1.本发明涉及分子遗传学技术领域,具体涉及与燕麦产量相关的分子标记及其应用。
背景技术:
2.燕麦营养丰富,与小麦、水稻、玉米等作物相比,燕麦的蛋白质、不饱和脂肪酸、维生素、矿物质元素等营养指标均位居前列,因而燕麦是谷物中最好的全价营养食品之一。燕麦又是公认的保健食品。近年来随着人民生活水平的提高和燕麦营养保健功效知识的宣传,如今燕麦不仅是产地居民的消费口粮,更是人们均衡营养、实行科学饮食的功能食品,对燕麦产品的需求日益增加。但由于燕麦育种水平落后,燕麦产量低,平均亩产只有300~400斤,限制了燕麦产业发展。燕麦产量是由单位面积穗数、穗粒数和千粒重3个因素共同决定的,其中千粒重是重要的籽粒性状,受籽粒粒型的影响。在其它作物中的研究表明,在构成作物产量的三要素中,千粒重的遗传比较稳定,例如在水稻中其变异系数为40%~60%,增加千粒重可提高水稻产量30%以上,是提高产量的有效途径(王军,杨杰,徐祥,朱金燕,范方军,李文奇,王芳权,仲维功.水稻千粒重基因tgw6功能标记的开发与利用.中国水稻科学,2014,28(5):473-478)。
3.gw2基因是song等在水稻中克隆到的一个控制粒宽和粒重的主效基因,编码一个新类型的ring型e3泛素连接酶,通过将其底物锚定到蛋白酶体进行降解,从而负调节细胞的分裂(song xj,huang w,shi m,zhu mz,lin hx.a qtl for rice grain width and weight encodes a previously unknown ring-type e3 ubiquitin ligase.nat genet,2007,39:623
–
630)。序列分析发现gw2大粒水稻中氨基酸残基的缺失使gw2无法结合底物,无法控制泛素介导的蛋白质降解,进而导致颖花外壳细胞分裂和细胞数目增加,从而正调控颖花外壳的宽度,增加了粒重。而对小麦中gw2基因的研究表明,小麦中存在一个osgw2的同源基因tagw2,不同籽粒大小的品种并不存在序列上的差异,然而对于启动子区域的研究表明启动子区域两个单核苷酸多态性会导致小麦粒宽和粒重的变化(su zq,hao cy,wang lf,dong yc,zhang xy.identification and development of a functional marker of tagw2associated with grain weight in bread wheat(triticum aestivum l.).theor appl genet,2011,122:211
–
223)。这些研究表明gw2基因可显著增加谷粒的宽度,加快籽粒灌浆速度,增加粒重以及产量。
4.关联分析是一种基于连锁不平衡现象将标记与目标性状表型联系起来的分析方法。关联分析主要包括两种策略:即基于全基因组扫描和基于候选基因的关联分析。在基于全基因组扫描的关联分析中,需要用分布于全基因组的高通量标记对某物种大群体的所有基因进行同时检测。在实际应用中,由于受不同染色体上标记数量差异及基因型鉴定成本和繁重统计分析工作量等因素的限制,很难在植物中做到真正意义上的利用大群体进行高通量标记检测分析。而从生化角度来看,生物中某一性状的表达无外乎就是各种蛋白参与下的各种酶促反应共同作用结果,所以编码相关蛋白的基因差异所导致的蛋白活性变化也
会引起性状变化。因而通过检测候选基因在相关群体中的变异来发掘与表型变异密切相关的功能等位变异是切实可行的。
5.但相关标记的发掘有赖于基因的克隆、材料的正确选择、相关技术经验等,而且即便是克隆出相关基因也并非保证能够发掘出有用的标记,因此此类研究不仅具有技术要求、材料要求还具有很强的不可预期性。
技术实现要素:
6.本发明的目的是提供一种涉及燕麦gw2基因内的与千粒重显著相关的snp标记、扩增其的引物对以及该分子标记的应用。
7.具体地,本发明提供以下技术方案:
8.第一方面,本发明提供一种与燕麦产量相关的分子标记,其含有如seq id no.1所示序列第274位的多态性为a/g的核苷酸序列。
9.本发明所提供的与燕麦产量性状相关的snp(单核苷酸多态性)分子标记位点来源于燕麦ring型e3泛素连接酶基因gw2,位于本发明所列seq id no.1(其位点侧翼序列)中自5’末端起第274位核苷酸,该序列第274bp位核苷酸为a或g。
10.本发明收集了不同地理来源的96份燕麦种质资源,作为研究的关联群体,利用同源克隆方法获得其gw2基因序列,通过多序列比对,发掘该基因在96份燕麦种质资源中的变异位点。结合多年多点96份燕麦种质资源千粒重数据,以gw2基因为候选基因,利用tassel软件的一般线性模型和混合线性模型两种方法对候选基因进行关联分析,检测到一个与燕麦千粒重显著关联的snp位点。该位点的等位基因为a和g,在供试自交系中有a/a和g/g两种纯合基因型,其侧翼序列如seq id no.1所示。
11.本发明所述分子标记可由序列如seq id no.2-4所示的引物扩增得到。
12.所述分子标记的多态性位点为a时,对应于燕麦籽粒重量大;所述分子标记的多态性位点为g时,对应于燕麦籽粒重量小。
13.本发明提供的snp分子标记与燕麦籽粒重量显著相关,snp位点基因型为a/a的燕麦种质资源千粒重大于位点基因型为g/g燕麦种质资源。
14.第二方面,本发明提供用于检测上述分子标记的特异性引物组,其包含具有如seq id no.2所示序列的上游引物以及具有如seq id no.3-4所示序列的下游引物;
15.上游(f):5
’‑
gccactgatgtgtggggttgctt-3’(seq id no.2);
16.下游(r):5
’‑
gaaggtgaccaagttcatgctttgtataaaaaccaacggcacca-3’(seq id no.3);
[0017]5’‑
gaaggtcggagtcaacggattctttgtataaaaaccaacggcaccg-3’(seq id no.4)。
[0018]
本发明提供的引物组包含2条下游引物以及1条上游引物,3条引物配合使用,能够利用kasp(kompetitive allele specific pcr)技术检测所述分子标记的基因型。
[0019]
为便于采用kasp技术进行检测,所述下游引物的5’端还连接有荧光标签序列。
[0020]
对于连接的荧光标签序列,本发明没有特殊限制,只要保证2条下游引物连接的荧光标签序列所对应的荧光标记不同即可。
[0021]
作为本发明的一种实施方式,seq id no.3所示引物的5’端连接有fam荧光基团,seq id no.4所示引物的5’端连接有hex荧光基团。
[0022]
本发明还提供含有上述特异性引物组的试剂盒。
[0023]
除包含上述特异性引物组外,所述试剂盒还可包含选自如下试剂中的一种或多种:dntp、mg
2+
、dna聚合酶、ddh2o、pcr反应缓冲液;上述试剂可单独包装,也可以预混液的形式混合包装。
[0024]
第三方面,本发明提供上述分子标记或特异性引物组或试剂盒的如下任一种应用:
[0025]
(1)在鉴定燕麦粒重特性中的应用;
[0026]
(2)在籽粒重量大的燕麦的分子标记辅助育种中的应用;
[0027]
(3)在燕麦籽粒重量性状的种质资源改良中的应用。
[0028]
本发明中,所述应用包括:以待测燕麦的dna为模板,采用具有如seq id no.2-4所示序列的引物进行pcr扩增,根据pcr扩增产物判断待测燕麦的粒重特性。
[0029]
优选地,所述pcr扩增的反应程序如下:94℃预变性15min;94℃20s,61℃1min,9个循环;94℃20s,55℃1min,25个循环;最后37℃延伸1min;4℃保存。
[0030]
优选地,所述pcr扩增的反应体系中,具有seq id no.3、seq id no.4、seq id no.2所示序列的引物的摩尔比为2:2:5。
[0031]
本发明中,若读取到的荧光信号仅为具有seq id no.3所示序列的引物对应的荧光信号,则判断待测燕麦籽粒重量大;若读取到的荧光信号仅为具有seq id no.4所示序列的引物对应的荧光信号,则判断待测燕麦籽粒重量小。
[0032]
第四方面,本发明提供一种检测高产燕麦gw2基因型的方法,其利用上述特异性引物组,对待检测燕麦基因组dna进行pcr扩增,分析pcr扩增产物中上述分子标记的基因型,如果所述分子标记的多态性位点的基因型为aa,则所述待检测燕麦存在高产(高千粒重)燕麦gw2基因型。
[0033]
本发明的有益效果在于:
[0034]
本发明结合gw2基因在不同地理来源燕麦种质资源中的序列多样性,利用候选基因关联分析策略揭示该基因与燕麦千粒重之间的内在联系,发掘其中显著的功能位点,并作为遗传标记应用于燕麦分子育种,对提升燕麦品质具有重要意义。
[0035]
本发明运用候选基因关联分析方法,能够快速、精确地检测与特定性状显著关联的分子标记位点。本发明的分子标记,可解释的表型变异为3.13%,其能够作为遗传标记,用于大籽粒、高产燕麦育种,具有较高的应用价值。
附图说明
[0036]
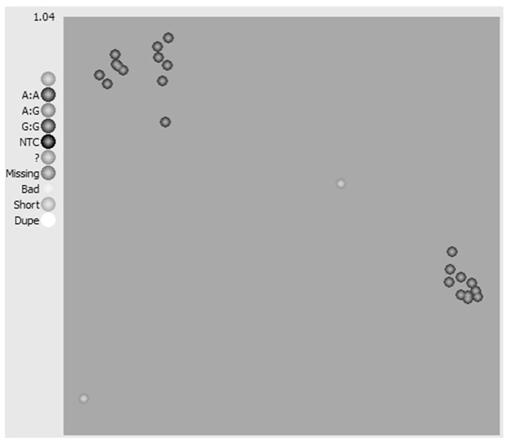
图1为24份燕麦种质资源种基于kasp技术的snp分析。图中左上角的圆点表示基因型“a/a”,右下角的圆点表示基因型“g/g”。
[0037]
图2为ril群体中202个家系基于kasp技术的snp分析。图中左上角的圆点表示基因型“a/a”,右下角的圆点表示基因型“g/g”。
[0038]
图3为ril群体“a/a”和“g/g”两个基因型个体的千粒重比较(p≤0.01)。ril群体中具有“a/a”基因型和“g/g”基因型的家系分别为74和93个。
[0039]
图4为所用关联分析燕麦群体中千粒重分布频率,横坐标单位为g。
具体实施方式
[0040]
以下实施例用于说明本发明,但不用来限制本发明的范围。若未特别指明,下述实施例中所用的材料、试剂等均可从商业途径得到。若未特别指明,实施例中所用的技术手段为本领域技术人员所熟知的常规手段。若未特别指明,下述实施例中的百分含量,均为质量百分含量。
[0041]
实施例1燕麦gw2基因与千粒重显著相关的一个snp分子标记的获得及其检测引物的确定
[0042]
本发明燕麦gw2基因与千粒重显著相关的一个snp分子标记是通过以下方法获得的:
[0043]
1)收集获得96份来自不同地理来源的燕麦种质资源,构建了作图所用的关联群体。该群体有着丰富的遗传多样性。
[0044]
2)关联群体籽粒千粒重测定。2018-2020年间,将收集来的材料分别种植在中国农业科学院昌平试验基地,张家口农业科学院坝上试验站,和新疆农业科学院昌吉试验站,正常实验管理,无特殊处理,收获后的种子用于千粒重测定分析。方法简述如下:籽粒及时晒干并风干保存30d以上,使含水量保持在13%左右,用电子天平单独称取每份品种每个单株100粒饱满燕麦籽粒的质量,取其5个单株的平均值,折算为千粒重。结果表明,96份燕麦的千粒重平均值为20.35g,标准差为4.263,呈正态分布,可以用于关联分析(图4)。
[0045]
3)燕麦gw2基因的克隆和测序。根据genbank中收录的其它物种gw2基因保守区序列,设计引物(p1:5'-gtgtcccatctgcttcctgt-3',seq id no.5;p2:5'-ccgctccagctatctagtgaa-3',seq id no.6)扩增燕麦cdna;电泳回收pcr产物,回收产物在abi 3730测序仪上进行测序,测序结果在ncbi数据库中比对分析,确定所获得片段为目的基因片段。
[0046]
根据所克隆到的基因片段设计特异引物,利用基因组步移技术,扩增gw2基因上下游侧翼序列,具体方法按照genomewalkeruniversal kit(clontech)试剂盒说明书进行,使用不同平末端内切酶对基因组dna酶切后,与试剂盒中的接头连接建库。
[0047]
使用试剂盒提供的引物ap1:5
′‑
gtaatacgactcactatagggc-3
′
,seq id no.7和特异引物(pwu1:5'-atgcttggtggttggtgctcagtcata-3',seq id no.8;pwd1:5'-cgatgtaccgagcaagaaaccgaatgt-3',seq id no.9)进行pcr扩增,先行7个循环94℃25s,72℃3min,再行32个循环,94℃25s,67℃3min,最后一个循环67℃7min。取该pcr产物稀释50倍后为模板,以ap2:5
′‑
caccggccttgaagttatggtagtgtt-3
′
,seq id no.10和特异引物(pwu2:5'-cttctgttgttggagcgattgttctgc-3',seq id no.11;pwd2:5'-ttgctgctatgactgagcaccaaccac-3',seq id no.12)为引物进行巢式扩增,反应程序同上。扩增产物转化、鉴定、测序、拼接。根据拼接结果设计引物(f:5'-cgcccacggtgaaatgctgatg-3',seq id no.13;r:5'-gattagcacatcgcccactctg-3',seq id no.14),扩增出gw2基因在燕麦基因组中的相应序列。
[0048]
以关联群体的燕麦基因组dna为模板,采用pyrobest高保真聚合酶(宝生物)进行pcr扩增,程序为:94℃预变性3min;95℃10s,56℃30s,68℃3min,35个循环;最后68℃延伸5min;4℃保存。利用abi 3730测序仪对扩增产物进行序列测定。对测序峰图有杂峰或套峰的样品重新扩增、测序验证。对测序结果进行拼接,多序列联配比对,并局部手动调整,最终
得到14个snp和2个indel。
[0049]
4)候选基因gw2的关联分析。结合步骤2)中燕麦种质资源千粒重表型数据与步骤3)中的分子数据,分别利用关联分析软件tassel的一般线性模型(glm)和混合线性模型(mlm)进行关联分析,等位基因频率阈值设为0.05。结果发现该基因中存在一个snp位点与燕麦千粒重含量显著相关,glm和mlm模型的检测p值分别为0.0086和0.0037,可解释的表型变异分别为2.28%和3.13%。两个不同模型的相互验证,避免了在0.01水平该位点关联结果的假阳性可能,进一步证实了结果的真实可靠性。
[0050]
基于该位点获得的本发明的分子标记含有如seq id no.1所示序列第274位的多态性为a/g的核苷酸序列。
[0051]
用于检测上述分子标记的特异性引物组包含如seq id no.2-3所示的序列。
[0052]
实施例2本发明的snp标记在燕麦千粒重上的应用实验
[0053]
1)snp标记在部分燕麦品种中的检测。
[0054]
为进一步验证本发明分子标记的有效性,本发明在实施例1的关联群体中随机挑选24份燕麦品种,以其dna为模板,利用竞争性等位基因特异性pcr(kompetitive allele specific pcr),即kasp技术,基于lgc genomics公司的snpline基因型分型技术平台,对待检测样本进行snp检测。
[0055]
具体方法为:随机选取24份燕麦品种,以燕麦基因组dna为模板,以该位点侧翼序列的特异性引物(seq id no.2、5’端连接有fam荧光基团的seq id no.3,5’端连接有hex荧光基团的seq id no.4)为引物,利用竞争性等位基因特异性pcr技术,对待检测样本进行snp检测。
[0056]
pcr扩增的反应程序如下:94℃预变性15min;94℃20s,61℃1min,9个循环;94℃20s,55℃1min,25个循环;最后37℃延伸1min;4℃保存。
[0057]
kasp用pcr反应体系如下:10μl体系,其中5μl dna(2.5ng/μl),5μl 2
×
kasp master mix,0.14μl kbd mix。
[0058]
所述kbd mix中5’端连接有hex荧光基团的seq id no.3、5’端连接有fam荧光基团的seq id no.4和seq id no.2所示序列的引物的摩尔比为2:2:5。
[0059]
结果显示该位点特异性引物成功地对待检测材料完成了基因分型,24份自交系在该位点上被划分为12份a/a(仅有seq id no.3引物对应的荧光信号)和10份g/g(仅有seq id no.4引物对应的荧光信号)两类基因型(参见图1),进一步证明了本发明中关联分析检测结果及引物设计的准确性。
[0060]
2)该snp标记在燕麦遗传群体中的应用。
[0061]
具体方法为:分别筛选和鉴定出高千粒重品种“578”和低千粒重品种“三分三”,并以“578”和“三分三”为亲本构建了包含202个家系的ril群体。以群体中各家系及两亲本dna为模板,以该snp位点侧翼序列的特异性引物(seq id no.2、5’端连接有fam荧光基团的seq id no.3,5’端连接有hex荧光基团的seq id no.4)为引物。pcr扩增的反应体系和程序均同实施例2中试验1)。在ril群体的202个家系中有167个家系被成功分型,基因型a/a和g/g的家系个数分别为74和93(参见图2)。根据实施例1中步骤2)记载的方法对被成功分型的家系进行千粒重检测,带有g/g基因型家系的千粒重均值为17.75g,带有a/a基因型家系的千粒重均值为21.04g,两者之间差异显著(p《0.01),参见图3。即在该ril群体中,snp位点与籽粒
大小存在显著相关性,与gw2基因在96份不同来源的燕麦种质资源中的关联分析结果一致。等位基因a被视作优异/增效等位基因。
[0062]
由此可知,本发明进一步证实了该snp位点能够作为有效的遗传标记应用于分子标记辅助选择,提升燕麦产量,提高优质燕麦育种效率。
[0063]
虽然,上文中已经用一般性说明及具体实施方案对本发明作了详尽的描述,但在本发明基础上,可以对之作一些修改或改进,这对本领域技术人员而言是显而易见的。因此,在不偏离本发明精神的基础上所做的这些修改或改进,均属于本发明要求保护的范围。