端到端语音转换
相关申请的交叉引用
1.本技术要求于2019年2月21日提交的美国申请62/808,627的优先权,该申请通过引用并入本文。
技术领域
2.本说明书通常涉及语音处理。
背景技术:
3.语音处理(speech processing)是对语音信号和信号处理方法的研究。信号通常以数字表示进行处理,因此语音处理可以看作是应用于语音信号的数字信号处理的特例。语音处理的各方面包括语音信号的获取、处理、存储、传输和输出。
技术实现要素:
4.语音合成器通常需要转录(transcription)作为输入。语音合成器接收转录并输出转录的合成话语(synthesized utterance)的音频数据。为了将用户的语音转换为合成话语,自动语音识别器必须对用户语音的音频数据执行自动语音识别,以生成用户语音的转录。然后语音合成器将生成用户语音的转录的合成话语。
5.这种执行自动语音识别和语音合成的技术可能会对计算系统造成负担。能够将从用户接收的语音音频转换为与用户的声音(voice)不同的声音的语音音频,而无需对用户的语音执行自动语音识别的过程将是有益的。下面的讨论描述了在不执行语音识别的情况下,利用机器学习来训练的模型将说话者语音中的语音音频转换为不同语音中的语音音频的过程。模型接收说话者所说的语音音频并将语音音频转换为数学表示。模型在不对说话者所说的语音音频进行语音识别的情形下,将数学表示转换为不同语音的语音音频。
6.在一些实施方式中,语音合成系统能够将包括第一声音(voice)中的话语的第一音频数据转换为包括第二声音中的相同话语的第二音频数据。可以通过直接作用于第一个音频数据的样本或特征来完成转换,而无需将音频转换为中间表示(例如,文本、电话等)。该系统可以使用序列到序列来对潜在包括背景噪声的任意语音进行归一化(normalize),并以单个预定义目标说话者的声音生成相同的内容。源语音可以来自任何说话者或口音,并且可能包含复杂的韵律模式(prosodic pattern)、缺陷(imperfection)和背景噪声,所有这些都通过归一化过程去除,因为第一音频数据被转换成干净的第二音频数据,其带有固定口音和连贯发音(articulation)及韵律。换句话说,系统可用于抛掉(project away)包括说话者特征的所有非语言信息,并仅保留所说的内容,而不是说的人、方式或地点。
7.这种类型的归一化有多种潜在的应用。将任何语音完全归一化为具有干净音频的单个说话者可以显著简化语音识别模型,该模型可以简化为支持单个说话者。在记录敏感和私人语音数据时,删除说话者的身份可能会很有用,这使得用户仅将转换后的语音传输到删除了“声学”身份的服务器。与声学伪装的音频不同的是,将所有口音减少至具有预定
义口音的单一声音还可以减轻偏见和歧视,同时保持自然人的声音,例如,用于电话面试或提供给招聘委员会的候选人谈话录音。其他应用将有助于理解对于听众来说陌生的口音的语音内容,即提高重口音语音的可理解性。
8.根据本技术中描述的主题的创新方面,一个端到端语音转换方法包括以下动作:计算设备接收用户说出的一个或多个第一术语的第一话语的第一音频数据;所述计算设备提供所述第一音频数据作为对模型的输入,所述模型被配置为接收以第一声音说出的一个或多个第一给定术语的第一给定话语的第一给定音频数据,并输出以合成声音说出的所述一个或多个第一给定术语的第二给定话语的第二给定音频数据,而不对所述第一给定音频数据执行语音识别;响应于提供所述第一音频数据作为对所述模型的输入,计算设备接收以所述合成语音说出的所述一个或多个第一术语的第二话语的第二音频数据;并且所述计算设备提供以所述合成声音说出的所述一个或多个第一术语的所述第二话语的所述第二音频数据,作为输出。
9.这些及其它实施方式中的每一个可以包括以下特征的一个或多个。动作还包括:所述计算设备接收数据,所述数据指示被配置为与给定人类进行对话的机器人未被配置为对从所述人类接收到的第三话语生成响应;以及基于接收指示所述机器人未被配置为从所述人类接收到的所述第三话语生成所述响应的所述数据,所述计算设备将对从所述人类接收到的所述第三话语的响应的请求发送至人类操作员。接收所述用户说出的所述一个或多个第一术语的所述第一话语的所述第一音频数据的动作包括,接收所述人类操作员响应于所述第三话语说出的所述一个或多个第一术语的所述第一话语的所述第一音频数据。接收所述用户说出的所述一个或多个第一术语的所述第一话语的所述第一音频数据的动作包括,接收所述人类在接听电话时说出的所述一个或多个第一术语的所述第一话语的所述第一音频数据。
10.动作还包括接收话语结合的音频数据;获得在所述话语集合中的每个话语的转录;将每个话语的所述转录作为输入提供给文本到语音模型;对每个话语的每个转录,接收合成语音中的额外话语集合的音频数据;并且使用所述话语集合的所述音频数据和合成声音中的所述额外话语集合的所述音频数据来训练所述模型。动作还包括:所述计算设备接收额外用户说出的一个或多个第三术语的第三话语的第三音频数据;所述计算设备提供所述第三音频数据作为对所述模型的输入;响应于提供所述第三音频数据作为对所述模型的输入,所述计算设备接收以所述合成语音说出的一个或多个第三术语的第四话语的第四音频数据;并且所述计算设备提供以所述合成声音说出的所述一个或多个第三术语的所述第四话语的所述第四音频数据,作为输出。动作还包括所述计算设备绕过获取所述第一话语的转录。所述模型被配置为调整一个或多个第一给定术语中的每一个给定术语之间的时间段。所述模型被配置为调整一个或多个第一给定术语中的每一个给定术语之间的说话时间。
11.该方面的其它实施方式包括相应的系统、装置、和记录在计算机存储装置上的计算机程序,它们每个被配置为执行上述方法的操作。
12.本说明书中描述的主题的特殊实施方式可以实现,以使得实现下方优点的一种或多种。计算系统可以接收以用户声音说出的话语的音频数据,并且输出以合成声音说出的合成话语的音频数据,而没有因对接收的音频数据执行自动化语音识别产生的额外开销。
13.在本说明书中描述的主题的一个或多个实现的细节在附图和以下实施方式中阐述。本主题的其他特征、方面和优点将从实施方式、附图和权利要求中变得明显。
附图说明
14.图1示出了在不执行语音识别的情况下将从用户接收的语音音频转化为合成语音音频的示例系统。
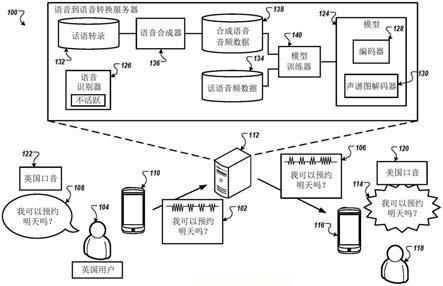
15.图2示出了示例系统,该系统将从正在打断自动化机器人和用户之间对话的操作员接收的语音音频转换为模仿自动化机器人的语音音频。
16.图3示出了示例系统,该系统将从筛选呼叫的被呼叫者接收的语音音频转换为阻止呼叫者确定该被呼叫者接听该呼叫的语音音频。
17.图4为在不执行语音识别的情况下将从用户接收的语音音频转化为合成语音音频的示例过程的流程图。
18.图5示出了系统的示例网络架构,该系统在不执行语音识别的情况下将从用户接收的语音音频转换为合成语音音频,该合成语音音频具有比用户更高的音高(pitch)和更快的语速。
19.图6示出了计算设备和移动计算设备的示例。
20.各图中的相同的附图标记和标号表示相同的元素。
具体实施方式
21.图1示出了在不执行语音识别的情况下将从用户104接收的语音音频102转换为合成语音音频106的示例系统100。简而言之,并且如下面更详细地描述的,使用英国口音说话的用户104在计算设备110附近说出话语108。计算设备110将话语108的音频数据102传输到语音到语音转换服务器112。语音到语音转换服务器112将话语108的音频数据102转换为合成话语114的音频数据106。语音到语音转换服务器112将合成话语114的音频数据106传输给计算设备116,并且计算设备116输出合成话语114。在一些实施方式中,端到端语音转换服务器112的功能被内置到计算设备110或计算设备116或两者中。
22.更详细地,用户104和用户118正在通过计算设备110和计算设备116彼此交谈。用户104和用户118可能正在通过电话、或例如网络语音协议的另一类型的语音通信协议进行交谈。虽然用户104和用户118说着相同的语言,但是用户118可能难以理解用户104,因为用户104有浓重的口音。在该示例中,用户104可以是英国人,并且与用户104的英国口音122相比,用户118可能更容易理解美国口音120。
23.为了解决这个问题,计算设备110可以向语音到语音转换服务器112提供用户104所说的话语108和其它话语的音频数据102。语音到语音转换服务器112可以被配置为将可能带有口音的用户说出的话语的音频数据转换成可能具有不同口音的合成话语的音频数据。为了完成这种转换,服务器通常会被配置为对用户所说的带有口音的话语的音频数据执行语音识别。语音识别器可以被配置为识别以用户的口音说出的语音或者可以被配置为识别以任何口音说出的语音。然后服务器将转录提供给语音合成器,语音合成器生成具有不同口音的合成语音的音频数据。语音到语音转换服务器112以不同的方式操作。
24.语音到语音转换服务器112从计算设备110接收话语108的音频数据102,并且将话
语108的音频数据102提供至模型124。语音到语音转换服务器112训练模型124,以将以英国口音122说出的话语108的音频数据102转换为以美国口音120说出的话语114的音频数据106。语音到语音转换服务器112不使用语音识别器126来执行该转换。语音识别器126可以在转换过程期间保持不活动。相反,模型124将话语108的音频数据102提供给编码器128。编码器128可以被配置为将话语108的音频数据102转换为内部表示,例如一系列向量。例如,当编码器128接收话语108的音频数据102时,编码器128可以处理五帧音频并将这五帧音频转换为十个向量。这些向量不是音频数据102的帧的转录,而是音频数据102的帧的数学表示。模型124向声谱图解码器(spectrogram decoder)130提供该一系列向量。声谱图解码器130可以被配置为基于从编码器128接收的向量来生成合成话语的音频数据。例如,声谱图解码器130可以从编码器128接收代表五帧音频的十个向量。声谱图解码器130生成合成话语114的五帧音频数据106,其包括与五帧音频数据相同的词或部分词,但具有与用户104不同的声音。
25.语音到语音转换服务器112将合成话语114的音频数据106提供给计算设备116。在图1示出的示例中,语音到语音转换服务器112提供“我可以预约明天吗?”的合成话语的音频数据106。合成话语114可以带有美国口音120。在一些实施方式中,合成话语114可以具有与用户104相同的口音和与用户104不同的语音。合成话语114的声音可能使得用户118或另一用户无法将用户104识别为话语108的说话者。在一些实施方式中,合成话语114的节奏(candence)可以不同于话语108的节奏。语音到语音转换服务器112可以调整合成话语114的节奏以增加用户118能够理解合成话语114的可能性。
26.计算设备116接收合成话语114的音频数据106并通过扬声器或其它音频输出设备输出音频数据106。在一些实施方式中,当用户104说出话语108的部分时,语音到语音转换服务器112连续地生成合成话语114的对应部分。例如,语音到语音转换服务器112可以在接收到一秒钟的话语108之后生成一秒钟的合成话语114。通过连续地生成合成话语114的部分,用户104和118之间的对话可以更自然地同步。在一些实施方式中,语音到语音转换服务器112可以确定用户104何时已停止说话。在确定用户104已经停止说话之后,语音到语音转换服务器112将话语108的音频数据102转换为合成话语114的音频数据106。
27.语音到语音转换服务器112包括用于生成训练数据和训练模型124的各种部件。语音到语音转换服务器112包括话语转录132和话语音频数据134。话语可以是具有不同类型口音的不同用户所说的话语。在一些实施方式中,话语转录132由自动语音识别器生成。在将转录存储在话语转录132中并且将音频数据存储在话语音频数据134中之前,每个话语的说话者可以验证转录的准确性。在一些实施方式中,话语转录132由一个或多个人生成。
28.语音到语音转换服务器112将话语转录132提供给语音合成器136。语音合成器被配置为生成转录132的合成话语音频数据138。语音合成器被配置为以单个声音生成合成话语音频数据138。该声音可以具有特定的口音,例如美国口音或英国口音。合成话语音频数据138可以没有任何背景噪声或其它音频制品(artifact)。
29.语音到语音转换服务器112向模型训练器140提供合成话语音频数据138和话语音频数据134。模型训练器140使用机器学习技术训练模型124。模型训练器140训练模型124以接收与话语音频数据134相似的音频数据,并在不对接收的音频数据执行语音识别的情况下输出与合成话语音频数据138相似的音频数据。即使是当模型124接收包括不同声音的不
同话语的音频数据的不同输入时,模型训练器140训练模型124以输出与来自语音合成器136的合成话语相同的声音的话语。
30.在一些实施方式中,语音到语音转换服务器112可以使用包括不同音频特征的话语音频数据134。这可以导致模型124被配置为处理具有那些不同特征的音频数据的输入。在一些实施方式中,语音到语音转换服务器112可以将音频特征添加到话语音频数据134,使得模型训练器140训练模型124来处理与添加的音频特征类似的音频特征。
31.例如,语音到语音转换服务器112可以向话语音频数据134添加不同级别的噪声。不同级别的噪声可以包括不同类型的噪声,例如静止(stationary)噪声和/或非静止(non
‑
stationary)噪声。静止噪声可以包括不同级别的马路噪声、不同级别的类似于鸡尾酒会或餐厅的背景语音噪声、不同级别的风扇噪声、和/或任何其它类似类型的噪声。非静止噪声可以包括不同级别的电视噪声、不同级别的阵风噪声、不同级别的背景音乐噪声、和/或任何其它类似类型的噪声。语音到语音转换服务器112可以向相同话语的音频数据添加不同级别和不同类型的噪声。这可能导致生成与相同转录相匹配的多个音频数据样本,每个音频数据样本包括相同的底层话语音频数据,底层话语音频数据具有添加的不同级别和不同类型的噪声。通过添加噪声,模型124可以被更好地配置为处理接收到的音频数据,除了话语音频数据之外,接收到的音频数据还包括背景噪声。
32.作为另一示例,语音到语音转换服务器112可以处理来自具有语言障碍的用户的话语音频数据134,该语言障碍可能导致用户说话不流畅,用户例如为那些患有肌萎缩侧索硬化症(amyotrophic lateral sclerosis)的用户。模型训练器140可以使用来自具有语言障碍的用户的话语音频数据和话语的转录来训练模型124,使得模型124能够接收由具有语音障碍的用户说出的话语音频数据,并输出具有更一致的节奏的、可以更容易被另一用户理解的话语音频数据。
33.作为另一示例,语音到语音转换服务器112可以被配置为在不转录话语的情况下,将话语翻译成不同的语言。在这种情况下,话语音频数据134可以包括以例如英语的第一语言说出的话语。话语转录132可以包括以第二语言的话语翻译的转录,例如西班牙语翻译的转录。语音合成器136可以被配置为生成第二语言的合成语音,例如合成的西班牙语话语。模型训练器140利用机器学习使用第一语言的话语音频数据134和第二语言的合成话语音频数据138来训练模型124。所得到的模型124被配置为在不转录接收的话语的情况下,接收第一语言(例如英语)的话语音频数据,并且输出第二语言(例如西班牙语)的合成话语音频数据。
34.图2示出了示例系统200,该系统将从操作员204接收的语音音频202转换为模仿自动化代理206的语音音频210,该操作员204正在打断自动化代理206和用户208之间的对话。简而言之,如下文更详细描述的,用户208正在与自动化代理206进行对话。在对话期间,用户208说出自动化代理206无法响应的话语212。操作员204接收自动化代理206不能对话语212作出响应的指示。操作员204提供话语214以响应话语212。语音到语音转换服务器216将话语214的语音音频202转换为自动化代理206的语音,从而使用户208认为用户208仍然与同一方对话。在一些实施方式中,自动化代理206的功能被内置到计算设备220或计算设备234或两者中。在一些实施方式中,端到端语音转换服务器216的功能被内置到计算设备220或计算设备234或两者中。
35.更详细地,在阶段a中,用户208发起与自动化代理206的电话对话。计算设备220与自动化代理206连接。用户说出话语218并询问自动代理,“我可以预订一张两人桌吗?”自动化代理206可以模仿人类,使得用户208无法将自动化代理206与真实的人区分开来。在一些实施方式中,自动化代理206可以发起与用户208的电话对话。在一些实施方式中,用户208和自动化代理206之间的对话可以是不同于电话呼叫的通信信道,例如voip呼叫或其它类型的语音通信。
36.在阶段b,计算设备220通过麦克风或另一输入设备检测话语218,并使用音频子系统处理话语218的音频数据。音频子系统可以包括麦克风、模数转换器、缓冲器和各种其它的音频滤波器。麦克风可以被配置为检测周围区域中的声音,例如话语218的语音。模数转换器可以被配置为对麦克风检测到的音频数据进行采样。缓冲器可以存储采样的音频数据,以供计算设备220处理或供计算设备220传输。在一些实施方式中,音频子系统可以持续活跃,或者可以在当计算设备220正在等待接收音频的期间活跃,例如在电话呼叫期间活跃。在这种情况下,响应于与自动化代理206的电话呼叫的发起,麦克风可以检测音频。模数转换器可以在电话呼叫期间不断地对检测到的音频数据进行采样。缓冲器可以存储最新采样的音频数据,例如最近十秒的声音。计算设备220可以向自动化代理206提供话语218的经过采样和过滤的音频数据222。
37.自动化代理206接收话语218的音频数据222并确定合适的响应。自动化代理206可以应用一系列规则、决策树、神经网络、和/或另一个决策过程来确定合适的响应。自动化代理206可以生成合适的响应的转录,并将该转录提供给语音合成器。在阶段c,语音合成器可以生成代表话语226的音频数据224,“今晚吗?”,作为对“我可以预订一张两人桌吗?”的响应。虽然语音合成器可以生成话语226,但用户208无法确定用户208正在对计算机说话。
38.在阶段d,计算设备226接收话语226的音频数据224。计算设备226通过扬声器或其它类型的音频输出设备输出音频数据224。用户208听到合成语音228中的话语226。
39.在阶段e,用户208说出话语212“我今晚得看比赛。你知道史密斯上场吗?”来响应话语226。计算设备220检测话语226并使用音频子系统处理话语226。在阶段f,计算设备220将话语212的音频数据230提供给自动化代理206。
40.自动化代理206接收话语212的音频数据230。自动化代理206以与处理话语218的音频数据222类似的方式处理话语212的音频数据230。自动化代理206可以应用一系列规则、决策树、神经网络、和/或另一个决策过程来确定对话语212的合适的响应。在这种情况下,自动化代理206无法确定合适的响应。在用户话语偏离对话主题的情况下,自动化代理206可能无法确定对用户话语的合适的响应。
41.为了继续对话,当自动化代理206或其他自动化代理无法生成对用户话语212的合适的响应时,自动化代理206可以通知正待命的操作员204提供帮助。在阶段g,自动化代理206生成自动化代理206和用户208之间对话的概要(summary)232。概要232可包括直到自动化代理206不能对用户话语212产生适当响应的点之前的对话记录。可选地或附加地,概要232可包括由于自动化代理206和用户208之间的对话或协议而完成的任何任务的描述。在图2的示例中,概要232包括自动化代理206和用户212之间的对话的记录。自动化代理206还可包括对话的状态236。状态236可以描述自动化代理206不能执行的任务。状态236可以指示自动化代理206不能对话语212的音频数据230执行语音识别。在那种情况下,概要232会
包括话语212的音频数据230。状态236可以指示自动化代理不能生成对话语212的响应。
42.在阶段h,操作员204的计算设备234接收概要232和状态236。操作员204审查概要232和状态236。操作员204说出话语214,作为对用户208的话语238的响应并且作为将对话引导回原始主题、或是自动化代理206能理解的主题的尝试。计算设备234检测话语214并使用音频子系统以与计算设备220处理话语212和话语218类似的方式处理话语214。在图2示出的示例中,用户204说:“我不知道。这应该是令人兴奋的。你想订哪一天呢?”43.在阶段i中,计算设备234将话语214的音频数据202传输到语音到语音转换服务器216。语音到语音转换服务器216可以类似于语音到语音转换服务器112,其中语音到语音转换服务器216被配置为接收以第一声音说出的话语音频数据,并且输出包括以第二且不同的声音说的相同的单词和术语的话语音频数据,而不用对以第一声音说的话语音频数据进行语音识别。语音到语音转换服务器216可以被配置为生成与自动化代理206相同的合成语音228的话语音频数据。
44.在阶段j,语音到语音转换服务器216将话语214的音频数据转换为话语238的音频数据210。语音到语音转换服务器216将话语238的音频数据210传输给计算设备220。在一些实施方式中,语音到语音转换服务器216将话语238的音频数据210传输给计算设备234。然后计算设备234将话语238的音频数据210传输到自动化代理206。自动化代理将话语238的音频数据210传输给计算设备220。在一些实施方式中,语音到语音转换服务器216将话语238的音频数据210传输给自动化代理206。自动化代理将话语238的音频数据210传输给计算设备220。在一些实施方式中,计算设备234向自动化代理206提供话语214的转录,因此自动化代理仍然知道与用户208的对话的内容。自动化代理206可以使用话语214的转录来更新自动化代理206使用的模型和/或规则,以生成响应。
45.在阶段k,计算设备220通过扬声器或其它类型的音频输出设备输出话语238。用户208听到话语238,并且因为话语238是与话语226在以相同的合成声音228说出的,所以用户208不知道另一方正在参与对话。用户208可以通过说出新的话语来响应话语238。操作员204可以继续监视对话,以确保自动化代理206能够无缝地接管对话。如有必要,操作员204可以通过语音到语音转换服务器216继续与用户208交谈,以进行剩余的对话或剩余对话的一部分。在对话期间,用户208可以认为用户208正在与同一个真人交谈。
46.图3示出了示例系统300,该系统将从筛选呼叫的被呼叫者304接收的语音音频302转换为语音音频306,语音音频306阻止呼叫者308确定是被呼叫者304应答该呼叫。简而言之,如下文更详细描述的,呼叫者308向被呼叫者304发出电话呼叫。被呼叫者304可能不确定接听该呼叫,不是使呼叫进入语音邮件,而是被呼叫者304应答并筛选呼叫。被呼叫者304可使用计算设备210的呼叫筛选功能,计算设备210访问语音到语音转换服务器312。语音到语音转换服务器312将以被呼叫者的声音说出的话语314的音频数据302转换为以一般声音说出的合成话语316的音频数据306。呼叫者308在未意识到被呼叫者304,并且可能是真实的人应答了呼叫的情况下,回答了筛选问题。在一些实施方式中,端到端语音转换服务器312的功能被内置到计算设备310或计算设备318或两者中。
47.更详细地,在阶段a中,呼叫者308艾丽斯(alice)发起了与被呼叫者304鲍勃(bob)的电话呼叫。计算设备310通过输出通知311来指示计算设备310正在接收来电。与电话呼叫不同,呼叫者308可以通过替代类型的通信信道,例如voip或类似类型的语音通信来发起语
音通信。呼叫者308可以从计算设备318发起电话呼叫。被呼叫者304的计算设备310指示被呼叫者304正在接收电话呼叫。计算设备310可以给被呼叫者304直接接听电话呼叫、忽略电话呼叫、将电话呼叫发送到语音邮件、或发起呼叫筛选的选项。
48.在阶段b,被呼叫者304发起呼叫筛选的选项。一旦选择呼叫筛选的选项,计算设备310启动与语音到语音转换服务器312的通信。计算设备310指示计算设备310将向语音到语音转换服务器312发送音频数据以转换为另一种声音。
49.在阶段c,被呼叫者304说出话语314。计算设备310通过麦克风或另一类型的音频输入设备检测话语314,并使用音频子系统处理音频数据。音频子系统可以包括麦克风、模数转换器、缓冲器和各种其它的音频滤波器。麦克风可以被配置为检测周围区域中的声音,例如话语314的语音。模数转换器可以被配置为对麦克风检测到的音频数据进行采样。缓冲器可以存储采样的音频数据以供计算设备310处理或供计算设备310传输。在一些实施方式中,音频子系统可以持续活跃或者可以在当计算设备310正在等待接收音频的期间活跃,例如在电话呼叫期间活跃。在这种情况下,麦克风可响应于呼叫筛选选项的发起而检测音频。模数转换器可以在电话呼叫期间不断地对检测到的音频数据进行采样。缓冲器可以存储最新采样的音频数据,例如最近十秒的声音。在阶段d,计算设备310可以向语音到语音转换服务器312提供话语314的经过采样和过滤的音频数据302。
50.语音到语音转换服务器312从计算设备310接收由被呼叫者304说出的话语314的音频数据302。在一些实施方式中,计算设备310向语音到语音转换服务器312提供指令,以将被呼叫者304说出的话语314的音频数据302转换为以不同声音说出的话语。在一些实施方式中,计算设备310提供关于语音到语音转换服务器312应该将以不同声音说出的合成话语316的音频数据306发送到哪里的指令。例如,计算设备310可以提供电话号码或计算设备318的设备标识符、以及传输以不同声音说出的合成话语316的音频数据306的指令。在一些实施方式中,计算设备310可以向语音到语音转换服务器312提供指令,以将在不同声音中说出的合成话语316的音频数据306传输回计算设备310,使得计算设备可以将以不同声音说出的合成话语316的数据306传输至计算设备318。
51.在阶段e,语音到语音转换服务器312生成以与被呼叫者304的声音不同的声音说出的合成话语316的音频数据306。语音到语音转换服务器312可以类似于语音到语音转换服务器112,其中,语音到语音转换服务器312被配置为接收以第一声音说出的话语的音频数据,并且输出包括以第二且不同的声音说的、相同的单词和术语的话语的音频数据,而不用对以第一声音说的话语的音频数据进行语音识别。在本示例中,语音到语音转换服务器312接收以被呼叫者304的声音说出的话语314的音频数据302。语音到语音转换服务器312将以被呼叫者304的声音说出的话语314的音频数据302提供给模型,该模型在不对音频数据302执行语音识别的情况下生成以一般声音说出的话语316的音频数据306,该一般声音听起来像真实的人并且不像被呼叫者304。语音到语音转换服务器312将话语316的音频数据306提供给计算设备318。在一些实施方式中,语音到语音转换服务器312向计算设备310提供话语316的音频数据306,并且计算设备310向计算设备318提供话语316的音频数据306。
52.在阶段f,计算设备318通过计算设备318的扬声器或其它音频输出设备来输出话语316的音频数据306。话语316不是以被呼叫者304的声音,而是以不同的一般声音,不同的
一般声音听起来像真实的人并且不像被呼叫者304。在图3的示例中,呼叫者308听到以听起来不像被呼叫者304的声音“请说出您的姓名和呼叫目的”。呼叫者308可能会认为呼叫者308正在与被呼叫者304的秘书或助理对话。
53.在阶段g,呼叫者308通过说出话语320来响应话语316。话语320由计算设备318的麦克风或其它音频输入设备检测。计算设备318的音频子系统处理话语320。在图3的示例中,呼叫者308说:“我是艾丽斯,我打电话是为了安排与鲍勃的会面。”54.在阶段h,计算设备318将话语320的音频数据322传输到计算设备310。本示例的呼叫筛选功能可以在一个方向上起作用。换句话说,通过呼叫筛选功能,伪装了激活呼叫筛选功能的被呼叫者304的声音。呼叫者308的声音保持不变。
55.在阶段i,计算设备310通过计算设备310的扬声器或其它音频输出设备来输出话语320的音频数据322。话语320是呼叫者308的声音。被呼叫者304听到呼叫者308的声音,“我是艾丽斯。我打电话是为了安排与鲍勃的会面”。
56.在阶段j并且呼叫筛选仍处于活动时,被呼叫者304说出话语326。话语326由计算设备310的麦克风或其它音频输入设备检测。计算设备310的音频子系统处理话语326。在图3的示例中,被呼叫者说:“稍等”。
57.在阶段k并且呼叫筛选仍处于活动时,计算设备310将话语326的音频数据328传输至语音到语音转换服务器312。语音到语音转换服务器312将话语326的音频数据328提供给与阶段d中相同的模型。该模型以与被呼叫者304的声音不同的声音生成话语332的音频数据330。在一些实施方式中,话语332的声音与话语316的声音相同。语音到语音转换服务器312生成话语332的音频数据330,而不对音频数据328执行语音识别。
58.在阶l段,语音到语音转换服务器212将话语332的音频数据330提供给计算设备318。在一些实施方式中,语音到语音转换服务器312向计算设备310提供话语332的音频数据330,并且计算设备310向计算设备318提供话语332的音频数据330。
59.在阶段m,计算设备318通过计算设备318的扬声器或其它音频输出设备来输出话语332的音频数据330。话语332不是被呼叫者304的声音,而是与话语316相同的一般声音或听起来像真人的另一种声音。在图3的示例中,呼叫者308听到不像被呼叫者304的声音的“稍等”。呼叫者308可能继续会认为呼叫者308正在与被呼叫者304的秘书或助理对话。
60.在阶段n,被呼叫者304说出话语334。话语334由计算设备310的麦克风或其它音频输入设备检测。计算设备310的音频子系统处理话语334。在图3的示例中,被呼叫者304说:“嗨!艾丽斯,我是鲍勃”。在说出话语334之前,被呼叫者304可以停用计算设备310的呼叫筛选模式。在阶段k、l或m的执行期间以及阶段n之前,被呼叫者304可以随时停用呼叫筛选模式。通过停用呼叫筛选模式,计算设备310返回到将被呼叫者304说的话语的音频数据传输到计算设备318,而不是将被呼叫者304说的话语的音频数据传输到语音到语音转换服务器312。在一些实施方式中,计算设备310向语音到语音转换服务器312提供指示,该指示为计算设备310将不会将随后接收的话语的音频数据传输到语音到语音转换服务器312以转换为不同的声音。
61.在阶段o并且呼叫筛选停用时,计算设备310将音频数据336传输至计算设备318。该音频数据传输可以类似于在使用类似于计算设备310和计算设备318的计算设备的两个用户之间的典型语音对话期间发生的音频数据传输。
62.在阶段p,计算设备318通过计算设备318的扬声器或其它音频输出设备来输出话语338。在图3的示例中,计算设备318输出话语338“嗨!艾丽斯,我是鲍勃”。话语338的声音是被呼叫者304的声音。呼叫者308很可能认为筛选呼叫的人将呼叫转移给了被呼叫者304,并且之前在整个呼叫期间呼叫者308并没有与被呼叫者304通话。
63.图4为在不执行语音识别的情况下将从用户接收的语音音频转化为合成语音音频的示例过程的流程图。通常,过程400接收用户说出的话语音频数据。过程400通过将话语音频数据应用于模型,而将话语音频数据转换为以不同声音的另一话语的音频数据。不同的声音是听起来像真人的合成声音。听到以不同声音的其他话语的人可能没有意识到在转换为不同声音之前原始用户说了该话语。流程400在不对接收到的音频数据进行语音识别的情况下,生成不同声音的其他话语的音频数据。过程400输出以不同声音的其他话语的音频数据。过程400将被描述为由包括例如图1中的系统100、图2中的系统200、或者图3中的系统300的一台或多台计算机的计算机系统执行。
64.该系统接收用户说的一个或多个第一术语的第一话语的第一音频数据(410)。用户可以以用户的典型声音说话。在一些实施方式中,用户在接听电话的同时说出第一话语。在一些实施方式中,用户可以在接听电话之前激活系统的呼叫筛选功能。
65.该系统提供第一音频数据作为对模型的输入,该模型被配置为接收以第一声音说出的一个或多个第一给定术语的第一给定话语的第一给定音频数据,并输出以合成声音说出的一个或多个第一给定术语的第二给定话语的第二给定音频数据,而不对第一给定音频数据执行语音识别(420)。模型可以使用编码器将第一音频数据编码成表示音频数据的一系列向量。这些向量可以不同于第一音频数据的转录。模型可以使用解码器来生成输出的音频数据。解码器可以被配置为将各向量转换为与用户声音不同的声音的合成语音。在一些实施方式中,模型绕过转录第一话语的第一音频数据。
66.响应于提供所述第一音频数据作为对模型的输入,系统接收以合成声音说出的一个或多个第一术语的第二话语的第二音频数据(430)。在一些实施方式中,第一话语中的一个或多个第一术语中的每一个的说话时间可以不同于第二话语中的一个或多个第一术语中的每一个的说话时间。在一些实施方式中,第一话语中的一个或多个第一术语中的每一个之间的时间段可以不同于第二话语中的一个或多个第一术语中的每一个之间的时间段。
67.系统提供以合成声音说出的一个或多个第一术语的第二话语的第二音频数据作为输出(440)。系统可以将第二音频数据输出到扬声器或其它音频输出设备。另一个用户可以听到第二话语,并且可能不知道原始用户说了第一话语。即使系统使用模型生成了第二话语的音频数据,第二话语也可能听起来像真人的声音。在一些实施方式中,合成声音可以具有性别中立的特点,使得听众无法确定说话者是男性还是女性。性别中立的合成声音的音高可以是女性合成声音的音高和男性合成声音的音高的平均值。
68.在一些实施方式中,系统可以接收来自不同用户的话语。系统可以将来自不同用户的话语的音频数据应用于模型。模型可以输出以同一合成声音的合成话语的音频数据。换言之,模型可以被配置为将不同人说出的话语的音频数据转换为以相同合成声音的话语。
69.在一些实施方式中,系统可以使用系统和其它系统接收到的话语集合来训练模型。系统获得在话语集合中的每个话语的转录。系统可以使用自动语音识别或通过手动转
录来生成转录。系统将每个转录提供给生成以合成声音的合成话语的语音合成器或文本到语音模型。系统使用机器学习、话语集合、以及相应的合成话语来训练模型。训练好的模型被配置为基于接收到用户说出的话语,生成以相同的合成声音的合成话语。训练好的模型不使用语音识别来生成合成话语。
70.在一些实施方式中,系统可以是被配置为与用户进行语音对话的自动化代理或机器人的一部分。用户可能会有这样的印象,用户不是在对计算机说话,而是在与真人说话。自动化代理可能无法对自动化代理从用户接收到的每个话语生成合适的响应。在这种情况下,操作员可能会随时待命,让自动化代理生成对用户话语的响应,以便对话可以继续。系统可以帮助伪装操作员的声音,从而使用户认为用户仍在与同一个人说话。系统可以将操作员的声音转换为自动化代理的声音,从而即使当操作员而不是自动化代理生成响应时,用户也能听到相同的声音。
71.更详细地,本文描述了端到端的语音到语音模型,该模型将输入声谱图(spectrogram)直接映射到另一个声谱图,而无需任何中间离散表示。网络由编码器、声谱图解码器、音素(phoneme)解码器、和合成时域波形的声码器(vocoder)组成。可以训练模型以将来自任何说话者的、包括口音、情绪、复杂韵律模式、缺陷和背景噪声的语音归一化为具有固定口音和一致发音和韵律的干净的单个预定义目标说话者的声音。本文描述了这种方法对语音识别性能的影响。此外,本文说明了可以在语音分离任务上训练相同的架构。在一些实施方式中,端到端的语音到语音模型可以将西班牙语语音翻译成合成的英语语音。
72.编码器
‑
解码器注意模型(encoder
‑
decoder models with attention)可用于建模各种复杂的序列
‑
序列(sequence
‑
to
‑
sequence)问题。这些模型可用于语音和自然语言处理,例如机器翻译、语音识别、和组合语音翻译。在给定虚拟原始输入下使用直接生成目标序列的单个神经网络,这些模型还可以用于端到端文本到语音(text
‑
to
‑
text,tts)合成和自动语音识别(automatic speech recognition,asr)。
73.本文描述了结合最先进的语音识别和合成模型来构建直接的端到端语音到语音序列转换器,该转换器生成语音声谱图作为不同输入声谱图的函数,而不依赖于中间离散表示。模型可以首先应用于语音归一化和语音分离任务。该模型可用于将一种语言直接翻译成另一种语言,例如,从西班牙语语音转换为英语语音。
74.在一些实施方式中,统一的序列到序列模型可以对潜在包括背景噪声的任意语音进行归一化,并生成以单个预定义目标说话者的声音的相同的内容。源语音可以来自任何说话者或口音,可以包括复杂的韵律模式、缺陷和背景噪声,所有这些被转化为具有固定口音和一致性发音和韵律的干净的信号。该任务是抛掉包括说话者特征的所有非语言信息,并仅保留所说的内容,而不是说的人、方式或地点。
75.这种归一化系统具有多种潜在应用。将任何声音完全归一化为具有干净音频的单个说话者可以显著简化asr模型,该模型可以简化为支持单个说话者。在记录敏感和私人语音数据时,删除说话者的身份可能很有用,这允许用户仅将转换后的语音传输到删除了“声学”身份的服务器。与声学伪装的音频截然不同,将所有口音简化为预定义口音的单一声音还可以减轻偏见和歧视,同时保持自然人的声音,例如,用于电话面试或提供给招聘委员会的候选人谈话录音。其他应用将有助于理解对于听众来说陌生的口音的语音内容,比如提高重口音语音的可理解性。
76.在一些实施方式中,语音转换可以包括使用映射代码书(mapping code book)、神经网络、动态频率扭曲(dynamic frequency warping)和高斯混合模型。这些技术可以只修改输入说话者的声音。在一些实施方式中,声音转换可以包括口音转换。本文描述的模型可以将所有说话者归一化为单个声音和口音,以及归一化韵律并使用直接生成目标信号的端到端神经架构。在一些实施方式中,声音转换可以是基于过滤和/或转换的方法。
77.端到端序列到序列模型架构采用输入源语音、并生成/合成目标语音作为输出。在一些实施方式中,这种模型的唯一训练要求是成对的输入
‑
输出语音的平行语料库。
78.如图5所示,网络由带有注意力(attention)的编码器和解码器组成,以及合成时域波形的声码器。编码器将一系列声学帧转换为隐藏特征表示,解码器使用该表示来预测声谱图。在一些实施方式中,该模型的核心架构包括基于注意力的端到端asr模型和/或端到端tts模型。
79.基本编码器配置可以类似于下方讨论的具有一些变化的其它编码器。从以16khz采样的示例输入语音信号中,编码器可以在125
‑
7600hz的范围内提取80维log
‑
mel声谱图声学特征帧(spectrogram acoustic feature frames),使用hann窗、50ms帧长(frame length),12.5ms帧移位(frame shift),和1024点短时傅立叶变换(short
‑
time
‑
fourier,stft)计算。
80.在本示例中,输入特征被传递到两个具有relu激活的卷积层的堆栈(stack),每个层由32个内核组成,在时间x频率上形状为3x3,步幅为2x2,按总因数4进行时间下采样,减少了后续层的计算量。在每一层之后应用批量归一化。
81.使用1x3滤波器将生成的下采样序列传递到双向卷积lstm(clstm)层,例如,在每个时间步长内仅在频率轴上进行卷积。最后,将其传递到每个方向上大小为256的三个双向lstm层的堆栈中,与512维线性投影交错,然后进行批量归一化和relu激活,以计算最终的512维编码器表示。
82.在一些实施方式中,解码器的目标是1025维stft幅度(magnitude),使用与输入特征2048点stft相同的帧数计算。
83.系统使用由自回归rnn(autoregressive rnn)组成的解码器网络,来一次一帧地预测来自编码输入序列的输出声谱图。来自前一个解码器时间步长的预测首先通过小型预网络(pre
‑
net),该预网络包括两个具有256个relu单元的全连接层,这可能有助于学习注意力。预网络输出和注意力上下文向量可以连接,并通过两个具有1024个单元的单向lstm层的堆栈。然后,lstm输出和注意力上下文向量的连接通过线性变换进行投影,以产生对目标声谱图帧的预测。最终,这些预测通过5层卷积预网络,5层卷积预网络预测要增加到初始预测中的残差(residual)。每个post
‑
net层都有512个形状为5x 1的过滤器,然后是批量归一化和tanh激活。
84.为了从预测幅度谱图合成音频信号,系统使用griffin
‑
lim算法来估计与预测幅度一致的相位,然后是逆stft。在一些实施方式中,例如wavenet的神经声码器可以提供提高的合成质量。在一些实施方式中,wavenet可以替代griffin
‑
lim。
85.在一些实施方式中,系统可以被配置为生成语音而不是任意音频。联合训练编码器网络以同时学习底层语言的高级表示有助于使声谱图解码器的预测偏向于相同底层语音内容的表示。可以添加辅助asr解码器来预测,以编码器潜在表示为条件的、输出语音的
(字素(graheme)或音素(phoneme))转录。这种经过多任务训练的编码器可以被认为是学习输入的潜在表示,该表示维护有关底层转录的信息,例如,更接近在tts序列到序列网络中学到的潜在表示的潜在表示。
86.在一些实施方式中,解码器输入是通过将前一时间步发出的字素的64维嵌入,以及512维注意力上下文向量之间连接起来创建的。这被传递到一个256单元lstm层。最后,将注意力上下文和lstm输出的连接传递到softmax层,该层预测输出词汇表中每个字素的概率。
87.语音到语音模型可用于将来自任意说话者的语音转换为使用预定义的规范说话者的声音。如上所述,系统可以要求跨越各种说话者和记录条件的平行话语语料库,每个话语都映射到来自规范说话者的语音。由于在干净的声学环境中让单个说话者记录数小时的话语可能是不切实际的,因此可以使用tts系统从大量人工或机器转录的语音语料库中生成训练目标。从本质上讲,这减少了在单扬声器tts系统的声音中再现任何输入语音的任务。使用tts系统生成这个平行语料库有多个优点:(1)音频是由单个预定义的说话者、并且是以使用标准语言口音说出的;(2)无任何背景噪音;(3)使用没有不流畅的、高质量的发音;以及(4)根据需要合成大量数据以扩展到大型语料库。
88.本文描述了端到端的语音到语音模型,该模型将输入声谱图直接映射到另一个声谱图,而无需任何中间离散表示。该模型被训练以将来自任何说话者的任何话语归一化为单个预定义说话者的声音,保留语言内容并抛掉非语言内容。在一些实施方式中,可以训练相同的模型以在重叠语音混合中成功识别、分离、和重建最响亮的说话者,这提高了asr性能。在某些情况下,模型可以将一种语言的语音直接翻译成另一种语言的语音。
89.对于以保留说话人身份为目标的任务,可以利用tts合成来引入目标说话人身份的变化,例如匹配原先说话的人,并直接控制说话风格或韵律。该技术可用于为归一化模型合成训练目标,该模型保持说话者的身份,但强制执行中性韵律,反之亦然,该模型归一化了说话者的身份但保持输入语音的韵律。
90.图6示出了可用于实现这里描述的技术的计算设备600和移动计算设备650的示例。计算设备600旨在表示各种形式的数字计算机,例如膝上型电脑、台式机、工作站、个人数字助理、服务器、刀片服务器、大型机和其他合适的计算机。移动计算设备650旨在代表各种形式的移动设备,例如个人数字助理、蜂窝电话、智能电话和其他类似的计算设备。此处显示的各部件、它们的连接和关系及其功能仅作为示例,并不意味着限制。
91.计算设备600包括处理器602、存储器604、存储设备606、连接到存储器604和多个高速扩展端口610的高速接口608、以及连接到低速扩展端口610的低速接口612。处理器602、存储器604、存储设备606、高速接口608、高速扩展端口610和低速接口612中的每一个是使用各种总线互连,并且可以安装在一个公共的主板或其它适当的方式安装。处理器602可以处理用于在计算设备600内执行的指令,包括存储在存储器604中或存储设备606上的指令,以在例如与高速接口608连接的显示器616的、外部输入/输出设备上显示gui的图形信息。在其它实施方式中,可以视情况使用多个处理器和/或多个总线以及多个存储器和多个存储器类型。此外,可以连接多个计算设备,每个设备提供必要操作的一部分,例如,作为服务器组、刀片服务器组、或多处理器系统)。
92.存储器604在计算设备600内存储信息。在一些实施方式中,存储器604是易失性存
储器单元或多个单元。在一些实施方式中,存储器604是非易失性存储器单元或多个单元。存储器604也可以是另一种形式的计算机可读介质,例如磁盘或光盘。
93.存储设备606能够为计算设备600提供大容量存储。在一些实施方式中,存储设备606可以是或包含计算机可读介质,例如软盘设备、硬盘设备、光盘设备或磁带设备、闪存或其他类似的固态存储设备,或一组设备,包括存储区域网络或其他配置中的设备。指令可以存储在信息载体中。当由一个或多个处理设备(例如,处理器602)执行时,指令执行例如上述那些方法的一种或多种方法。指令还可以存储于一个或多个存储设备,例如计算机或机器可读介质(例如,存储器604、存储设备606或处理器602上的存储器)。
94.高速接口608管理计算设备600的带宽密集型操作,而低速接口612管理较低带宽密集型操作。这种功能分配只是示例。在一些实施方式中,高速接口608连接到存储器604、显示器616(例如,通过图形处理器或加速器)、以及高速扩展接口610,其可以接受多种扩展卡(未示出)。在该实施方式中,低速接口612连接到存储设备606和低速扩展端口614。包括各种通信端口(例如,usb、蓝牙、以太网、无线以太网)的低速扩展端口614可以连接到一个或多个输入/输出设备,例如键盘、指点设备、扫描仪、或网络设备,如交换机或路由器,例如,通过网络适配器。
95.如图所示,计算设备600可以以多种不同的形式实现。例如,它可以以标准服务器620实现,或者在一组这样的服务器中多次实现。此外,它可以在例如膝上计算机622的个人计算机中实现。它也可以以机架服务器系统624的一部分实现。可选地,来自计算设备600的各部件可以与移动设备(未示出)中的其它部件组合,移动设备例如移动计算设备650。每个这样的设备可以包含计算设备600和移动计算设备650中的一个或多个,并且整个系统可以由彼此通信的多个计算设备组成。
96.移动计算设备650包括处理器652、存储器664、诸如显示器654的输入/输出设备、通信接口666、和收发器668,以及其它部件。移动计算设备650还可以配备有存储设备,例如微驱动器或其它设备,以提供额外的存储。处理器652、存储器664、显示器654、通信接口666和收发器668中的每一个使用多种总线互连,并且可以将几个部件安装在公共主板上或以其它适当的方式安装。
97.处理器652可以执行移动计算设备650内的指令,包括存储在存储器664中的指令。处理器652可以以包括单独的和多个模拟和数字处理器的芯片组实现。处理器652可以提供例如用于移动计算设备650的其它部件的协调,例如控制用户界面、移动计算设备650运行的应用程序、和移动计算设备650的无线通信。
98.处理器652可以通过控制接口658和连接到显示器654的显示接口656来与用户通信。显示器654可以是例如tft显示器(薄膜晶体管液晶显示器)或oled(有机发光二极管)显示器,或其它合适的显示技术。显示接口656可以包括用于驱动显示器654以向用户呈现图形和其它信息的合适电路。控制接口658可以从用户接收命令并且将它们转换以提交给处理器652。此外,外部接口662可以提供与处理器652的通信,以便使移动计算设备650能够与其它设备进行近区通信。外部接口662可以提供例如在一些实施方式中的有线通信,或其它实施方式中的无线通信,并且也可以使用多个接口。
99.存储器664在计算设备650内存储信息。存储器664可以以计算机可读介质或介质、易失性存储器单元、或非易失性存储器单元中的一个或多个实现。还可以提供扩展存储器
674并通过扩展接口672连接到移动计算设备650,扩展接口672可以包括例如simm(single in line memory module)卡接口。扩展存储器674可以为移动计算设备650提供额外的存储空间,或者也可以为移动计算设备650存储应用程序或其它信息。具体地,扩展存储器674可以包括执行或补充上述过程的指令,并且还可以包括安全信息。因此,例如,扩展存储器674可以作为移动计算设备650的安全模块提供,并且可以用允许安全使用移动计算设备650的指令编程。此外,可以通过simm卡提供安全应用程序以及附加信息,例如以不可破解的方式将识别信息放置在simm卡上。
100.如下所述,存储器可以包括例如闪存和/或nvram存储器(非易失性随机存取存储器)。在一些实施方式中,指令被存储在信息载体中,该指令在由一个或多个处理设备(例如,处理器652)执行时执行如上所述的一种或多种方法指令还可以存储于一个或多个存储设备,例如一个或多个计算机或机器可读介质(例如,存储器664、存储设备674、或处理器652上的存储器)。在一些实施方式中,指令可以在传播信号中接收,例如,通过收发器668或外部接口662接收。
101.移动计算设备650可以通过通信接口666进行无线通信,通信接口666在必要时可以包括数字信号处理电路。通信接口666可以提供各种模式或协议下的通信,例如gsm(全球移动通信系统)语音呼叫、sms(短消息服务)、ems(增强型消息服务)或mms消息(多媒体消息)、cdma(码分多址)、tdma(时分多址)、pdc(个人数字蜂窝)、wcdma(宽带码分多址)、cdma2000或gprs(通用分组无线服务)等。例如,这种通信可以使用射频通过收发器668发生。此外,可能会发生短距离通信,例如使用蓝牙、wifi或其它此类收发器(未示出)。此外,gps(全球定位系统)接收器模块670可以向移动计算设备650提供附加的导航和位置相关的无线数据,这些数据可以由在移动计算设备650上运行的应用适当使用。
102.移动计算设备650还可以使用音频编解码器660进行可听通信,该音频编解码器660可以从用户接收语音信息并将其转换为可用的数字信息。音频编解码器660同样可以为用户生成可听声音,例如通过如在移动计算设备650的手机中的扬声器。该声音可以包括来自语音电话呼叫的声音,可以包括录制的声音(例如,语音消息、音乐文件等),也可以包括在移动计算设备650上运行的应用生成的声音。
103.如图所示,计算设备650可以以多种不同的形式实现。例如,它可以以蜂窝电话680实现。它也可以作为智能电话682、个人数字助理、或其它类似移动设备的一部分来实现。
104.此处描述的系统和技术的各种实现可以在数字电子电路、集成电路、专门设计的asic(专用集成电路)、计算机硬件、固件、软件和/或它们的组合中实现。这些各种实现可以包括在一个或多个计算机程序中的实现,这些计算机程序在包括至少一个可编程处理器的可编程系统上可执行和/或解释,该处理器可以是特殊用途或一般用途,其从存储系统接收、至少一个输入设备和至少一个输出设备的指令。
105.这些计算机程序(也称为程序、软件、软件应用、或代码)包括用于可编程处理器的机器指令,并且可以用高级过程、和/或面向对象的编程语言、和/或汇编/机器语言来实现。如本文所用,术语机器可读介质和计算机可读介质是指用于向可编程处理器提供机器指令和/或数据的任何计算机程序产品、装置和/或设备(例如,磁盘、光盘、存储器、可编程逻辑设备(pld),包括接收作为机器可读信号的机器指令的机器可读介质。术语机器可读信号是指用于向可编程处理器提供机器指令和/或数据的任何信号。
106.为了提供与用户的交互,这里描述的系统和技术可以在具有显示设备(例如,crt(阴极射线管)或lcd(液晶显示器)监视器)的计算机上实现,用于向用户、键盘、和定点设备(例如,鼠标或轨迹球)显示信息,用户可以通过它向计算机提供输入。也可以使用其他类型的设备来提供与用户的交互;例如,提供给用户的反馈可以是任何形式的感官反馈(例如,视觉反馈、听觉反馈或触觉反馈);并且可以以包括声学、语音或触觉输入的任何形式来接收来自用户的输入。
107.这里描述的系统和技术可以在计算系统中实现,计算系统包括后端部件(例如,作为数据服务器)、或者包括中间件部件(例如,应用服务器)、或者包括前端部件(例如,具有图形用户界面或web浏览器的客户端计算机,用户可以通过其与此处描述的系统和技术的实现进行交互)、或者这些后端、中间件或前端部件的任意组合。系统的各部件可以通过任何形式或媒介的数字数据通信(例如,通信网络)互连。通信网络的示例包括局域网(lan)、广域网(wan)和互联网。在一些实施方式中,这里描述的系统和技术可以在嵌入式系统上实现,其中语音识别和其他处理直接在该设备上执行。
108.计算系统可以包括客户端和服务器。客户端和服务器通常彼此远离并且通常通过通信网络进行交互。客户端和服务器的关系是由于在各自的计算机上运行的计算机程序而产生的,并且彼此之间具有客户端
‑
服务器关系。
109.尽管上面已经详细描述了一些实施方式,但是其它修改也是可能的。例如,虽然客户端应用被描述为访问委托,但在其它实施方式中,该委托可以由一个或多个处理器实现的其他应用使用,应用例如为在一个或多个服务器上执行的应用。此外,图中描绘的逻辑流程不需要所示的特定顺序、或顺序顺序,来实现期望的结果。此外,可以从所描述的流程中提供其它动作,或者可以消除动作,并且可以将其它部件添加到所描述的系统中,或从所描述的系统中删除。因此,其它实施方式在以下权利要求的范围内。