中。
[0053]
m=0.707c+g(l+r)/2
ꢀꢀ
(5)
[0054]
其中c、l、r分别代表中心、左及右声道中每时间谱块(即,每帧及每频格/带)的复数谱,且g是介于0与1之间的参数以减来自l及r的贡献。然而,上述方法适用于5.1信号,但不适用于立体声信号,因为对话通常被视为平移信号,因此在立体声信号中,在l及r中相关。
[0055]
为了解决此问题,本技术案提议一种新的向下混合方法,以移除信号中的不相关噪声,以便使向下混合后的对话更加明显。图8描绘根据一些实施方案执行的向下混合对话
检测器的输入音频信号的方法500的实例。首先,在502,将输入音频信号划分为多个帧。然后,在504处,左声道及右声道中的帧被转化为帧的频谱表示。接下来,在506处,通过如下等式(6)移除不相关信号:
[0056]
m=g1l+g2r
ꢀꢀ
(6)
[0057]
其中l是左声道中帧的频谱表示,且r是右声道中帧的频谱表示,且g1及g2是分别应用到l及r的两种频率相关增益,而不是宽带增益。为简单起见,等式中的频带上的标注被忽略。在一个实施方案中,g1及g2可从协方差矩阵估计,所述协方差矩阵是针对特定持续时间中的每个带计算的(其中仅考虑实部,且也忽略频带上的标注),如等式(7)中所表示:
[0058][0059]
然后,遵循特征向量分析及ngcs中的环境声提取的理念,g1及g2可表示如下。
[0060][0061][0062]
其中a、c及d分别是协方差系数|l|2、re(lr
*
)及|r|2的替代表示,以便简化等式(8)及(9)的表示。在506之后,向下混合m之后的信号将在508处获得。
[0063]
尽管上述方法500是基于立体声信号描述并开发的,但它也可适用于5.1信号。在一个实施方案中,5.1信号可首先转化为具有中心主导向下混合的立体声信号(l
c
及r
c
),如等式(10)及(11)中所表示:
[0064]
l
c
=0.707c+gl
ꢀꢀ
(10)
[0065]
r
c
=0.707c+gr
ꢀꢀ
(11)
[0066]
然后,l
c
及r
c
将遵循方法500来移除不相关噪声。
[0067]
作为移除不相关信号的方法500的补充或替代,还可应用一些其它方法。在一些实施方案中,可通过使用(l+r)/2作为参考噪声信号来应用与回波消除类似的方法来减小中心声道c中的噪声。替代地,可建立nmf频谱基础用于对话或对话及噪声两者,且可应用它们来提取干净的对话分量。
[0068]
此外,在当前检测器中,音乐信号,尤其是a
‑
capella(没有太多音乐背景)中的歌唱声音或与对话具有许多类似的性质的说唱可能被误分类为对话,因此,假警报可能显著增加。申请者发现,针对相同的错误分类的帧,音乐置信度分数也很高。因此,申请者引入与对话检测器并行的音乐分类器,使得音乐置信度分数可用作参考来精细化或校正原始对话置信度分数,从而显著减少音乐中的假警报。
[0069]
图9展示根据一些实施方案的进一步集成音乐内容检测器606的对话检测器600的框图。首先,输入音频信号被划分为多个帧,并通过离散傅里叶变换(dft)602转化为频谱表示。然后,在特征提取组件604处,根据图2所说明的程序提取特征以表示每一帧。接下来,音乐内容检测器606接收所提取的特征以获得音乐置信度分数c
m
(t);同时,语音内容检测器
608还接收所提取的特征以获得语音置信度分数c
s
(t)。另外,可通过中值滤波器或均值滤波器进一步平滑化音乐置信度分数c
m
(t)及语音置信度分数c
s
(t)。此外,在后处理组件610处,音乐置信度分数c
m
(t)及语音置信度分数c
s
(t)被组合以获得最终对话置信度分数特定来说,原始对话置信度分数将被精细化以在后处理组件610处获得精细化的最终对话置信度分数一般来说,如果针对同一帧的音乐置信度分数c
m
(t)也较高,那么原始对话置信度分数可在一定程度上降低。然而,它可能过度降低语音置信度分数c
s
(t),因为如果对话存在有音乐背景,那么真实对话内容也可能生成高对话置信度分数及高音乐置信度分数两者。为了解决这个问题,可应用历史上下文以确定是否可自信地使用音乐置信度分数c
s
(t)来精细化对话置信度分数。如果历史上下文为对话主导的,那么精细化对话置信度分数将更为保守,即,有意忽略音乐置信度分数。因此,在一些实施方案中,最终对话置信度分数通过以下等式(12)进行精细化:
[0070][0071]
其中是帧t处的精细化对话置信度分数,c
s
(t)是语音置信度分数,c
m
(t)是音乐置信度分数,且β是控制音乐置信度分数对最终对话置信度分数影响程度的上下文相关参数。在一个实施方案中,基于在历史上下文中经标识为语音或音乐的帧的比例来计算β。例如,可使用简单的二进制方法将β设置为在历史上下文中经标识为音乐的帧的比率。特定来说,如果上下文为音乐主导的,那么β可设置为1,且如果上下文为对话主导的,那么β可设置为0,如等式(13)中所表示:
[0072][0073]
其中n
m
是音乐帧数,且n是历史上下文中的总帧数;r
th
是阈值,通常设置为0.5,但阈值也可取决于音乐帧生效的积极性程度在0到1之间调节。替代地,β可表示为连续函数,例如,如等式(14)中所说明的线性函数,或如等式(15)中所说明的sigmoid函数:
[0074][0075][0076]
其中a是控制sigmoid函数的形状的比例因子,且在本技术案中可设置为5。另外,在上下文相关参数β的估计中使用的历史上下文可比用于长期特征提取的历史帧长得多,例如,历史上下文的长度或范围可设置为10秒或甚至更长。
[0077]
本文所描述的对话检测器的技术可由一或多个计算装置实施。例如,专用计算装置的控制器可经硬接线以执行所公开的操作或导致此类操作被执行,且可包含持续经编程以执行操作或导致操作被执行的数字电子电路系统,例如一或多个专用集成电路(asic)或
现场可编程门阵列(fpga)。在一些实施方案中,具有定制编程的定制硬接线逻辑、asic及/或fpga经组合以实现所述技术。
[0078]
在一些其它实施方案中,通用计算装置可包含并入中央处理单元(cpu)的控制器,所述中央处理单元(cpu)经编程以导致一或多个所公开的操作依据固件、存储器、其它存储装置或其组合中的程序指令被执行。
[0079]
本文所使用的术语“计算机可读存储媒体”是指存储导致计算机或机器类型以特定方式操作的指令及/或数据的任何媒体。本文所描述的模型、检测器及操作中的任一者可经实施为可由控制器的处理器使用合适的计算机语言执行的软件代码来实施或导致其由所述软件代码实施。软件代码可作为一系列指令存储在用于存储的计算机可读媒体上。合适的计算机可读存储媒体的实例包含随机存取存储器(ram)、只读存储器(rom)、磁性媒体、光学媒体、固态驱动器、快闪存储器及任何其它存储器芯片或盒带。计算机可读存储媒体可为这种存储装置的任意组合。任何此类计算机可读存储媒体可驻留在单个计算装置或整个计算机系统上或内部,且可为系统或网络内的其它计算机可读存储媒体。
[0080]
虽然本技术案的标的物已参考其实施方案具体地展示并描述,但所属领域的技术人员将理解,在不脱离本发明的精神或范围的情况下,可对所公开的实施方案的形式及细节进行更改。附图中说明这些实施方案中的一些的实例,并阐述具体细节以提供对其的透彻理解。应注意,可在没有这些具体细节的部分或全部的情况下实践实施方案。另外,可能未详细描述众所周知的特征以促进清晰易懂。最后,尽管本文已参考一些实施方案讨论优点,但应理解,范围不应受到这些优点的限制。确切来说,应参考所附权利要求确定范围。
[0081]
可从以下列举的实例实施例(eee)来理解本发明的各个方面:
[0082]
1.一种响应于输入音频信号在对话检测器中提取音频特征的方法,所述方法包括:
[0083]
通过帧特征提取组件,从划分自所述输入音频信号的多个帧中的每一帧提取帧特征;
[0084]
通过组合期上下文确定组件确定每一上下文的长度或范围;
[0085]
基于每一确定的上下文中的所述帧特征导出相关的上下文特征;及
[0086]
串接每一上下文特征并形成组合的特征向量以表示当前帧。
[0087]
2.根据eee 1所述的方法,其中所述组合期上下文包含:
[0088]
短期上下文,其表示所述当前帧周围的局部信息;
[0089]
中期上下文,其进一步含有多个回溯帧;及
[0090]
长期上下文,其进一步含有多个长期历史帧。
[0091]
3.根据eee 1或2所述的方法,其中一或多个上下文的所述长度或范围可为预定的。
[0092]
4.根据eee 2或3所述的方法,其中如果前瞻缓冲器可用,那么所述短期上下文含有所述当前帧及前瞻帧;或如果所述前瞻缓冲器不可用,那么所述短期上下文含有所述当前帧及所述回溯帧的第一部分。
[0093]
5.根据eee 2或3所述的方法,其中如果所述前瞻缓冲器可用,那么所述中期上下文含有所述当前帧、所述前瞻帧及所述回溯帧;或如果所述前瞻缓冲器不可用,那么所述中期上下文含有所述当前帧、所述回溯帧的所述第一部分及所述回溯帧的第二部分。
[0094]
6.根据eee 2或3所述的方法,其中如果所述前瞻缓冲器可用,那么所述长期上下文含有所述当前帧、所述前瞻帧、所述回溯帧及长期历史帧;或如果所述前瞻缓冲器不可用,那么所述长期上下文含有所述当前帧、所述回溯帧的所述第一部分、所述回溯帧的所述第二部分及所述长期历史帧。
[0095]
7.根据eee 1或2所述的方法,其中可自适应地确定一或多个上下文的所述长度或范围。
[0096]
8.根据eee 7所述的方法,其中可通过分析帧级特征的平稳性来自适应地确定一或多个上下文的所述长度或范围。
[0097]
9.根据eee 8所述的方法,其中一或多个上下文的所述长度或范围的所述自适应确定基于与所述输入音频信号的振幅相关的信息。
[0098]
10.根据eee 2或9所述的方法,其中短期上下文的所述长度或范围的所述自适应确定包括:
[0099]
计算所述输入音频信号的所述多个帧中的帧的短时能量;
[0100]
平滑化所述经计算的短时能量;
[0101]
确定所述帧的所述经平滑化短时能量与先前帧的所述经平滑化短时能量之间的差;
[0102]
基于所述差是否满足阈值来确定起始点;
[0103]
归一化所述起始点;
[0104]
通过以下步骤中的一者来确定用于所述短期上下文的所述长度或范围的边界:
[0105]
将具有最大起始点的位置作为边界;或
[0106]
基于峰值是否满足阈值,将峰值起始点作为边界;或
[0107]
基于所述阈值及所述起始点与紧接在所述起始点前的强瞬态之间的距离两者,将峰值起始点作为边界。
[0108]
11.根据eee 8所述的方法,其中一或多个上下文的所述长度或范围的所述自适应确定基于与所述输入音频信号的频谱相关的信息。
[0109]
12.根据eee 2或11所述的方法,其中短期上下文的所述长度或范围的所述自适应确定包括:
[0110]
假设贝叶斯信息准则窗口中的时间戳记是用于所述短期上下文的所述长度或范围的真实边界;
[0111]
假设贝叶斯信息准则窗口中的所述时间戳记不是用于所述短期上下文的所述长度或范围的所述真实边界;
[0112]
确定所述两个假设之间的差分贝叶斯信息准则;
[0113]
归一化所述差分贝叶斯信息准则;及
[0114]
基于所述峰值是否满足阈值将差分贝叶斯信息准则的峰值视为所述短期上下文的所述长度或范围的所述真实边界的位置。
[0115]
13.根据eee 2、7到12中任一eee所述的方法,其中所述短期上下文可延伸到前瞻及回溯方向两者,或仅延伸到一个方向。
[0116]
14.根据前述eee中任一eee所述的方法,其中可结合所述自适应确定来预定义所述上下文的所述长度或范围。
[0117]
15.一种向下混合对话检测器的输入音频信号的方法,所述方法包括:
[0118]
将输入音频信号划分为多个帧;
[0119]
将左声道及右声道中的帧转化为帧的频谱表示;
[0120]
通过分别将频率相关增益应用到所述左声道及所述右声道中的频谱来移除所述左声道及所述右声道中的不相关信号;
[0121]
获得向下混合信号,及
[0122]
使用前述eee 1到14中任一eee所述的方法将所述向下混合信号馈送到对话检测器。
[0123]
16.根据eee 15所述的方法,其中所述频率相关增益可从协方差矩阵估计。
[0124]
17.一种分类对话检测器的输入音频信号的方法,所述方法包括:
[0125]
通过语音内容检测器接收根据前述eee 1到14中任一eee所述的方法提取的特征;
[0126]
通过所述语音内容检测器确定语音置信度分数;及
[0127]
通过音乐内容检测器接收根据前述eee 1到14中任一eee所述的方法提取的特征;
[0128]
通过所述音乐内容检测器确定音乐置信度分数;及
[0129]
组合所述语音置信度分数及所述音乐置信度分数以获得最终对话置信度分数。
[0130]
18.根据eee 17所述的方法,其中所述最终对话置信度分数可通过上下文相关参数进行精细化。
[0131]
19.根据eee 18所述的方法,其中所述上下文相关参数可基于在历史上下文中经标识为语音或音乐的帧的比例进行计算。
[0132]
20.根据eee 19所述的方法,其中所述历史上下文可长达或长于10秒。