1.本发明属于计算机技术领域,具体涉及到基于层标准化的递归跳跃连接深度学习音乐自动生成方法。
技术背景
2.音乐创作就是指音乐专业人员或作曲家创造具有音乐美的乐曲的复杂的精神与技能生产过程。主要的方式是按照不同音节对应时间序列关系进行组合,如旋律和和声,并配以相宜的节奏进行组织产生的具有特殊音色和纹理动态声波。音乐创作通常是由受过专业音乐培训和教育的作曲家创造具有音乐美的乐曲,是一项极其复杂的技术方案。
3.随着人工智能深度学习算法在图像识别、视频检测、自然语言处理和语音处理等方面的广泛应用,深度学习模型技术的发展完善及应用的场景正在越来越多地被挖掘。深度学习算法是一种新兴的多层神经网络降维算法,通过组建含有多个隐层的神经网络深层模型,对输入的高维数据逐层提取特征,以发现数据的低维嵌套结构,形成更加抽象有效的高层表示。
4.深度学习对于音乐创作与生成的场景,模型通过学习音乐数据集中得音乐,从而生成与数据集音乐类型类似的新音乐,使得音乐创作对于更多的人能够完成,也能够为人类带来更多不同类型和不同风格的优美音乐。
5.现阶段,运用在音乐自动生方面的神经网络大致有下面这几种,recurrentneuralnetwork,它是一种前馈是神经网络通过新增表示时间维度信息的参数以及相关机制,使神经网络不仅可以基于当前数据而且可以基于先前数据来学习,在rnn系统中,前一个输入和后一个输入关联,rnn是一个在时间上传递的神经网络,时间作为其深度的度量。循环网络通常具有相同的输入层和输出层,因为循环网络预测下一个项目是以迭代的方式用作下一个输入,以便产生序列,因此rnn是音乐创作中一项重要的实现方式。但是在rnn中,会存在梯度消失或者爆炸,使得rnn比较难优化,lstm(longshort
‑
term memory)引入门控和梯度裁剪技术增大网络存储,缓解了rnn中出现的梯度消失的技术问题,但并没能很好地解决这一问题。
6.近年来出现了一种新的神经网络,叫做transformer,实验表明transformer比其lstm神经网络可以更好地缓解这一问题。但是由于音乐是具有前后关联性特征的艺术作品,而transformer并不具有递归的特性。
7.在音乐自动生成领域,当前需迫切解决的一个技术问题是提供一种符合音乐前后关联性特征、缓解梯度下降或爆破技术问题的音乐自动生成方法。
技术实现要素:
8.本发明所要解决的技术问题在于克服上述现有技术的不足,提供了一种基于层标准化的递归跳跃连接深度学习音乐自动生成方法。
9.解决上述技术问题所采用的技术方案是由下述步骤组成:
个片段在第n
‑
1层的隐向量,τ和n为有限的正整数,隐向量长度为l,维度为d,表示两个向量的拼接运算,stop_gradient(
·
)表示停止梯度函数;将第τ
‑
1个片段的隐向量和第τ个片段的隐向量一同作为训练数据,模拟递归的形式。
24.按下式确定第τ个片段在第n层的查询向量第τ个片段在第n层的键值向量第τ个片段在第n层的值向量
[0025][0026][0027][0028]
式中表示每一层的查询向量q的转化矩阵,表示每一层的键向量k的转化矩阵,表示每一层的值向量v的转化矩阵,用相对位置编码方式定位事件在第τ个片段中的位置。
[0029]
按下式确定多头注意力中第i个头的注意力特征:
[0030][0031]
式中masked_softmax(
·
)表示先对于无效的输入,用一个负无穷的值代替这个输入,进行逻辑回归计算,r表示输入片段的相对位置编码,i为有限的正整数。
[0032]
按下式确定多头注意力特征值
[0033][0034]
式中表示与第n层的第τ个片段中事件相关的权重矩阵。
[0035]
按照下式确定层标准化递归跳跃连接的输出
[0036][0037][0038]
式中layernormal(
·
)表示将上一层的输出进行归一化处理,表示第τ个片段在第n层第一次层标准化的结果。
[0039]
按下式确定多专家层的输出值
[0040][0041]
式中g(
·
)
m
代表可训练路由选择器的输出结果的第m个元素,e(
·
)
m
表示第m个专家的非线性转换,e表示专家模块的个数,e和m为有限的正整数。
[0042]
重复上述步骤,至损失率小于0.1时,结束训练,得到训练好的音乐自动生成神经网络。
[0043]
(5)自动生成音乐文件
[0044]
运行训练好的音乐自动生成网络,自动生成和训练集音乐类型相符的音乐文件。
[0045]
在本发明的(3)构建音乐自动生成网络步骤中,所述的第一标准化求和层由求和模块、标准化模块构成,1个求和模块与1个标准化模块串联构成1个标准化求和模块,2个或3个标准化求和模块串联构成第一标准化求和层。
[0046]
在本发明的(3)构建音乐自动生成网络步骤中,所述的多专家层由路由模块、专家模块、合并模块连接构成,路由模块的输出与并联的专家模块的输入相连,并联的专家模块的输出与合并模块的输入相连,合并模块的输出与第二标准化求和层的输入相连;所述的专家模块有e个,e取值为有限的正整数。
[0047]
本发明的专家模块有e个,e取值最佳为[8,16]。
[0048]
本发明的第二标准化求和层与第一标准化求和层的结构相同。
[0049]
在本发明的(4)训练音乐自动生成网络步骤的式(1)中,所述的n表示层数,n取值最佳为[12,24];在式(2)中,所述的i取值最佳为[8,16]。
[0050]
本发明将乐器数字接口数据类型的音乐文件,作为训练音乐自动生成网络的训练集。在音乐自动生成网络输入训练集中的数据之前,对数据进行预处理,将乐器数字接口数据类型的音乐文件用音高、音强、音长、位置、小节、节奏、和弦事件进行表示,音乐训练生成网络是由transformer
‑
xl神经网络作为基本的网络结构,在其内部添加了基于层标准化的递归网络连接层和多专家层,与transformer神经网络相比,增加了递归的模式,进一步缓解了梯度消失或爆破的情况,优化了整体性能,可以生成更优质的音乐。
附图说明
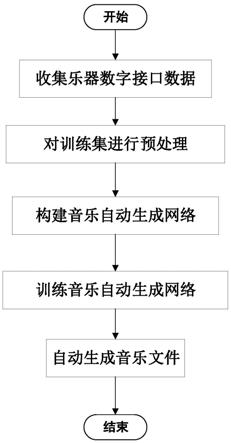
[0051]
图1本发明实施1的流程图。
[0052]
图2音乐生成网络模型图的结构示意图。
[0053]
图3是多专家层5的结构示意图。
具体实施方式
[0054]
下面结合附图和实施例对本发明进一步详细说明,但本发明不限于下述的实施方式。
[0055]
实施例1
[0056]
以选取的日本流行音乐钢琴曲200个为例,作为训练集,本实施例的基于层标准化的递归跳跃连接深度学习音乐自动生成方法由下述步骤组成(参见图1)。
[0057]
(1)收集乐器数字接口数据
[0058]
收集键盘乐器、固定音乐风格的乐器数字接口类型的音乐文件作为音乐自动生成网络的训练。
[0059]
(2)对训练集进行预处理
[0060]
将乐器数字接口文件中的电子乐谱用事件表示,事件分为:音高、音强、音长、位置、小节、节奏、和弦事件,音高事件表示乐器数字接口类型音乐文件的音高的开始,音强事
件表示音符事件的动态级别——对应于感知响度,音长事件表示音符的持续时间,位置事件表示小节中的一个确切的位置,小节事件表示乐谱中一个小节的开始和结束,节奏事件表示节奏的局部变化,由节奏类事件和节奏值事件组合表示,每一拍都添加了节奏事件,和弦事件表示小节中的和弦,由根音符和弦特性组成;根音符分为:和弦c、和弦c#、和弦d、和弦d#、和弦e、和弦f、和弦f#、和弦g、和弦g#、和弦a、和弦a#、和弦b;弦特性分为:大调和弦、小调和弦、减调和弦、增调和弦、属和弦,二者结合有60个和弦事件,每一个节奏事件和和弦事件都会存在一个位置事件在它们前面。
[0061]
运用可追踪节拍和强拍的循环神经网络估计音乐文件中的强拍的位置,标注乐谱中的小节,通过相同的模型,追踪节拍的位置,标注位置信息,通过基于启发式规则的和弦识别的方法,识别所述的60个和弦事件。
[0062]
将乐器数字接口文件的电子乐谱中每一个小节的乐谱按下述的方式转换成事件的形式,一个小节放在开头表示一个乐谱中一个小节的开始,一个小节放在结尾表示一个乐谱中一个小节的结束,在两个小节事件中间的事件和顺序为位置、和弦、位置、节奏类、节奏值、位置、音强、音高、音长,来表示一个乐谱的小节中每一个位置上音符的特征,将乐器数字接口中的电子乐谱,用上述事件形式表示,作为训练网络的输入。
[0063]
(3)构建音乐自动生成网络
[0064]
在图2中,本实施例的音乐自动生成网络模型由输入嵌套层1、位置编码层2、多头注意力层3、第一标准化求和层4、多专家层5、第二标准化求和层6、线性回归模型7、逻辑回归模型8连接构成。输入嵌套层1的输出与位置编码层2的输入相连,位置编码层2的输出与多头注意力层3的输入相连,多头注意力层3的输出与第一标准化求和层4的输入相连,第一标准化求和层4的输出与多专家层5的输入相连,多专家层5的输出与第二标准化求和层6的输入相连,第二标准化求和层6的输出与线性回归模型7的输入相连,线性回归模型7的输出与逻辑回归模型8的输入相连,构建成音乐自动生成网络。
[0065]
本实施例的第一标准化求和层4由求和模块、标准化模块构成,1个求和模块与1个标准化模块串联构成1个标准化求和模块,2个标准化求和模块串联构成第一标准化求和层4。
[0066]
在图3中,本实施例的多专家层5由路由模块5
‑
1、专家模块5
‑
2、合并模块5
‑
3连接构成,路由模块5
‑
1的输出与并联的专家模块5
‑
2的输入相连,并联的专家模块5
‑
2的输出与合并模块5
‑
3的输入相连,合并模块5
‑
3的输出与第二标准化求和层6的输入相连;所述的专家模块5
‑
2有e个,e取值为有限的正整数,本实施例的e取值为12,第二标准化求和层6与第一标准化求和层4的结构相同。
[0067]
(4)训练音乐自动生成网络
[0068]
将(1)步骤中的音乐事件作为音乐自动生成网络的输入,在训练的过程中,将每一个输入的序列分成固定长度为l的段。
[0069]
将给定的段输入到音乐自动生成网络中,进入到网络各层;
[0070]
按下式确定两个隐向量序列沿长度方向的拼接
[0071]
[0072]
式中τ为片段,n为层数,表示第τ个片段在第n
‑
1层的隐向量,表示第τ
‑
1个片段在第n
‑
1层的隐向量,τ和n为有限的正整数,本实施例的n取值为16,隐向量长度为l,维度为d,表示两个向量的拼接运算,stop_gradient(
·
)表示停止梯度函数;将第τ
‑
1个片段的隐向量和第τ个片段的隐向量一同作为训练数据,模拟递归的形式;
[0073]
按下式确定第τ个片段在第n层的查询向量第τ个片段在第n层的键值向量第τ个片段在第n层的值向量
[0074][0075][0076][0077]
式中示每一层的查询向量q的转化矩阵,表示每一层的键向量k的转化矩阵,表示每一层的值向量v的转化矩阵,用相对位置编码方式定位事件在第τ个片段中的位置;
[0078]
按下式确定多头注意力中第i个头的注意力特征:
[0079][0080]
式中masked_softmax(
·
)表示先对于无效的输入,用一个负无穷的值代替这个输入,进行逻辑回归计算,r表示输入片段的相对位置编码,i为有限的正整数,本实施例的i取值为12。
[0081]
按下式确定多头注意力特征值
[0082][0083]
式中表示与第n层的第τ个片段中事件相关的权重矩阵。
[0084]
按照下式确定层标准化递归跳跃连接的输出
[0085][0086][0087]
式中layernormal(
·
)表示将上一层的输出进行归一化处理,表示第τ个片段在第n层第一次层标准化的结果。
[0088]
按下式确定多专家层的输出值
[0089]
[0090]
式中g(
·
)
m
代表可训练路由选择器的输出结果的第m个元素,e(
·
)
m
表示第m个专家的非线性转换,e表示专家模块的个数,e和m为有限的正整数,本实施例的e取值为12。
[0091]
重复上述步骤,至损失率小于0.1时,结束训练,得到训练好的音乐自动生成神经网络。
[0092]
(5)自动生成音乐文件
[0093]
运行训练好的音乐自动生成网络,自动生成和训练集音乐类型相符的音乐文件。
[0094]
完成基于层标准化的递归跳跃连接深度学习音乐自动生成方法。
[0095]
实施例2
[0096]
以选取的日本流行音乐钢琴曲200个为例,作为训练集,本实施例的基于层标准化的递归跳跃连接深度学习音乐自动生成方法由下述步骤组成。
[0097]
(1)收集乐器数字接口数据
[0098]
该步骤与实施例1相同。
[0099]
(2)对训练集进行预处理
[0100]
该步骤与实施例1相同。
[0101]
(3)构建音乐自动生成网络
[0102]
音乐自动生成网络模型由输入嵌套层1、位置编码层2、多头注意力层3、第一标准化求和层4、多专家层5、第二标准化求和层6、线性回归模型7、逻辑回归模型8连接构成。输入嵌套层1的输出与位置编码层2的输入相连,位置编码层2的输出与多头注意力层3的输入相连,多头注意力层3的输出与第一标准化求和层4的输入相连,第一标准化求和层4的输出与多专家层5的输入相连,多专家层5的输出与第二标准化求和层6的输入相连,第二标准化求和层6的输出与线性回归模型7的输入相连,线性回归模型7的输出与逻辑回归模型8的输入相连,构建成音乐自动生成网络。
[0103]
本实施例的第一标准化求和层4由求和模块、标准化模块构成,1个求和模块与1个标准化模块串联构成1个标准化求和模块,2个标准化求和模块串联构成第一标准化求和层4。
[0104]
本实施例的多专家层5由路由模块5
‑
1、专家模块5
‑
2、合并模块5
‑
3连接构成,路由模块5
‑
1的输出与并联的专家模块5
‑
2的输入相连,并联的专家模块5
‑
2的输出与合并模块5
‑
3的输入相连,合并模块5
‑
3的输出与第二标准化求和层6的输入相连;所述的专家模块5
‑
2有e个,e取值为有限的正整数,本实施例的e取值为8,第二标准化求和层6与第一标准化求和层4的结构相同。
[0105]
重复上述步骤,至损失率小于0.1时,结束训练,得到训练好的音乐自动生成神经网络。
[0106]
(4)训练音乐自动生成网络
[0107]
将(1)步骤中的音乐事件作为音乐自动生成网络的输入,在训练的过程中,将每一个输入的序列分成固定长度为l的段。
[0108]
将给定的段输入到音乐自动生成网络中,进入到网络各层;
[0109]
按下式确定两个隐向量序列沿长度方向的拼接
[0110][0111]
式中τ为片段,n为层数,表示第τ个片段在第n
‑
1层的隐向量,表示第τ
‑
1个片段在第n
‑
1层的隐向量,τ和n为有限的正整数,本实施例的n取值为12,隐向量长度为l,维度为d,表示两个向量的拼接运算,stop_gradient(
·
)表示停止梯度函数;将第τ
‑
1个片段的隐向量和第τ个片段的隐向量一同作为训练数据,模拟递归的形式;
[0112]
按下式确定第τ个片段在第n层的查询向量第τ个片段在第n层的键值向量第τ个片段在第n层的值向量
[0113][0114][0115][0116]
式中表示每一层的查询向量q的转化矩阵,表示每一层的键向量k的转化矩阵,表示每一层的值向量v的转化矩阵,用相对位置编码方式定位事件在第τ个片段中的位置;
[0117]
按下式确定多头注意力中第i个头的注意力特征:
[0118][0119]
式中masked_softmax(
·
)表示先对于无效的输入,用一个负无穷的值代替这个输入,进行逻辑回归计算,r表示输入片段的相对位置编码,i为有限的正整数,本实施例的i取值为8。
[0120]
按下式确定多头注意力特征值
[0121][0122]
式中表示与第n层的第τ个片段中事件相关的权重矩阵。
[0123]
按照下式确定层标准化递归跳跃连接的输出
[0124][0125][0126]
式中layernormal(
·
)表示将上一层的输出进行归一化处理,表示第τ个片段在第n层第一次层标准化的结果。
[0127]
按下式确定多专家层的输出值
[0128][0129]
式中g(
·
)
m
代表可训练路由选择器的输出结果的第m个元素,e(
·
)
m
表示第m个专家的非线性转换,e表示专家模块的个数,e和m为有限的正整数,本实施例的e取值为8。
[0130]
重复上述步骤,至损失率小于0.1时,结束训练,得到训练好的音乐自动生成神经网络。
[0131]
其它步骤与实施例1相同。完成基于层标准化的递归跳跃连接深度学习音乐自动生成方法。
[0132]
实施例3
[0133]
以选取的日本流行音乐钢琴曲200个为例,作为训练集,本实施例的基于层标准化的递归跳跃连接深度学习音乐自动生成方法由下述步骤组成。
[0134]
(1)收集乐器数字接口数据
[0135]
该步骤与实施例1相同。
[0136]
(2)对训练集进行预处理
[0137]
该步骤与实施例1相同。
[0138]
(3)构建音乐自动生成网络
[0139]
音乐自动生成网络模型由输入嵌套层1、位置编码层2、多头注意力层3、第一标准化求和层4、多专家层5、第二标准化求和层6、线性回归模型7、逻辑回归模型8连接构成。输入嵌套层1的输出与位置编码层2的输入相连,位置编码层2的输出与多头注意力层3的输入相连,多头注意力层3的输出与第一标准化求和层4的输入相连,第一标准化求和层4的输出与多专家层5的输入相连,多专家层5的输出与第二标准化求和层6的输入相连,第二标准化求和层6的输出与线性回归模型7的输入相连,线性回归模型7的输出与逻辑回归模型8的输入相连,构建成音乐自动生成网络。
[0140]
本实施例的第一标准化求和层4由求和模块、标准化模块构成,1个求和模块与1个标准化模块串联构成1个标准化求和模块,2个标准化求和模块串联构成第一标准化求和层4。
[0141]
本实施例的多专家层5由路由模块5
‑
1、专家模块5
‑
2、合并模块5
‑
3连接构成,路由模块5
‑
1的输出与并联的专家模块5
‑
2的输入相连,并联的专家模块5
‑
2的输出与合并模块5
‑
3的输入相连,合并模块5
‑
3的输出与第二标准化求和层6的输入相连;所述的专家模块5
‑
2有e个,e取值为有限的正整数,本实施例的e取值为16,第二标准化求和层6与第一标准化求和层4的结构相同。
[0142]
重复上述步骤,至损失率小于0.1时,结束训练,得到训练好的音乐自动生成神经网络。
[0143]
(4)训练音乐自动生成网络
[0144]
将(1)步骤中的音乐事件作为音乐自动生成网络的输入,在训练的过程中,将每一个输入的序列分成固定长度为l的段。
[0145]
将给定的段输入到音乐自动生成网络中,进入到网络各层;
[0146]
按下式确定两个隐向量序列沿长度方向的拼接
[0147][0148]
式中τ为片段,n为层数,表示第τ个片段在第n
‑
1层的隐向量,表示第τ
‑
1个片段在第n
‑
1层的隐向量,τ和n为有限的正整数,本实施例的n取值为24隐向量长度为l,维度为d,表示两个向量的拼接运算,stop_gradient(
·
)表示停止梯度函数;将第τ
‑
1个片段的隐向量和第τ个片段的隐向量一同作为训练数据,模拟递归的形式;
[0149]
按下式确定第τ个片段在第n层的查询向量第τ个片段在第n层的键值向量第τ个片段在第n层的值向量
[0150][0151][0152][0153]
式中表示每一层的查询向量q的转化矩阵,表示每一层的键向量k的转化矩阵,表示每一层的值向量v的转化矩阵,用相对位置编码方式定位事件在第τ个片段中的位置;
[0154]
按下式确定多头注意力中第i个头的注意力特征:
[0155][0156]
式中masked_softmax(
·
)表示先对于无效的输入,用一个负无穷的值代替这个输入,进行逻辑回归计算,r表示输入片段的相对位置编码,i为有限的正整数,本实施例的i为i取值为16。
[0157]
按下式确定多头注意力特征值
[0158][0159]
式中表示与第n层的第τ个片段中事件相关的权重矩阵;
[0160]
按照下式确定层标准化递归跳跃连接的输出
[0161][0162][0163]
式中layernormal(
·
)表示将上一层的输出进行归一化处理,表示第τ个片段在第n层第一次层标准化的结果。
[0164]
按下式确定多专家层的输出值
[0165][0166]
式中g(
·
)
m
代表可训练路由选择器的输出结果的第m个元素,e(
·
)
m
表示第m个专家的非线性转换,e表示专家模块的个数,e和m为有限的正整数,本实施例的e取值为16。
[0167]
重复上述步骤,至损失率小于0.1时,结束训练,得到训练好的音乐自动生成神经网络。
[0168]
其它步骤与实施例1相同。完成基于层标准化的递归跳跃连接深度学习音乐自动生成方法。
[0169]
实施例4
[0170]
在以上的实施例1~3的(3)构建音乐自动生成网络步骤为:音乐自动生成网络模型由输入嵌套层1、位置编码层2、多头注意力层3、第一标准化求和层4、多专家层5、第二标准化求和层6、线性回归模型7、逻辑回归模型8连接构成。输入嵌套层1的输出与位置编码层2的输入相连,位置编码层2的输出与多头注意力层3的输入相连,多头注意力层3的输出与第一标准化求和层4的输入相连,第一标准化求和层4的输出与多专家层5的输入相连,多专家层5的输出与第二标准化求和层6的输入相连,第二标准化求和层6的输出与线性回归模型7的输入相连,线性回归模型7的输出与逻辑回归模型8的输入相连,构建成音乐自动生成网络。
[0171]
本实施例的第一标准化求和层4由求和模块、标准化模块构成,1个求和模块与1个标准化模块串联构成1个标准化求和模块,3个标准化求和模块串联构成第一标准化求和层4。该步骤的其它步骤与相应的实施例相同。
[0172]
其它步骤与相应的实施例相同。完成基于层标准化的递归跳跃连接深度学习音乐自动生成方法。