1.本发明涉及语音识别技术领域,具体涉及一种用于车载的语音识别方法及系统。
背景技术:
2.为方便用户的使用,目前的车载终端集成了语音识别等交互功能。通过接收并识别用户发出的语音指令,可以执行该语音指令对应的车载动作,例如用户发送语音命令“打开蓝牙”,车载终端可以识别该指令,执行与“打开蓝牙”对应的开蓝牙的车载动作,但是当车上有多个人说话时,车载终端无法确认出语音指令的发出者,使得语音识别不够准确,容易发生误操作。
技术实现要素:
3.本发明提供了一种用于车载的语音识别方法及系统,解决了现有技术中识别准确率不高的技术问题。
4.为了解决上述技术问题,本发明第一方面提供了一种用于车载的语音识别方法,包括:
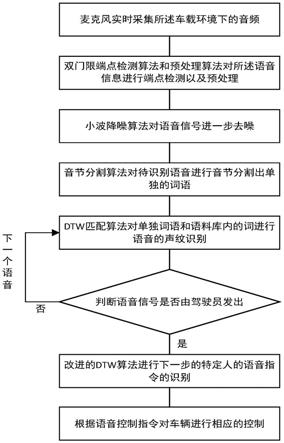
5.s1:采集当前的语音音频信号;
6.s2:对采集的语音音频信号进行预处理,具体包括:采用回声消除算法抑制采集的语音音频信号中的车载环境自噪声;
7.s3:对预处理之后的语音音频信号通过双门限端点检测算法进行语音段的端点检测,提取出语音段;
8.s4:采用小波降噪算法对提取出的语音段进一步去噪,获得待识别语音信号;
9.s5:通过音节分割算法将待识别语音信号分割成单独词语;
10.s6:采用模式匹配方法将分割得到的单独词语与预先构建的语料库中语音指令对应的词语进行匹配,识别语音信号是否由驾驶员发出,当识别出语音信号由驾驶员发出时,进一步采用dtw算法识别语音信号对应的指令,其中,预先构建的语料库中包含驾驶员的语音指令、驾驶员语音指令对应的文本内容以及文本对应的词语、其他人的语音指令、其他人语音指令对应的文本内容以及文本对应的词语,语料库中所有语音指令对应的文本预先通过声纹识别方法得到,文本对应的词语通过音节分割算法得到。
11.在一种实施方式中,步骤s5包括:
12.s5.1:对采集的语音音频信号进行分帧处理后进行短时傅里叶变换,并计算在频域下的短时能量;
13.s5.2:计算每帧语音信号的频能比,得到语音信号频能比曲线,进而得到语音信号的频能比包络;
14.s5.3:分别利用smooth算法和滑动平均算法对语音信号的频能比包络进行曲线的平滑处理;
15.s5.4:根据平滑处理后的频能比包络的峰值个数计算音节个数;
16.s5.5:结合音节个数,利用设定阈值的方法对语音信号进行音节分割,获得与待识别语音信号对应的单独词语。
17.在一种实施方式中,步骤s5.2包括:
18.通过计算语音信号在290
‑
4000hz范围内的短时能量与所有频率范围内的短时能量的比值,得到语音信号频能比曲线;
19.对语音信号频能比曲线进行平滑处理得到语音信号的频能比包络。
20.在一种实施方式中,步骤s5.4包括:将平滑处理后的频能比包络的峰值个数作为音节个数。
21.在一种实施方式中,步骤s5.5中,设定阈值的切分段数与音节的个数相同,将计算得到的每一段语音的频能比的平均值作为阈值,将超过阈值的点作为临界点,将相邻的临界点取平均值后作为切分点。
22.在一种实施方式中,步骤s6中采用模式匹配方法将分割得到的单独词语与预先构建的语料库中语音指令对应的词语进行匹配,识别语音信号是否由驾驶员发出,包括:
23.对待识别语音分割出的单独词语与语料库中的单独词语进行匹配计算,将匹配出的距离最短的人的语音作为声纹识别得到的说话人的结果,识别出语音信号的发出者是否为驾驶员。
24.在一种实施方式中,当识别出语音信号由驾驶员发出时,进一步识别语音信号对应的指令,包括:
25.当识别出语音信号由驾驶员发出时,采用dtw算法将分割出的单独词语与语料库中单独词语分别进行匹配,将每一个与分割出的单独词语匹配出的距离最短的目标单独词语进行组合,以组合后的词语对应的语音指令作为指令识别结果。
26.在一种实施方式中,在步骤s6之后,所述方法还包括:根据识别出的语音指令生成控制指令。
27.基于同样的发明构思,本发明第二方面提供了一种用于车载的语音识别系统,包括:
28.语音采集模块,用于采集当前的语音音频信号;
29.自噪声抑制程序模块,用于对采集的语音音频信号进行预处理,具体包括:采用回声消除算法抑制采集的语音音频信号中的车载环境自噪声;
30.信号前处理模块,用于对预处理之后的语音音频信号通过双门限端点检测算法进行语音段的端点检测,提取出语音段;
31.降噪处理模块,用于采用小波降噪算法对提取出的语音段进一步去噪,获得待识别语音信号;
32.音节分割模块,用于通过音节分割算法将待识别语音信号分割成单独词语;
33.语音识别模块,用于采用模式匹配方法将分割得到的单独词语与预先构建的语料库中语音指令对应的词语进行匹配,识别语音信号是否由驾驶员发出,当识别出语音信号由驾驶员发出时,进一步采用dtw算法识别语音信号对应的指令,其中,预先构建的语料库中包含驾驶员的语音指令、驾驶员语音指令对应的文本内容以及文本对应的词语、其他人的语音指令、其他人语音指令对应的文本内容以及文本对应的词语,语料库中所有语音指令对应的文本预先通过声纹识别方法得到,文本对应的词语通过音节分割算法得到。
34.在一种实施方式中,所述系统包括指令发布模块,用于根据识别出的语音指令生成控制指令。
35.本技术实施例中的上述一个或多个技术方案,至少具有如下一种或多种技术效果:
36.本发明提供的一种用于车载的语音识别方法,在对采集的语音音频信号进行自噪声抑制、语音端提取和小波降噪后,通过音节分割算法将待识别语音信号分割成单独词语,通过单独词语与语音库中存储的词语的匹配,有利于提高识别精度,由于语料库中预先存储驾驶员和其他非驾驶员的语音指令,以及通过声纹识别算法得到的与语音指令对应的文本、通过音节分割算法分割得到的与文本对应的词语,在进行语音识别时,则可以将待识别的语音信号分割出的单独词语与语料库中的词语进行对比,匹配出的距离最短的人的语音作为声纹识别的说话人的结果,如果满足是驾驶员语音指令的条件,则表明语音由驾驶员发出,否则为非驾驶员,从而可以识别出语音信号是否由驾驶员发出,提高了识别的准确性,进一步地,当识别出语音信号由驾驶员发出时,还进一步识别语音信号对应的指令,以进行相应的控制。
附图说明
37.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
38.图1是本发明实施例中一种用于车载的语音识别方法的流程图;
39.图2是本发明实施例中一种用于车载的语音识别系统的结构框图;
40.图3是本发明实施例中利用音节分割算法将待识别语音信号进行分割的流程图。
具体实施方式
41.本发明提供的一种车载语音识别方法及系统,首先采集当前的语音音频信号,然后对采集的语音音频信号进行自噪声抑制、前端信号处理及端点检测;接着进行小波降噪,再采用音节分割算法将待识别语音信号分割成单独词语,最后对所述语音信号进行语音识别。
42.主要创新点包括:
43.1)采用音节分割算法对待识别语音信号进行音节自动划分,划分得到单独的词语,以供后续语音识别用,以提高识别的精度。
44.2)对语音指令进行个性化识别控制,语料库中预先存储有驾驶员和其他非驾驶员的语音指令,以及语音指令对应的文本和单独词语,在进行语音识别时,首先采用模式匹配方法将采集的语音音频信号的单独词语与语料库中经同样处理过的词语进行匹配计算,匹配出的距离最短的人的语音作为声纹识别的说话人的结果,从而识别出语音音频是否由驾驶员发出,并在当识别出的是驾驶员的语音指令时,利用改进的dtw算法进行下一步的特定人的语音指令的识别,识别出语音指令的具体内容。
45.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例
中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
46.实施例一
47.本实施例提供了一种用于车载的语音识别方法,包括:
48.s1:采集当前的语音音频信号;
49.s2:对采集的语音音频信号进行预处理,具体包括:采用回声消除算法抑制采集的语音音频信号中的车载环境自噪声;
50.s3:对预处理之后的语音音频信号通过双门限端点检测算法进行语音段的端点检测,提取出语音段;
51.s4:采用小波降噪算法对提取出的语音段进一步去噪,获得待识别语音信号;
52.s5:通过音节分割算法将待识别语音信号分割成单独词语;
53.s6:采用模式匹配方法将分割得到的单独词语与预先构建的语料库中语音指令对应的词语进行匹配,识别语音信号是否由驾驶员发出,当识别出语音信号由驾驶员发出时,进一步采用dtw算法识别语音信号对应的指令,其中,预先构建的语料库中包含驾驶员的语音指令、驾驶员语音指令对应的文本内容以及文本对应的词语、其他人的语音指令、其他人语音指令对应的文本内容以及文本对应的词语,语料库中所有语音指令对应的文本预先通过声纹识别方法得到,文本对应的词语通过音节分割算法得到。
54.具体实施过程中,步骤s1中可以通过麦克风采集位于车辆乘坐空间内的用户的音频数据(语音音频信号);
55.步骤s2根据回声消除算法抑制采集的音频信号中的车载环境自噪声;回声消除的全称是声学回声消除。声学回声是指设备自身扬声器播放的声音经不同的路径一次或多次反射后进入麦克风所产生的回声集合,也可称作设备自噪声。用户通过语音同设备进行交互的时候,回声信号和干净的语音信号混合,这会恶化采集到的语音信号的信噪比,严重干扰后续的信号处理和识别的效果。所以原始麦克风信号要先通过回声消除算法,消除设备自噪声,以达到提升信噪比的目的。回声消除主要的原理是采用自适应滤波技术,动态的实时跟踪车内的声学信道,参考音经过这个信道的滤波,模拟出传到麦克风处的回声,最后原始的麦克风信号减掉这个回声信号,达到消除车载设备自噪声的目的。
56.步骤s3利用双门限端点检测算法对所述语音信息进行预处理以及端点检测;并通过预处理算法对音频信号进行预加重,分帧和加窗,使分帧后的语音信号整体更加平稳,使语音信号每一帧的时域信号能更好的满足傅里叶变换处理的周期性要求。
57.设原始信号为x(n),加窗运算定义为:
58.y(n)=x(n)*ω(n)
ꢀꢀꢀ
(1)
59.汉明窗函数:
[0060][0061]
其中y(n)是加窗后信号,ω(n)是窗函数。n是汉明窗的长度,n是时间。
[0062]
步骤s4通过小波降噪算法对语音信号进一步去噪,去除车载环境特定噪声;小波变换可解决很多fourier不能解决的问题,尤其在非平稳信号中,小波变换优势明显。
[0063]
步骤s5采用基于元音检测的音节分割算法进行单词分割,首先对于语音信号的短时傅里叶变换结果进行频能比的计算,再经过平滑处理得到的频能比的图像,计算语音段中音节的个数是根据元音占据了一个音节中的主要能量,而且元音的频率通常在290
‑
4000hz之间这两个特点来进行估算。以波峰的个数作为音节的个数,然后设定阈值对该语音段进行音节的分割,直到设定的阈值使语音段分段的段数和音节的个数相同,作为音节分割的结果。
[0064]
步骤s6中预先构建的语料库中包括特定驾驶员录入的语音以及通过声纹识别得到的语音的文本内容、采用音节分割算法得到的词语,同样地,还包括除驾驶员外的其他的语音以及对应的文本和词语。
[0065]
具体的识别过程主要包括两个部分,第一是识别语音信号是不是驾驶员发出的,具体地通过模式匹配算法将待识别语音信号分割出的单独词语与语料库中的词语进行匹配,看是否满足匹配条件,具体过程包括:将待识别语音信号分割出的单独词语与语料库中所有词语进行dtw距离的计算,取距离最短的孤立词所对应的人作为声纹识别的结果,即,将与分割出的单独词语具有最短距离的语料库中词语所对应的人作为识别出的人,以打开空调指令为例,进行音节分割后,得到四个单独的词语:“打”“开”“空”“调”,一般情况下,上述四个词语进行匹配时,都会对应驾驶员。也有的情况会对应不同的人,例如分别对应“驾驶员”,“用户a”“驾驶员”“用户b”,此时,可以取对应相同人最多的人作为识别的结果,该例中取对应的人为驾驶员作为最终的声纹识别结果。匹配条件实际是指一种最大可能性对应条件。通过上述方法可以识别出语音是否由驾驶员发出。第二,对识别出是驾驶员的语音信号进行语音指令的识别,识别出是何种指令。
[0066]
本发明提供的方法能够将采集的语音信号进行音节自动划分成单独词,并判断接收到的语音信号是否为驾驶员发出,避免其他人发出的声音被系统误接收从而执行错误的命令,并且能够针对特定人进行语音指令的识别。
[0067]
在一种实施方式中,步骤s5包括:
[0068]
s5.1:对采集的语音音频信号进行分帧处理后进行短时傅里叶变换,并计算在频域下的短时能量;
[0069]
s5.2:计算每帧语音信号的频能比,得到语音信号频能比曲线,进而得到语音信号的频能比包络;
[0070]
s5.3:分别利用smooth算法和滑动平均算法对语音信号的频能比包络进行曲线的平滑处理;
[0071]
s5.4:根据平滑处理后的频能比包络的峰值个数计算音节个数;
[0072]
s5.5:结合音节个数,利用设定阈值的方法对语音信号进行音节分割,获得与待识别语音信号对应的单独词语。
[0073]
具体地,请参见图3,为利用音节分割算法将待识别语音信号进行分割的流程图。音节分割算法一般用于端点检测领域,本技术创新性地将其引入声纹识别中,可以提高识别准确率和鲁棒性。
[0074]
在一种实施方式中,步骤s5.2包括:
[0075]
通过计算语音信号在290
‑
4000hz范围内的短时能量与所有频率范围内的短时能量的比值,得到语音信号频能比曲线;
[0076]
对语音信号频能比曲线进行平滑处理得到语音信号的频能比包络。
[0077]
在一种实施方式中,步骤s5.4包括:将平滑处理后的频能比包络的峰值个数作为音节个数。
[0078]
在一种实施方式中,步骤s5.5中,设定阈值的切分段数与音节的个数相同,将计算得到的每一段语音的频能比的平均值作为阈值,将超过阈值的点作为临界点,将相邻的临界点取平均值后作为切分点。
[0079]
具体实施过程中,频能比表示一帧语音信号在某个频带范围内的短时能量与所有频率范围内的短时能量的比值,表达式为:
[0080][0081]
其中,s(f
k
)为每一帧语音信号对应于频率为f
k
的短时能量;f
k1
‑
f
kn
为频带的范围。表达式的分子为每一帧信号在频带范围内的能量,分母为全频率范围内的能量。由于元音的频率范围为290
‑
4000hz,所以频能比表达式中的f
k1
的值为290,f
kn
的值为4000。以波峰的个数作为音节的个数,然后设定阈值对该语音段进行音节的分割,直到设定的阈值使语音段分段的段数和音节的个数相同,作为音节分割的结果。具体步骤如下:
[0082]
1)短时傅里叶变换:利用语音信号是短时平稳的特点,先对语音信号进行分帧处理,取出不同帧做短时傅里叶变换,并计算在频域下的短时能量。
[0083]
2)频能比计算:根据元音所处的频率范围是290
‑
4000hz之间的特点,计算每帧语音信号的频能比,通过计算语音信号在290
‑
4000hz范围内的短时能量与所有频率范围内的短时能量的比值,得到语音信号频能比曲线,进而可以得到语音信号的频能比包络。
[0084]
3)平滑处理:分别利用smooth算法和滑动平均算法对语音段的频能比包络进行曲线的平滑处理。
[0085]
4)计算音节个数:由于一个元音段占据了一个音节的主要能量,其音节个数等价于其频能比包络的峰值个数,故通过计算出峰值个数作为音节的个数。
[0086]
5)音节切分:结合音节个数,利用设定阈值的方法对语音段进行音节的分割,且设定阈值的切分段数与音节的个数相同,计算每一段语音的频能比的平均值作为阈值,取超过平均值的几个临界点,将相邻的临界点取平均值作为切分所在处。
[0087]
在一种实施方式中,步骤s6中采用模式匹配方法将分割得到的单独词语与预先构建的语料库中语音指令对应的词语进行匹配,识别语音信号是否由驾驶员发出,包括:
[0088]
对待识别语音分割出的单独词语与语料库中的单独词语进行匹配计算,将匹配出的距离最短的人的语音作为声纹识别得到的说话人的结果,识别出语音信号的发出者是否为驾驶员。
[0089]
具体实施过程中,对待识别语音采用前文音节分割算法进行音节分割,分割出单独的词语,比如将“打开蓝牙”分割成“打”、“开”、“蓝”、“牙”,然后对其进行mfcc特征参数的提取,即对分割之后的单独的词语对应的音频文件做mfcc特征提取,具体做法是通过一组三角窗滤波器对信号的功率谱进行滤波,来模拟人耳的掩蔽效应;上述特征提取是在进行dtw算法之前的一个前处理部分,由语音识别模块来完成,通过特征提取可以使得音频信号能够更接近真实人耳的信号,从而提高匹配计算的准确性,进而用dtw匹配算法对分割出的单独词语和语料库内经同样处理过的词语进行匹配计算。
[0090]
其中,语音音频信号的参数信息中包含语音信号的时间信息、能量信息。
[0091]
在一种实施方式中,当识别出语音信号由驾驶员发出时,进一步识别语音信号对应的指令,包括:
[0092]
当识别出语音信号由驾驶员发出时,采用dtw算法将分割出的单独词语与语料库中单独词语分别进行匹配,将每一个与分割出的单独词语匹配出的距离最短的目标单独词语进行组合,以组合后的词语对应的语音指令作为指令识别结果。
[0093]
具体来说,本发明中采用的声纹识别方法,主要是识别文本内容以及是不是驾驶员说的话。当识别出的不是驾驶员的语音指令时,则不对该语音信号进行下一步的语音指令的识别。
[0094]
为了进一步提高识别的准确性,语料库中存储了大量用户的语音和对应的词语,即包含了丰富与车载驾驶相关的词语,在识别语音信号的具体内容时,由于同一人的不同词距离比不同人相同词的距离小一些,为避免产生误差,可以将待识别语音的词语与用户库(为语料库的一部分,由非驾驶员的音频和文本构成,且用户库中包括大量用户的丰富的孤立词,不包括驾驶员指令)进行匹配,再将每一个孤立词匹配出的结果组合得到最后的指令作为识别结果。
[0095]
在一种实施方式中,在步骤s6之后,根据识别出的语音指令生成控制指令。
[0096]
生成控制指令后,则可以对车辆进行相应的控制。
[0097]
请参见图1,为具体实施例中一种用于车载的语音识别方法的流程图,在语音识别过程中,判断是否满足驾驶员语音指令的条件,如果不满足,则对下一个语音进行识别。如果满足,则采用改进的dtw算法进行下一步的特定人的语音指令的识别。再根据识别出的语音指令生成控制指令,生成控制指令后,则可以对车辆进行相应的控制。
[0098]
在现在技术中,通常是根据直接采集音频数据进行语音控制,从而,当驾驶员未进行语音控制操作而环境音中包含语音指令时,环境音中由其他人发出语音指令将会对车辆进行误操作,从而存在语音控制准确率低的技术问题。而本发明通过从音频数据中提取出特定人的语音控制指令,进而根据语音控制指令对车辆进行相应控制,有效地避免了上述问题的发生,只有在驾驶员的语音控制操作的情况下,才会采集音频数据并根据音频数据对车辆进行相应的个性化控制,提高了语音控制的准确率。
[0099]
基于同样的发明构思,本发明还提供了一种与实施例一中用于车载的语音识别方法对应的系统,具体参见实施例二。
[0100]
实施例二
[0101]
本实施例提供了一种用于车载的语音识别系统,包括:
[0102]
语音采集模块,用于采集当前的语音音频信号;
[0103]
自噪声抑制程序模块,用于对采集的语音音频信号进行预处理,具体包括:采用回声消除算法抑制采集的语音音频信号中的车载环境自噪声;
[0104]
信号前处理模块,用于对预处理之后的语音音频信号通过双门限端点检测算法进行语音段的端点检测,提取出语音段;
[0105]
降噪处理模块,用于采用小波降噪算法对提取出的语音段进一步去噪,获得待识别语音信号;
[0106]
音节分割模块,用于通过音节分割算法将待识别语音信号分割成单独词语;
[0107]
语音识别模块,用于采用模式匹配方法将分割得到的单独词语与预先构建的语料库中语音指令对应的词语进行匹配,识别语音信号是否由驾驶员发出,当识别出语音信号由驾驶员发出时,进一步采用dtw算法识别语音信号对应的指令,其中,预先构建的语料库中包含驾驶员的语音指令、驾驶员语音指令对应的文本内容以及文本对应的词语、其他人的语音指令、其他人语音指令对应的文本内容以及文本对应的词语,语料库中所有语音指令对应的文本预先通过声纹识别方法得到,文本对应的词语通过音节分割算法得到。
[0108]
在一种实施方式中,所述系统包括指令发布模块,用于根据识别出的语音指令生成控制指令。
[0109]
请参见图2,为用于车载的语音识别系统的结构框图,系统整体分为音信信号处理模块、音节分割模块、语音识别模块和指令发布模块,其中,音频信号处理模块包括语音采集模块、自噪声抑制程序模块、信号前处理模块、降噪处理模块。
[0110]
本发明提供了一种车载语音识别方法及系统,可以对用户发出的音频信息进行声纹识别以及文本内容识别,指令包括开关空调,开关蓝牙,开关音乐,调节音量,接打电话等常用控制指令,可判断该指令是不是驾驶员发出的,如果识别系统判别出是驾驶员发出的指令,则进一步识别并通过控制单元执行该指令,如果不是驾驶员发出的指令,则忽略该指令。通过音节自动划分算法的嵌入可以提高识别准确率和鲁棒性。
[0111]
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例做出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
[0112]
显然,本领域的技术人员可以对本发明实施例进行各种改动和变型而不脱离本发明实施例的精神和范围。这样,倘若本发明实施例的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。