1.本发明属于语音识别技术领域,具体涉及一种基于注意力的多通道说话人确认方法。
背景技术:
2.近年来,自动说话人确认(automatic speaker verification,asv)的性能得到显著提高,如基于i
‑
vector和基于深度神经网络的方法(deep neural network,dnn)发展迅速,然而这些进展是在干扰较小的近距离交谈场景下实现的。随着智能设备的快速发展,对远场语音交互的需求将继续增长,由于语音信号的衰减、噪声干扰以及空间混响,包括asv在内的远场语音处理任务仍然具有挑战性。
3.为解决上述的挑战性问题,在asv系统的单通道和多通道前端提出了许多降噪、去混响以及语音增强的方法,麦克风阵列也是提高asv性能的一种重要方法。然而,当说话人和麦克风阵列之间的距离增大时,语音质量显著下降,因此无论向阵列中添加多少麦克风,asv的性能在物理上都是有上限的。与固定麦克风阵列相比,ad
‑
hoc(自组织)麦克风阵列由一组随机放置在声学环境中的麦克风节点组成,提供了更多的灵活性,并允许用户使用他们自己的移动设备虚拟形成麦克风阵列系统。近年来,ad
‑
hoc麦克风阵列被广泛应用于语音分离以及语音识别等领域。
4.与传统的麦克风阵列设置不同,ad
‑
hoc麦克风阵列的麦克风的空间排列和数量事先不可知,这阻碍了传统的说话人确认技术在ad
‑
hoc麦克风阵列下的应用。
技术实现要素:
5.为了克服现有技术的不足,本发明提供了一种自组织麦克风阵列下基于注意力的多通道说话人确认方法,在单通道自动说话人确认系统的基础上,加入通道间处理模块,使其在自组织麦克风阵列下进行远场声纹确认。包括如下步骤:1)在单通道asv系统的池化层之后加入了基于残差自注意力的通道间处理层和全局融合层以充分利用多通道信息进行说话人识别:通道间处理层旨在学习通道权重,全局融合层融合所有通道的信息;2)为了使噪声通道的通道权重为零,将残差自注意模块中的softmax算子改进为sparsemax算子。在libri
‑
adhoc
‑
simu数据集上的结果表明,sparsemax的多通道asv系统实现了低于oracle one
‑
best基线20%多的等错误率;在libri
‑
adhoc40数据集上的结果表明,sparsemax的多通道asv系统实现了低于oracle one
‑
best基线30%多的eer,实现了优越的性能。
6.本发明解决其技术问题所采用的技术方案包括如下步骤:
7.步骤1:构建单通道说话人确认系统;
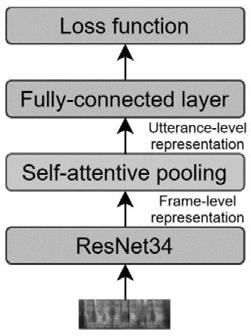
8.所述单通道说话人确认系统网络结构包括三部分:前端残差卷积神经网络resnet、自注意力池化sap层和全连接层;resnet将原始特征转换为高级抽象表示,接在resnet后的sap层输出单个句子级表示,之后,全连接层将单个句子级表示处理为句子级说话人嵌入;单通道说话人确认系统采用端到端的方式和角度原型损失函数进行联合优化;
9.步骤2:构建多通道说话人确认系统;
10.所述多通道说话人确认系统是在c个并行的单通道系统的sap层之后设置多个级联的基于残差自注意力的通道间处理层和全局融合层,在全局融合层后设置全连接层;
11.步骤2
‑
1:基于残差自注意力的通道间处理层;
12.所述多个级联的基于残差自注意力的通道间处理层的输入为c个并行的单通道系统的sap层输出的句子级表示,输出为通道加权的句子级表示;
13.用x=[x1,...,x
c
]表示通道间处理层的输入,其中表示第c个通道的句子级别特征,其中c表示通道数,d表示特征维数;
[0014]
假设自注意力的注意力头个数为h,对于每一个注意力头,输入特征x分别转换为维度e的查询矩阵、键矩阵、值矩阵,如式(1)所示:
[0015][0016]
其中,d
k
=e/h,i表示第i个注意力头;矩阵q、k、v分别表示查询矩阵、键矩阵、值矩阵,都属于域k∈{k,q,v}为模型参数;
[0017]
在每个注意力头中,通过将查询矩阵和键矩阵相乘得到跨通道相似度矩阵;将softmax矩阵用sparsemax算子替换,应用到跨通道相似度矩阵的每一列获得注意力矩阵
[0018][0019]
其中,prev表示来自前一个通道处理层的注意力得分;
[0020]
再将值矩阵v
i
乘以注意力矩阵得到第i个注意力头的输出h
i
:
[0021]
h
i
=a
i
·
v
i
ꢀꢀ
(3)
[0022]
将h
i
进行连接,得到注意力层的输出z:
[0023]
z=concat[h1,h2,...,h
h
]w
o
ꢀꢀ
(4)
[0024]
其中,表示可学习的权重矩阵;
[0025]
将z输出到具有relu激活的前馈神经网络ffn中,ffn的输出即为当前通道间处理层的输出;
[0026]
步骤2
‑
2:全局融合层;
[0027]
经过多个基于残差自注意力的通道间处理层后,输入到全局融合层;所述全局融合层由一个跨通道的多头残差自注意力模块和一个平均池化层组成,对所有通道信息进行融合;
[0028]
步骤2
‑
3:全局融合层的输出再经过全连接层,得到最终的输出。
[0029]
进一步地,所述sparsemax算子被定义为:
[0030][0031]
其中,表示一个(k
‑
1)维的向量;sparsemax将输入向量z和p的欧几里得距离最小化,表示一个稀疏向量,其解有以下的形式:
[0032]
sparsemax
i
(z)=max(z
i
‑
τ(z),0)
ꢀꢀ
(6)
[0033]
其中,用于找到软阈值,z的排序坐标z
(1)
≥z
(2)
≥...≥z
(k)
,定义:
[0034]
k(z):=max{k∈[k]|1+kz
(k)
>∑
j≤k
z
(j)
},则:
[0035][0036]
本发明的有益效果如下:
[0037]
1.本发明提出了一种ad
‑
hoc麦克风阵列下的多通道asv系统,相比于传统的多通道asv系统,不需要知道麦克风的分布和数量,并且也可以利用移动设备如手机等组成ad
‑
hoc阵列,在实际中更具有灵活性。
[0038]
2.本发明使用sparsemax算子,使得噪声通道的通道权重为零,进一步提升了系统的性能。
附图说明
[0039]
图1为本发明的单通道说话人确认系统网络结构。
[0040]
图2为本发明基于注意力的多通道asv系统框图。
[0041]
图3为本发明的通道间处理层结构图。
[0042]
图4为本发明的全局融合层结构图。
具体实施方式
[0043]
下面结合附图和实施例对本发明进一步说明。
[0044]
为了进一步提高asv系统在远场场景下的性能,ad
‑
hoc麦克风阵列近年来被广泛研究,然而,ad
‑
hoc麦克风阵列的麦克风空间排列和数量事先不可知,会阻碍传统的说话人确认技术在ad
‑
hoc麦克风阵列下的应用。为此我们在单通道asv模型的基础上,提出ad
‑
hoc麦克风阵列下的基于注意力的多通道说话人确认技术,在其池化层之后加入了基于残差自注意力的通道间处理层和全局融合层以更好地提取通道信息,并替换了残差自注意模块中的softmax算子为sparsemax算子,使得噪声通道的通道权重为零,实现了更优越的性能。
[0045]
一种自组织麦克风阵列下基于注意力的多通道说话人确认方法,包括如下步骤:
[0046]
步骤1:构建单通道说话人确认系统;
[0047]
所述单通道说话人确认系统网络结构包括三部分:前端残差卷积神经网络(residual convolution neural network,resnet)、自注意力池化sap(self
‑
attentive pooling,sap)层和全连接层;resnet将原始特征转换为高级抽象表示,接在resnet后的sap层输出单个句子级表示,之后,全连接层将单个句子级表示处理为更抽象的句子级说话人嵌入;单通道说话人确认系统采用端到端的方式和角度原型损失函数进行联合优化;
[0048]
步骤2:构建多通道说话人确认系统;
[0049]
所述多通道说话人确认系统是在c个并行的单通道系统的sap层之后设置多个级联的基于残差自注意力的通道间处理层和全局融合层,在全局融合层后设置全连接层;
[0050]
步骤2
‑
1:基于残差自注意力的通道间处理层;
[0051]
所述多个级联的基于残差自注意力的通道间处理层的输入为c个并行的单通道系统的sap层输出的句子级表示,输出为通道加权的句子级表示;采用沿通道维度的多头残差自注意力机制来计算权重,以提取跨通道信息;其中残差自注意力层将前一层的原始注意
力得分作为当前注意力函数的附加残差得分;
[0052]
用x=[x1,...,x
c
]表示通道间处理层的输入,其中表示第c个通道的句子级别特征,其中c表示通道数,d表示特征维数;
[0053]
假设自注意力的注意力头个数为h,对于每一个注意力头,输入特征x分别转换为维度e的查询矩阵、键矩阵、值矩阵,如式(1)所示:
[0054][0055]
其中,d
k
=e/h,i表示第i个注意力头;矩阵q、k、v分别表示查询矩阵、键矩阵、值矩阵,都属于域k∈{k,q,v}为模型参数;
[0056]
在每个注意力头中,通过将查询矩阵和键矩阵相乘得到跨通道相似度矩阵;在原注意头的计算中,softmax算子输出的元素永远非零,不利于通道选择,如果一些通道有很强的的噪声,在权重非零时往往会损坏系统;因此将softmax矩阵用sparsemax算子替换,应用到跨通道相似度矩阵的每一列获得注意力矩阵
[0057][0058]
其中,prev表示来自前一个通道处理层的注意力得分;
[0059]
再将值矩阵v
i
乘以注意力矩阵得到第i个注意力头的输出h
i
:
[0060]
h
i
=a
i
·
v
i
ꢀꢀ
(3)
[0061]
将h
i
进行连接,得到得到注意力层的输出z:
[0062]
z=concat[h1,h2,...,h
h
]w
o
ꢀꢀ
(4)
[0063]
其中,表示可学习的权重矩阵;;
[0064]
将z输出到具有relu激活的前馈神经网络ffn中,ffn的输出即为当前通道间处理层的输出;在跨通道多头自注意力层和ffn层的输入和输出之间应用了残差连接,以缓解梯度消失问题;
[0065]
步骤2
‑
2:全局融合层;
[0066]
经过多个基于残差自注意力的通道间处理层后,输入到全局融合层;所述全局融合层由一个跨通道的多头残差自注意力模块和一个平均池化层组成,对所有通道信息进行融合;
[0067]
步骤2
‑
3:全局融合层的输出再经过全连接层,得到最终的输出。
[0068]
进一步地,所述sparsemax算子被定义为:
[0069][0070]
其中,表示一个(k
‑
1)维的向量;sparsemax将输入向量z和p的欧几里得距离最小化,表示一个稀疏向量,其解有以下的形式:
[0071]
sparsemax
i
(z)=max(z
i
‑
τ(z),0)
ꢀꢀ
(6)
[0072]
其中,用于找到软阈值,z的排序坐标z
(1)
≥z
(2)
≥...≥z
(k)
,定义:
[0073]
k(z):=max{k∈[k]|1+kz
(k)
>∑
j≤k
z
(j)
},则:
[0074][0075]
具体实施例:
[0076]
(1)数据准备
[0077]
实验使用三种数据集:librispeech语料库,ad
‑
hoc麦克风阵列模拟下的librispeech(libri
‑
adhoc
‑
simu),现实场景中由40个同分布的麦克风接收器组成的ad
‑
hoc麦克风阵列收集到的重播的librispeech数据(libri
‑
adhoc
‑
40)。
[0078]
librispeech包含超过1000小时的英语演讲,在实验中,选择包含2338个说话人的960小时的数据用来训练单通道asv系统,选择包含40个说话人的10小时的数据用作开发集。
[0079]
libri
‑
adhoc
‑
simu使用librispeech的子集“train
‑
clean
‑
100”作为训练数据,其中包含251个说话人;使用“dev
‑
clean”子集作为开发集,“test
‑
clean”作为测试集,分别包含40个不同的说话人。对于每一个话语,都会模拟一个房间,房间的长度和宽度是从[5,15]米的范围中随机选取,房间高度是从[2.7,4]米的范围内随机选取,房间内随机放置多个麦克风和一个扬声器,并限制源和墙之间的距离大于0.2米,源和麦克风之间的距离至少为0.3米。使用图像源模型来模拟混响环境,并从[0.2,0.4]秒范围内选择t
60
,使用扩散噪声生成器来模拟不相关的扩散噪声,用于训练集和开发集的噪声源是一个包含超过20000个噪声片段的大规模噪声库,用于测试的噪声源是来自chime
‑
3和noisex
‑
92数据库的噪声片段。随机生成20个通道用于训练,20、30和40个通道用于测试。
[0080]
libri
‑
adhoc40通过在大房间中播放“train
‑
clean
‑
100”,“dev
‑
clean”,“test
‑
clean”来采集数据,采集环境是一个真正的办公室环境,包含扬声器和40个麦克风,具有强烈的混响和较小的附加噪声,扬声器和麦克风之间的距离在[0.8,7.4]米之间。训练集和测试集中麦克风和扬声器的位置不同,我们为每个训练集和开发集的话语随机选择20个通道,为每个测试集话语选择20、30、40个通道,对应为三种测试场景。
[0081]
(2)模型训练
[0082]
图1表示单通道模型结构,将残差块宽度设为{16,32,64,128},全连接层中的嵌入大小为512。图2在多通道asv系统上加入了通道间处理层和全局融合层,实验中堆叠4个通道间处理层,每个自注意力层和fft层的输出维度均为256,每个注意力层中注意力头的个数为4。
[0083]
在训练过程中,从每个话语中随机提取一个固定长度为2秒时间段,使用宽度为25ms和步长为10ms汉明窗来提取语谱,使用40维的梅尔滤波器作为输入,并应用平均和方差标准化(mean and variance normalisation,mvn)。对于每一轮的训练,随机采样每个说话人最多100个话语,以减少类不平衡,不进行数据增强,采用adam优化器,初始学习率为0.001,每10轮减少5%。训练时,首先,单通道asv系统在librispeech语料库上训练200轮,然后固定单通道asv参数并送到多通道asv系统,最后分别用libri
‑
adhoc
‑
simu和libri
‑
adhoc40数据训练训练多通道asv系统。
[0084]
经过训练,在每个测试段以固定间隔采样5个4秒的时间段,并计算每个测试段之间所有可能的组合(5
×
5=25)之间的相似度,使用25个相似度的平均值作为得分。安排测试集中的所有话语以得到6861780个试验,其中包含183922个正例和6677858个反例。
[0085]
(3)实验结果
[0086]
表1在libri
‑
adhoc
‑
simu数据上的eer(%)对比
[0087][0088]
表2在libri
‑
adhoc40数据上的eer(%)对比
[0089][0090]
首先搭建了一个oracle one
‑
best基线用来与多通道asv系统进行对比,它选择物理上最接近声源的通道作为单通道asv模型的输入。
[0091]
表1在libri
‑
adhoc
‑
simu数据集上进行对比,“ch”指的是通道,“mc
‑
asv”指的是多通道asv;从表中可以看出,所提出的方法均实现了良好性能。softmax的多通道asv系统在20通道测试场景下实现了低于oracle one
‑
best基线31.9%的eer,在不匹配的30通道场景下实现了低于oracle one
‑
best基线27.7%的eer。在不匹配的30通道和40通道测试环境中的泛化性能甚至优于在匹配的20通道环境中的性能,体现了ad
‑
hoc麦克风阵列中添加通道的优势。实验数据也表明,sparsemax算子实现了优于softmax算子的性能。
[0092]
表2在libri
‑
adhoc40半真实数据集上进行对比,实验数据表明,所提出的方法均实现了良好性能。softmax的多通道asv系统在20通道测试场景下实现了低于oracle one
‑
best基线35.3%的eer,在不匹配的30通道场景下实现了低于oracle one
‑
best基线26.3%的eer。sparsemax相对于softmax减少大约了3%的eer,性能优于softmax。