每液滴多个珠的解决方案
1.相关申请的交叉引用
2.本技术要求2019年6月7日提交的美国临时申请号62/858,940和2019年6月14日提交的美国临时申请号62/861,959的权益,其全部公开通过引用全文纳入本文以用于所有目的。
3.以ascii文本文件提交的
″
序列表
″
、表格、或计算机程序表附页的引用
4.将2020年6月4日于机器型号ibm-pc,ms-windows操作系统创建的2,812字节的文件094868-1190275-116910pc_sl.txt中所记载的序列表通过引用全文纳入本文用于所有目的。
5.发明背景
6.通过分子条形码的测序和对其分析,在分区中用分子条形码给生物底物加标签可以对共定位到离散分区的底物提供新的生物学了解。增加条码化活性分区(barcoding competent partition)(例如液滴)的数量,增加了基于测序的数据点的数量,并将更大部分的输入底物转化为数据。使用珠作为递送载剂,可以将条形码递送进分区,例如液滴。因此,分区中的条形码珠过载产生具有多于一个珠的分区并增加条码化活性分区的百分比,提供更高的底物至测序数据转化率。然而,当两个或更多条形码出现在离散分区中时,底物和数据会在两个条形码之间分开,产生分离的数据点。本公开提供了对分区中存在多于一个条码化珠时产生的问题的解决方案,例如与分离的数据点相关的问题。
7.发明概述
8.本文描述了用于检测分区中多个条码化固体支持物的存在的方法,其包含条码化的固体支持物的组合物以及用于生产条码化固体支持物的方法。
9.一方面,该方法包括,按以下顺序:
10.a)提供多个分区,其中至少一些分区包含多个固体支持物,每个固体支持物连接至不同的固体支持物寡核苷酸,所述固体支持物寡核苷酸包含对于固体支持物独特的条形码;
11.b)合成寡核苷酸的互补序列以产生具有来自两种固体支持物寡核苷酸的条形码的双链多核苷酸;
12.c)测序双链多核苷酸的一条或两条链,其中包含两种不同的条形码的序列表示在所述提供步骤中,两种固体支持物存在于同一分区中。
13.在一些实施方式中,例如在步骤a)和b)之间从固体支持物裂解包含条形码的固体支持物寡核苷酸。在一些实施方式中,步骤b)在分区内进行。在一些实施方式中,该方法进一步包括在步骤b)之后合并分区的内容物。在一些实施方式中,步骤b)在分区外进行。
14.在一些实施方式中,步骤b)包括将固体支持物寡核苷酸与r2逆转座酶接触。在一些实施方式中,步骤b)包括将固体支持物寡核苷酸与逆转录酶接触。在一些实施方式中,步骤b)包括将固体支持物寡核苷酸与dna聚合酶接触。
15.在一些实施方式中,双链衔接子被添加至双链多核苷酸上。在一些实施方式中,通过将双链多核苷酸与载有衔接子的转座酶或标签化酶接触以添加双链衔接子。
16.在一些实施方式中,通过单链连接酶添加第二条形码序列。
17.在一些实施方式中,步骤b)是不依赖模板的。
18.在一些实施方式中,固体支持物寡核苷酸进一步包含通用引物结合序列。
19.在一些实施方式中,分区是乳液中的液滴。
20.在一些实施方式中,固体支持物寡核苷酸被附接至样品核酸序列。样品核酸序列可以是rna、mrna或dna。
21.在一些实施方式中,样品核酸序列衍生自单细胞。
22.在一些实施方式中,固体支持物寡核苷酸进一步包含捕获序列,分区进一步包含具有互补于捕获序列的3’末端和5’回文序列的检测寡核苷酸(detector oligonucleotide),以及所述方法进一步包括:
23.d)在分区中,在聚合酶存在的情况下,一些固体支持物寡核苷酸的捕获序列杂交至检测寡核苷酸的3’末端,以产生延长的固体支持物寡核苷酸,其包含检测寡核苷酸的互补物,其中所述延长的检测固体支持物寡核苷酸包含互补于回文序列的3’末端;以及
24.e)在分区中,杂交延长的固体支持物寡核苷酸的3’末端,并用聚合酶延伸延长的检测固体支持物寡核苷酸的3’末端,从而形成具有来自两种固体支持物寡核苷酸的条形码的双链多核苷酸。
25.在一些实施方式中,固体支持物寡核苷酸与检测寡核苷酸的比率为至少5∶1至100,000∶1。
26.在一些实施方式中,至少一些固体支持物寡核苷酸捕获序列杂交至样品核酸,并且由聚合酶延伸以产生包含样品核酸的互补物的延长的样品固体支持物寡核苷酸。所述测序可包括测序延伸的样品固体支持物寡核苷酸以产生具有固体支持物条形码和样品核酸序列的测序读数。
27.在实施方式中,该方法进一步包括按分区对测序读数去卷积,其中如果序列读数包含两种不同的条形码,则认为具有两种不同条形码的两个不同测序读数是来自同一分区。
28.在本文所述的任何实施方式中,回文序列可以是4到250个核苷酸之间的长度,包括4到250个核苷酸之间的任何整数值范围的长度,例如从4、5、6、7、8、9或10个核苷酸至20、30、40、50、60、70、80、90、100、150、200或250个核苷酸的长度,例如10至20、10至30、20至30或20至40个核苷酸的长度。在一些实施方式中,回文序列包含10-20个核苷酸的区域和包含其反向互补物的区域,使得回文序列的总长度为20-40个核苷酸。
29.在本文所述的任何实施方式中,条形码可以是4到250个核苷酸之间的长度,包括4和250个核苷酸之间的任何整数值范围的长度,例如从4、5、6、7、8、9或10个核苷酸至20、30、40、50、60、70、80、90、100、150、200或250个核苷酸的长度。
30.在一些实施方式中,在步骤e)和f)之间从固体支持物裂解具有条形码的双链多核苷酸。
31.在一些实施方式中,固体支持物寡核苷酸通过尿嘧啶碱基连接至固体支持物,该方法包括:将固体支持物寡核苷酸固体支持物寡核苷酸与udg酶(udgase)接触,从而从固体支持物裂解固体支持物寡核苷酸。
32.在一些实施方式中,固体支持物寡核苷酸包含一个或多个生物素或生物素类似
物,并且该方法包括:通过将裂解的固体支持物寡核苷酸结合至连接链霉亲和素的固体支持物,并从连接链霉亲和素的固体支持物上洗涤未结合的组分,以纯化裂解的固体支持物寡核苷酸;并洗脱裂解的固体支持物寡核苷酸。
33.在一些实施方式中,连接链霉亲和素的固体支持物是磁珠或顺磁珠。
34.在一些实施方式中,步骤e)包括2-5个循环的聚合酶链式反应(pcr)。
35.在一些实施方式中,固体支持物是珠。
36.在另一方面,描述了一种用于产生附接至两个或更多不同寡核苷酸的固体支持物的方法,该方法包括将第一寡核苷酸附接至所述固体支持物,其中所述第一寡核苷酸包含对于固体支持物独特的条形码、捕获序列和测序衔接子;
37.将第二寡核苷酸附接至固体支持物,其中第二寡核苷酸包含3’末端的回文序列、测序衔接子和对于固体支持物独特的条形码。
38.在一些实施方式中,寡核苷酸被化学偶联至固体支持物。
39.在一些实施方式中,寡核苷酸被非共价附接至固体支持物。
40.在另一方面,提供了一种组合物,所述组合物包含含有两个或更多固体支持物的分区,所述固体支持物附接至含有条形码序列的寡核苷酸,其中每个固体支持物被连接或附接至不同的寡核苷酸,并且寡核苷酸包含对于附接的固体支持物独特的条形码。
41.在另一方面,描述了一种用于产生用于测序的核酸分子文库的方法,该方法包括:
42.a)提供多个分区,其中至少部分分区包含单个细胞和多个固体支持物,其中同一分区中不同的固体支持物被连接至第一和第二固体支持物寡核苷酸,所述第一固体支持物寡核苷酸包含对于固体支持物独特的条形码、捕获序列和测序衔接子,所述第二固体支持物寡核苷酸包含3’末端的回文序列、测序衔接子和对于固体支持物独特的条形码;
43.b)从固体支持物释放寡核苷酸,并将rna片段杂交至一个或多个第一寡核苷酸的捕获序列,以形成rna/寡核苷酸杂交体;
44.c)将包含回文序列的第二固体支持物寡核苷酸互相杂交;
45.d)延伸杂交的寡核苷酸以形成包含第一和第二条形码的双链dna二聚体分子,其中第一和第二条形码来自同一分区中的相同或不同固体支持物寡核苷酸;
46.e)扩增dna分子以产生核酸分子文库;
47.f)释放分区内容物,将杂交至第一寡核苷酸的rna与r2逆转座酶接触,以在受体模板存在的情况下合成cdna以添加3’衔接子序列;
48.g)扩增包含cdna和3’衔接子的第一寡核苷酸以产生包含衔接子序列的cdna文库;以及
49.h)测序步骤(g)和(i)的文库中的核酸分子,其中包含相同条形码的多个序列(sequences)即表示这些固体支持物(solid supports)存在于同一分区中。
50.在一些实施方式中,第一和第二固体支持物寡核苷酸包含或被附接至相同的独特条形码序列。
51.在一些实施方式中,该方法进一步包括裂解细胞以释放rna。在一些实施方式中,该方法进一步包括片段化rna以产生rna片段。
52.在一些实施方式中,分区包含dna聚合酶、二价离子、测序衔接子、三磷酸脱氧核苷酸(dntp)和至少3’序列互补于测序衔接子的引物。在一些实施方式中,分区进一步包含多
聚(a)聚合酶和atp,并且多聚-a尾被添加到rna片段上。
53.在一些实施方式中,第一和/或第二固体支持物寡核苷酸包含尿嘧啶碱基,通过将寡核苷酸与udg酶或user酶接触,从固体支持物释放寡核苷酸。
54.在一些实施方式中,步骤(g)包含解链双链dna分子并将引物杂交至测序衔接子,使用聚合酶延伸引物,并通过pcr扩增延伸的分子。
55.在一些实施方式中,捕获序列包含多聚dt、随机序列或基因特异性序列。
56.在一些实施方式中,分区是微孔或乳液中的液滴。
57.在另一方面,提供了固体支持物,固体支持物连接至
58.(i)多个第一固体支持物寡核苷酸,其包含对固体支持物独特的条形码序列,和捕获序列;以及
59.(ii)多个第二寡核苷酸,其具有包含互补于捕获序列的序列的3’末端、条形码序列和5’回文序列;
60.其中第一固体支持物寡核苷酸与第二寡核苷酸的比率为至少5∶1、10∶1、100∶1、1000∶1、5000∶1、10000∶1、20000∶1;30000∶1.40000∶1、50000∶1;60000∶1、70000∶1;80000∶1、90000∶1或100000∶1。
61.在一些实施方式中,回文序列可以是4到250个核苷酸之间的长度,包括4到250个核苷酸之间的任何整数值范围的长度,例如从4、5、6、7、8、9或10个核苷酸至20、30、40、50、60、70、80、90、100、150、200或250个核苷酸的长度,例如10至20、10至30、20至30或20至40个核苷酸的长度。在一些实施方式中,回文序列包含10-20个核苷酸的区域和包含其反向互补物的区域,使得回文序列的总长度为20-40个核苷酸。在一些实施方式中,条形码可以是4到250个核苷酸之间的长度,包括4和250个核苷酸之间的任何整数值范围的长度,例如从4、5、6、7、8、9或10个核苷酸至20、30、40、50、60、70、80、90、100、150、200或250个核苷酸的长度。
62.在一些实施方式中,第一寡核苷酸进一步包括以下一种或多种:a)尿嘧啶碱基;b)生物素碱基;或d)用于测序反应的衔接子序列。
63.在另一方面,本文提供了包含两个或更多固体支持物的分区,其中每个固体支持物被连接至不同的固体支持物寡核苷酸,所述固体支持物寡核苷酸包含对于固体支持物独特的不同条形码序列。
64.另一方面,提供了包含本文所述固体支持物的试剂盒。在一些实施方式中,试剂盒包含使用说明。
65.在另一方面,描述了一种检测分区中多个条码化固体支持物存在的方法,该方法包括:
66.a)提供了多个分区,其中至少部分分区包含多个固体支持物,其中每个固体支持物被连接至(i)多个第一固体支持物寡核苷酸,其包含对于固体支持物独特的条形码序列,和捕获序列;(ii)一个或多个第二寡核苷酸,其具有包含互补于捕获序列的序列的3’末端、条形码序列和5’回文序列;其中第一固体支持物寡核苷酸与第二寡核苷酸的比率为至少至少5∶1、10∶1、100∶1、1000∶1、5000∶1、10000∶1、20000∶1;30000∶1.40000∶1、50000∶1;60000∶1、70000∶1;80000∶1、90000∶1或100000∶1;
67.b)从固体支持物释放第一和第二寡核苷酸;
68.c)在第一聚合酶存在的情况下,使一些固体支持物寡核苷酸的捕获序列杂交至第
二寡核苷酸的3’末端,以产生延长的固体支持物寡核苷酸,其包含第二寡核苷酸的互补物,其中所述延长的固体支持物寡核苷酸包含3’末端,其
69.d)杂交延长的固体支持物寡核苷酸的3’末端,并用第二聚合酶延伸该3’末端,从而形成具有来自两种固体支持物寡核苷酸的条形码的双链多核苷酸。
70.e)测序双链多核苷酸的一条或两条链,其中包含两种不同的条形码的序列表示两种固体支持物存在于同一分区中。
71.在一些实施方式中,互补于捕获序列的序列包含3’终止子或在3’末端被封闭,以防止被聚合酶延伸。在一些实施方式中,步骤(c)中的第一聚合酶不具有核酸外切酶活性。在一些实施方式中,该聚合酶是therminator
tm dna聚合酶或taq dna聚合酶。
72.在一些实施方式中,第一寡核苷酸进一步包括以下一种或多种:a)尿嘧啶碱基;b)生物素碱基;或d)用于测序反应的衔接子序列。
73.在一些实施方式中,分区是微孔或乳液中的液滴。
74.在另一方面,描述了一种用于产生连接至寡核苷酸的固体支持物的方法,该方法包括:
75.i)提供连接至多个第一固体支持物寡核苷酸的固体支持物,第一寡核苷酸包含对于固体支持物独特的条形码序列和3’捕获序列;
76.ii)将一些固体支持物寡核苷酸的3’捕获序列杂交至具有包含互补于捕获序列的序列的3’末端和5’回文序列的第二寡核苷酸,其中第一固体支持物寡核苷酸与第二寡核苷酸的比率是至少5∶1、10∶1、100∶1、1000∶1、5000∶1、10000∶1、20000∶1;30000∶1.40000∶1、50000∶1;60000∶1、70000∶1;80000∶1、90000∶1或100000∶1;
77.iii)用聚合酶延伸第一固体支持物寡核苷酸,以产生包含第二寡核苷酸的互补物和互补于回文序列的3’末端的延伸的固体支持物寡核苷酸;
78.从而生成固体支持物。
79.在一些实施方式中,通过变性和洗涤除去第二寡核苷酸。
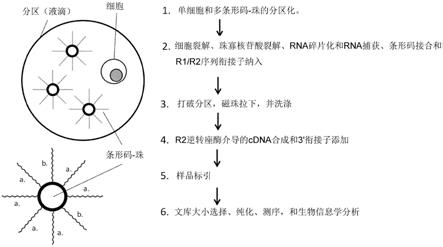
80.在一些实施方式中,第一寡核苷酸包含条形码序列的5’尿嘧啶碱基,且来自步骤(iii)的延伸的固体支持物寡核苷酸通过udg酶从固体支持物上释放,并在第一扩增循环期间通过变性除去第二寡核苷酸。在一些实施方式中,变性在分区内进行。
81.附图简要说明
82.图1显示了不依赖模板的条形码寡核苷酸接合的代表性实施方式。在分区化期间,多于一个条形码珠被封装在单个分区内。寡核苷酸被裂解,使得它们不再与珠物理关联。r2逆转座子找到条形码寡核苷酸的3’末端并从第二条形码寡核苷酸序列的3’末端起始合成。然后这些片段被衔接(例如通过此处所示的连接)并测序。在单段序列中观察到多个条形码序列表明这些条形码珠在条码化期间存在于同一分区中。通用tag序列可用于下游pcr中或测序期间。指示了基于连接的文库制备。
83.图2显示了嵌合珠寡核苷酸序列的基于转座酶的文库制备的代表性实施方式。图中显示的步骤与图1相似,但是使用转座酶完成文库制备。三角形表示转座酶/标签化酶,黑色实心条表示衔接子。
84.图3显示了嵌合珠寡核苷酸序列的逆转录酶生成的代表性实施方式。图中所示的步骤与图2相似,但是不依赖模板的条形码合成是作为逆转录酶的第二反应发生的。
85.图4显示了从如图3所示的嵌合珠寡核苷酸序列的逆转录酶合成产生的序列的代表性实例。从利用凝胶珠在ddseq机器上进行的逆转录反应产生的嵌合序列产生的序列的实例。珠寡核苷酸条形码是由条形码(bc)1、bc2和bc3的组合生成。在读数1和读数2中分别发现了两种不同的珠条形码寡核苷酸序列。来自illumina流动池中相同读数或簇的信息在条形码反应期间将条形码序列下方的相关珠共定位到同一分区。图4按出现的顺序分别公开了seq id no:7-9。
86.图5显示了珠寡核苷酸序列的直接连接的代表性实施方式。在分区化期间,多于一个条形码珠被封装在单个分区内。寡核苷酸被裂解,使得它们不再与珠物理关联。如图所示,单链dna连接酶连接条形码珠寡核苷酸。破乳。使用p7加尾多聚a引物将嵌合体或多联体转化为液滴外的双链产物。制备双链分子用于测序。显示了融合pcr,以添加p5和p7标签,样品制备;然而,这可以通过其他文库制备方法进行。在一个替代性实施方式中,2d逆转座子被用于在单个步骤中衔接分子(显示在右侧)。
87.图6显示了在分区中依赖于模板的嵌合体生成的代表性实施方式。在该实施方式中,珠寡核苷酸序列具有回文3’末端。寡核苷酸在分区中裂解,其中一部分互相杂交。逆转录合成反向互补物。在文库制备过程中衔接是通过融合pcr、连接(如图所示)或其他已知方法完成的。
88.图7显示了本文所述另一个实施方式的步骤。分区通过微流体系统装载有一个细胞和不同量的条形码珠。然后裂解细胞,通过每个分区内的酶促裂解从运载体珠释放条形码寡核苷酸。从细胞裂解物释放出来的rna分子被片段化,然后多聚-a加尾的rna片段被条形码寡核苷酸“a”捕获。来自不同或相同运载体珠的条形码寡核苷酸“b”随机地互相杂交,随后由dna聚合酶延伸以形成分子间和分子内条形码-二聚体。分区破裂后,rna/条形码寡核苷酸杂交体和条形码-二聚体被磁珠拉下。洗涤后,通过逆转录和衔接子添加操作,使用r2逆转座酶,进行cdna合成和3
’‑
衔接子添加。所产生的条形码二聚体和cdna文库被标引化、大小选择和纯化,然后进行下一代测序,并通过生物信息学进行序列分析。
89.图8显示了根据本文所述的一个实施方式的条形码-寡核苷酸偶联珠(条形码-珠)的示意图。条形码-珠包含固体支持物(例如,珠)和被载物(条形码-寡核苷酸)。每个珠携带至少两种条形码-寡核苷酸,例如“a”和“b”,以10,000∶1或更高的比率。条形码-寡核苷酸a.包含(1)辅助dna序列,(2)一个或多个尿嘧啶碱基,(3)任选的生物素标记的核苷酸碱基,(4)测序衔接子序列,(5)条形码,和(6)捕获序列。条形码-寡核苷酸b.进一步包含(7)在其3’末端的回文序列,用于接合条形码。在条形码-寡核苷酸b中,捕获序列是任选的。
90.图9显示了根据本文所述的一个实施方式,分区中珠-寡核苷酸释放、rna片段化和rna-捕获的示意图。条形码-寡核苷酸的酶促裂解发生在一个或多个尿嘧啶碱基处,释放的可溶性条形码-寡核苷酸“a”通过其3’末端捕获序列(例如多聚-t)杂交至多聚-a加尾的rna片段。
91.图10a显示了根据本文所述的一个实施方式,说明了分区中珠-寡核苷酸释放和条形码-寡核苷酸接合的方法的示意图。条形码-寡核苷酸的酶促裂解发生在一个或多个尿嘧啶碱基处,释放的可溶性条形码-寡核苷酸“b”以随机的方式杂交至来自自己的珠或同一分区内其他珠的条形码-寡核苷酸。杂交以形成条形码间-二聚体和条形码内-二聚体之后,由dna聚合酶进行dna聚合和延伸。
92.图10b显示了根据本文所述的一个实施方式说明了条形码杂交的衔接子-接合pcr的示意图。分区内一个pcr循环之后,条形码二聚体成为双链的。然后,在之后的pcr循环中,r1和r2测序衔接子被纳入条形码融合体。由于3’序列共性(sequence commonality),测序衔接子引物r1和r2有平等的机会退火至间/内条形码-二聚体的测序衔接子序列区域。结果,pcr产生4种产物的文库-r1/r1、r1/r2、r2/r1和r2/r2,如所说明。
93.图11显示了分区外大量条形码寡核苷酸捕获、cdna合成和cdna 3
’‑
衔接子添加操作的示意图。分区破裂后,rna/条形码-寡核苷酸杂交体和条形码-二聚体被dna-结合磁珠拉下,或任选地,如果存在一种或多种生物素标记的核苷酸碱基,被链霉亲和素接合磁珠拉下。如所说明的,通过r2逆转座酶的逆转录和受体延伸过程,进行cdna合成和3
’‑
衔接子添加。完全衔接子cdna和条形码二聚体通过pcr扩增和样品标引化。pcr之后,文库被大小选择并纯化,然后通过下一代测序和生物信息学进行序列分析。
94.图12a和12b显示了通过本文所述方法产生的代表性数据。图12a表示去条码化数据;拐点之上到垂直蓝线左侧的条形码是含有细胞的液滴中的珠。所选择的条形码被处理以确定液滴中珠的共定位。经确定在同一液滴中的一个或多个珠被合并且被分配“细胞条形码”。图12b显示了带有检测到的每个细胞的独特转录本(umi)的一个或多个合并珠的细胞条形码;拐点之上至加粗垂直线左侧的条形码被称为并过滤为样品中的细胞。
95.图13显示了从珠浓度和液滴大小计算出的每个液滴的理论预期珠数量。观察到的液滴中的珠数量是由基于ngs数据的与离散液滴共定位的珠条形码数量的去卷积提供。观察到的条形码数量与预期的紧密匹配,但是珠双联体的数量更多,而单体比预期数量少。这些数据证明了使用本文所述的方法和组合物使珠共定位到离散液滴的可行性。
96.图14显示了在珠去卷积且合并映射到人(hg38)或小鼠(mm10)编码序列后,人类k562和小鼠3t3单细胞ngs数据的2d图。每个合并的单细胞数据点的读数量显示在x和y轴上。由k562(hg38)和3t3(mm10)细胞共同定位到离散液滴所定义的串扰计算为1.39%。这表明本文所述的组合物和方法产生单细胞数据,而且珠共定位是精确的,这是由小鼠和人类数据几乎没有到没有无意的合并推断的。
97.图15a显示通过独特的基因umi计数,每个珠条形码的独特基因umi相对于各条形码按等级降序绘制。图15b显示了与mm10对齐的小鼠基因(红色)相比于与hg19对齐的人基因(蓝色)的图。图15c显示了检测到的含有多个条形码的液滴的表格。如果只检测到一个侧接多聚t基序的bc,则液滴大小(dropsize)指定为1;两个bc,dropsize为2,以此类推。频率是指每个液滴大小在文库中出现的次数。在没有珠过载的文库中,由r2逆转座酶多联体共计构建了693个液滴。
98.定义
99.除非另外定义,否则,本文中所使用的所有技术和科学术语都具有本文所属领域普通技术人员通常所理解的含义。通常,本文所用的命名和下述细胞培养、分子遗传学、有机化学和核酸化学以及杂交中的实验室步骤均为本领域熟知和常用的。使用标准技术进行核酸和肽合成。按照本领域和各种通用参考文献所述的常规方法进行这些技术和步骤(通常参见,sambrook等,《分子克隆:实验室手册》(molecular cloning:a laboratory manual),第2版(1989)冷泉港实验室出版社(cold spring harbor laboratory press),纽约冷泉港(cold spring harbor,n.y.),其通过引用纳入本文),将它们引入本文全文中。本
文所用的命名以及下述分析化学和有机合成中的实验室步骤均为本领域熟知且常用。
100.术语“扩增反应”指用于以线性或指数方式倍增核酸靶序列拷贝的各种体外方法。这类方法包括但不限于聚合酶链式反应(pcr);dna连接酶链反应(参见美国专利号4,683,195和4,683,202,pcr protocols:a guide to methods and applications(pcr方案:方法和应用指南)(innis等编,1990))(lcr);基于qbeta rna复制酶和基于rna转录的扩增反应(,例如,涉及t7、t3或sp6引导的rna聚合),例如转录扩增系统(tas),基于核酸序列的扩增(nsaba),和自主维持序列复制(3sr);等温扩增反应(例如,单引物等温扩增(spia));以及本领域技术人员已知的其它方法。
[0101]“扩增”指将溶液置于足以扩增多核苷酸的条件下的步骤(如果反应的所有组分是完整的)。扩增反应的组分包括例如引物、多核苷酸模板、聚合酶、核苷酸等。术语“扩增”通常指靶核酸的“指数型”增长。然而,本文所用的“扩增”也可指核酸的选择靶序列数量的线性增长,如由循环测序或线性扩增所得。示例性实施方式之一中,扩增指采用第一和第二扩增引物的pcr扩增。
[0102]
术语“扩增反应混合物”指包含用于扩增靶核酸的各种试剂的水性溶液。这些试剂包括酶、水性缓冲剂、盐、扩增引物、靶核酸和三磷酸核苷。扩增反应混合物还可包含稳定剂和其它添加剂以优化效率和特异性。根据上下文,混合物可以是完全或是不完全的扩增反应混合物。
[0103]“聚合酶链式反应”或“pcr”是指靶双链dna的特定区段或子序列得以几何级数式扩增的一种方法。pcr是本领域技术人员所熟知的;参见例如,美国专利号4,683,195和4,683,202;和《pcr方案:方法和应用指南》,innis等编,1990。示例性pcr反应条件一般包括两步循环或三步循环。两步循环具有变性步骤和之后的杂交/延伸步骤。三步循环包括变性步骤,之后是杂交步骤,之后是独立的延伸步骤。
[0104]“引物”指与靶核酸上的序列杂交并且用作核酸合成的起始点的多核苷酸序列。引物可以是各种长度的并且通常长度小于50个核苷酸,例如长度为12-30个核苷酸。可基于本领域技术人员已知的原理设计用于pcr的引物的长度和序列,参见例如innis等(同上)。引物可以是dna、rna或dna部分与rna部分的嵌合体。在一些情况中,引物可包括一个或多个带修饰或非天然的核苷碱基。在一些情况中,引物被标记。
[0105]
核酸或其部分与另一核酸“杂交”的某些条件使得生理缓冲液(例如,ph 6-9,25-150mm盐酸盐)中限定温度下的非特异性杂交最少。一些情形中,核酸或其部分与靶核酸组的共有保守序列杂交。在一些情况中,如果包括与超过一个核苷酸伴侣互补的“通用”核苷酸在内有至少约6、8、10、12、14、16或18个连续的互补核苷酸,引物或其部分能杂交至引物结合位点。或者,如果在至少约12、14、16或18个连续的互补核苷酸中有不到1或2个互补错配,引物或其部分能杂交至引物结合位点。一些实施方式中,发生特异性杂交的温度是室温。一些实施方式中,发生特异性杂交的温度高于室温。在一些实施方式中,发生特异性杂交的限定温度至少约37、40、42、45、50、55、60、65、70、75或80℃。在一些实施方式中,发生特异性杂交的限定温度是37、40、42、45、50、55、60、65、70、75或80℃。
[0106]“模板”指包含待扩增的多核苷酸、其侧接或为一对引物杂交位点的多核苷酸序列。因此,“靶模板”包含毗邻引物的至少一个杂交位点的靶多核苷酸序列。在一些情况中,“靶模板”包含侧接有“正向”引物和“反向”引物的杂交位点的靶多核苷酸序列。
[0107]
本文所用的“核酸”表示dna、rna、单链、双链、或更高度聚集的杂交基序及其任意化学修饰。修饰包括但不限于给核酸配体碱基或核酸配体整体提供化学基团的那些修饰,所述化学基团引入附加电荷、极化性、氢键、静电相互作用、连接点和官能团。这类修饰包括但不限于:肽核酸(pna)、磷酸二酯基团修饰(例如,硫代磷酸酯、甲基膦酸酯)、2
′‑
位糖修饰、5-位嘧啶修饰、8-位嘌呤修饰、环外胺修饰、4-硫尿核苷取代、5-溴或5-碘-尿嘧啶取代、骨架修饰、甲基化、稀有碱基配对组合如异碱基(isobase)、异胞苷和异胍(isoguanidine)等。核酸还可以包含非天然碱基,例如硝基吲哚。修饰还可包括3
′
和5
′
修饰,包括但不限于用荧光团(例如,量子点)或其他部分加帽。
[0108]“聚合酶”是指能进行模板引导的多核苷酸(例如,dna和/或rna)合成的酶。该术语同时包括全长多肽和具有聚合酶活性的结构域。dna聚合酶是本领域技术人员熟知的,包括但不限于分离或衍生自激烈火球菌(pyrococcus furiosus)、滨海嗜热球菌(thermococcus litoralis)和海栖热袍菌(thermotoga maritime)的dna聚合酶或其修饰版本。市售可得的聚合酶的其它示例包括但不限于:克列诺(klenow)片段(new england公司)、taq dna聚合酶(凯杰公司(qiagen))、9
°ntm dna聚合酶(new england公司)、deep vent
tm dna聚合酶(new england公司)、manta dna聚合酶(酶学公司)、bst dna聚合酶(new england公司)和dna聚合酶(new england公司)。
[0109]
聚合酶包括dna依赖性聚合酶和rna依赖性聚合酶,如逆转录酶。已知至少5个dna依赖性dna聚合酶家族,虽然大多数落入a、b和c家族。其它类型dna聚合酶包括噬菌体聚合酶。相似地,rna聚合酶通常包括真核rna聚合酶i、ii和iii,和细菌rna聚合酶以及噬菌体和病毒聚合酶。rna聚合酶可以是dna依赖性和rna依赖性的。
[0110]
本文所用术语“分区化”或“经分区化的”指将样品分为多个部分或多个“分区(partition)”。分区通常是物理意义上的,例如,一个分区中的样品不与或基本不与邻近分区中的样品混合。分区可以是固体或流体。在一些实施方式中,分区是固体分区,例如微通道。在一些实施方式中,分区是流体分区,例如,液滴。在一些实施方式中,流体分区(例如,液滴)是不互溶的流体(例如,水和油)的混合物。在一些实施方式中,流体分区(例如,液滴)是水性液滴,其被不互溶的运载体流体(例如,油)包围。
[0111]
如本文所用“条形码”是鉴别其所偶联分子的短核苷酸序列(例如,长至少约4、6、8、10或12个核苷酸)。例如,条形码可用来鉴定分区中的分子。相对于其它分区的条形码,这样的分区特异性条形码应对于该分区是独特的。例如,包含来自单个细胞的靶rna的分区可以经受逆转录条件,在各分区中使用包含不同分区特异性条形码序列的引物,从而将独特“细胞条形码”的拷贝纳入各分区的逆转录所得核酸。由此,来自各细胞的核酸可藉由独特“细胞条形码”而与其它细胞的核酸相区分。在一些情况下,细胞条形码是由存在于偶联至颗粒的寡核苷酸上的“颗粒条形码”提供,其中颗粒条形码由偶联至该颗粒的所有或基本所有寡核苷酸所共有(例如,在它们之间相同或基本相同)。因此,细胞和颗粒条形码可存在于分区中、附接至颗粒或结合至细胞核酸,以同一条形码序列的多个拷贝形式存在。相同序列的细胞或颗粒条形码可鉴定为衍生自相同细胞、分区或颗粒。此类分区特异性的细胞或颗粒条形码可用各种方法产生,这些方法可导致条形码偶联至或纳入固相或水凝胶支持物(例如,固体珠或颗粒或水凝胶珠或颗粒)。一些情况中,使用本文所述的拆分(split)与混合(也称拆分与汇集)合成方案来生成分区特异性细胞或颗粒条形码。分区特异性条形码可
以是细胞条形码和/或颗粒条形码。类似地,细胞条形码可以是分区特异性条形码和/或颗粒条形码。此外,颗粒条形码可以是细胞条形码和/或分区特异性条形码。
[0112]
其它情况中,条形码专一性鉴别其偶联的分子。例如,通过使用各自含有独特“分子条形码”的引物进行逆转录。同样在另一些实施例中,可以利用包含针对各分区独特的“分区特异性条形码”、以及针对各分子独特的“分子条形码”的引物。条码化之后,可以合并分区,并任选地扩增,而保持虚拟分区。因此,例如,可计数包括各条形码的靶核酸(例如,逆转录所得的核酸)的存在与否(例如,通过测序),而无需维持物理分区。
[0113]
条形码序列的长度决定了可以对多少独特的样品进行区分。例如,1个核苷酸的条形码能区分不多于4个不同的样品或分子;4个核苷酸的条形码能区分不多于44即256个样品;6个核苷酸的条形码能区分不多于4096个不同样品;而8个核苷酸的条形码能标引不多于65,536个不同样品。此外,对于第一和第二链合成,条形码可通过都使用条码化引物(通过连接)或在标签化(tagmentation)反应中同时附接至两条链。
[0114]
通常使用固有不精确的过程来合成和/或聚合(例如,扩增)条形码。因此,旨在均一的条形码(例如,单个分区、细胞或珠的全部条码化核酸所共有的细胞、颗粒或分区特异性条形码)可以相对于范本条形码序列包含不同的n-1缺失或其它突变。因此,被称作“相同的”或“基本相同的”拷贝的条形码是指由于例如合成、聚合或纯化错误中一个或多个错误而导致条形码相对范本条形码序列含有不同的n-1缺失或其它突变的不同的条形码。此外,在使用例如本文所述的拆分与汇集方法和/或核苷酸前体分子等同混合物的合成过程中,条形码核苷酸的随机偶联可能导致低概率事件,其中条形码并非绝对独特(例如,不同于群体的其它条形码,或不同于不同分区、细胞或珠的条形码)。但是,这类偏离理论上理想的条形码的轻微偏差不会干扰本文所述的高通量测序分析方法、组合物和试剂盒。因此,如本文所用,术语“独特”在涉及颗粒、细胞、分区特异性或分子条形码的内容中涵盖偏离理想条形码序列的各种非有意的n-1缺失和突变。一些情况中,由于条形码合成、聚合和/或扩增所致的不精确性质造成的问题通过对与待区分的条形码序列的数量相比进行可能的条形码序列的过量采样(oversampling)来克服(例如,至少约2、5、10倍或更多倍的可能的条形码序列)。例如,可用具有9个条形码核苷酸的细胞条形码(代表262,144个可能的条形码序列)来分析10,000个细胞。本领域熟知条形码技术的使用,参见例如katsuyuki shiroguchi等人proc natl acad sci u s a.,2012年1月24日109(4):1347-52和smith,am等人的nucleic acids research can 11,(2010)。使用条形码技术的其他方法和组合物包括u.s.2016/0060621中描述的那些。
[0115]“转座酶”或“标签化酶”是指这样的酶,所述酶能够与含转座子末端的组合物形成功能性复合物并催化含转座子末端的组合物插入或转移到与该组合物在体外转座反应中孵育的双链靶dna中。
[0116]
术语“转座子末端”是指双链dna,其仅显示与在体外转座反应中起作用的转座酶形成复合物所必需的核苷酸序列(“转座子末端序列”)。转座子末端形成“复合物”或“突触复合物”或“转座体复合物”或“具有转座酶或整合酶的转座体组合物,其识别并结合至转座子末端,并且该复合物能够将转座子末端插入或转座到与该复合物在体外转座反应中孵育的靶dna中。转座子末端显示两个互补序列,其由“转移的转座子末端序列”或“转移的链”和“非转移的转座子末端序列”或“非转移的链”组成。例如,一个转座子末端与过度活跃的在
体外转座反应中有活性的tn5转座酶(例如,ez-tn5
tm
转座酶,epicentre生物技术公司(epicentre biotechnologies),美国威斯康星州麦迪逊)形成复合物,其包含表现出如下“转移的转座子末端序列”的转移链:
[0117]5′
agatgtgtataagagacag 3
′
(seq id no:1),
[0118]
以及显示如下“非转移的转座子末端序列”的非转移的链:
[0119]5′
ctgtctcttatacacatct 3
′
(seq id no:2)。
[0120]
转移链的3
′‑
末端在体外转座反应中接合或转移至靶dna。表现出与转移的转座子末端序列互补的转座子末端序列的非转移链在体外转座反应中不接合或转移至靶dna。
[0121]
在一些实施方式中,转移的链和非转移的链共价接合。例如,在一些实施方式中,转移的和非转移的链序列在单个寡核苷酸上提供,例如以发夹构型提供。因此,尽管非转移的链的游离端不通过转座反应直接接合至靶dna,但非转移的链间接地附连至dna片段,因为非转移的链通过发夹结构的环连接至转移的链。
[0122]
术语“固体支持物”指的是用于附接核酸(例如寡核苷酸或多核苷酸)的珠、微量滴定孔的表面或其他表面。固体支持物的表面可以被处理以促进核酸(例如单链核酸)的附接。
[0123]
术语“珠”指可以存在于分区中的任何固体支持物,例如,小颗粒或其他固体支持物。在一些实施方式中,珠包含聚丙烯酰胺。例如,在一些实施方式中,通过附接至各寡核苷酸的丙烯酰胺(acrydite)化学修饰,珠将条形码寡核苷酸纳入凝胶基质。示例性珠可包含水凝胶珠。一些情况中,水凝胶是溶胶(sol)形式。一些情况中,水凝胶是凝胶(gel)形式。示例性水凝胶是琼脂糖水凝胶。其它水凝胶包括但不限于例如下列文件中所述:美国专利号4,438,258;6,534,083;8,008,476;8,329,763;美国专利申请号2002/0,009,591;2013/0,022,569;2013/0,034,592;以及国际专利申请号wo/1997/030092和wo/2001/049240。
[0124]
术语“捕获序列”是指与另一序列(如检测序列或样品靶序列)的3
′
序列,或其反向互补物,互补的核酸序列。
[0125]
术语“检测序列”是指在寡核苷酸的3’端与捕获序列互补的序列。检测序列与其他独特的连接检测序列的序列以共价或非共价的方式关联。其他独特的序列可以包括分子条形码、核苷酸序列条形码和/或核苷酸长度条形码。包含检测序列的核酸可以具有可裂解部分。
[0126]
可以理解的是,本文公开的任何数值范围都可以包含范围的端点,以及端点之间的任何数值或子范围。例如,1到10的范围包含端点1和10,以及1和10之间的任何数值。这些值通常包含一位有效数字。
[0127]
术语“样品”是指包含靶核酸的生物组合物,例如细胞。
[0128]
术语“去卷积”是指当它们来自同一分区或原始占据同一分区时,分配2个条形码和它们所附接的珠。去卷积可以通过在测序过程中检测单个核酸片段上的两个条形码来确定。
[0129]
术语“约”是指本领域普通技术人员对于本技术领域的各个值的通常误差范围,例如
±
10%、
±
5%或
±
1%的范围,其可以包含引用的值,即使引用的值没有被术语“大约”修饰。
[0130]
本文所述的所有范围可包含该范围的端点值,以及包含在该范围的端点之间的值
的任何子范围,其中所述值包含第一位有效数字。例如,1至10的范围包含2至9、3至8、4至7、5至6、1至5、2至5、2至10、3至10等范围。
具体实施方式
[0131]
分区(例如液滴)中条形码珠过载增加液滴的利用,使得>90%的液滴包含至少一个固体支持物(例如珠)且在条码化期间有活性。然而,当分区具有超过一个固体支持物时,为了防止底物(即细胞)数据的分离(fractionation),和/或底物(即细胞)的过度表现,固体支持物需要被共定位到单个分区。发生这种情况时,每个共定位的条形码的数据可以在计算机中合并以保持数据完整性。
[0132]
与每个分区超过一个条码化珠相关的问题可以通过本文所述的方法和组合物解决。例如,通过分子生物学序列分析将那些条形码共定位并归于它们的原始共有分区,可以确保数据完整性,因此,可以将珠过载到分区中作为最大化分区的条码化转化率的方法。本公开提供了组合物、方法、合成的序列结构和序列分析,其可用于将条形码共定位至发生条码化的它们共享的分区。
[0133]
具体地,在单个线性dna段中测序条形码序列能够推断这些寡核苷酸所源自的珠在条码化反应期间位于同一分区中。条形码寡核苷酸共定位后,归属于各条形码的数据可在计算机中合并,以创建统一的分区水平条形码和定为原始包含在分区内(即来自单个细胞)的底物的完整数据集。
[0134]
条形码-条形码线性序列结构的形成可以通过多种方法实现,其中一些方法依赖于引物模板或不依赖于引物模板,使用rna依赖性聚合酶(例如逆转录酶)、dna依赖性聚合酶、连接酶(rna、dna、单或双链)或r2逆转座子。条形码寡核苷酸的物理关联通常发生在分区中。通过物理结合(例如杂交)模板的合成或通过直接连接的酶学共价连接序列可以发生在分区或液滴的内部或外部。条形码寡核苷酸的关联可以通过特定序列(例如回文)促进。
[0135]
本文所述的是可以附接至固体支持物的寡核苷酸。在一些实施方式中,寡核苷酸包含对于固体支持物独特的条形码序列(成为固体支持物寡核苷酸)。在一些实施方式中,包含不同条形码序列的两种不同的固体支持物寡核苷酸被接合或连接在一起,以创建包含两种不同条形码序列的嵌合寡核苷酸。包含不同条形码序列的两种不同寡核苷酸可被附接至同一分区中的不同固体支持物。从固体支持物上裂解寡核苷酸后,不同的寡核苷酸被共价连接以创建包含两种不同的条形码序列的嵌合寡核苷酸。
[0136]
然后对嵌合寡核苷酸进行测序和去条码化,在单个线性dna段中产生条形码序列的关联,这表明在条码化反应期间,寡核苷酸来源的固体支持物定位于同一分区中。条形码寡核苷酸共定位后,归属于各条形码的数据可在计算机中合并,以创建统一的分区水平条形码和定为最初包含在分区内(即源自单个细胞)的底物的完整数据集。
[0137]
条形码寡核苷酸嵌合体的形成可以通过多种方法实现,包括依赖于引物模板或不依赖于引物模板的方法,例如rna依赖性聚合酶(例如逆转录酶)、dna依赖性聚合酶、连接酶(rna、dna、单或双链)或r2逆转座子。在一些实施方式中,条形码寡核苷酸的物理关联在分区内进行。在一些实施方式中,通过物理结合(例如杂交)模板或通过直接连接合成的共价连接序列的反应可以发生在分区或液滴的内部或外部。条形码寡核苷酸的关联可以通过特定序列(例如回文)促进。
[0138]
本发明人意外地发现不依赖模板的酶促反应(例如r2逆转座子和逆转录酶)可以产生包含原始附接至分区中不同固体支持物的两个不同条形码的嵌合寡核苷酸。
[0139]
方法
[0140]
本文描述了用于检测分区中多个条码化固体支持物存在的方法。该方法包括提供多个分区,其中至少部分分区包含多个固体支持物。分区可以是乳液中的液滴。在一些实施方式中,与分区中的其他固体支持物相比,每个固体支持物连接或附接至不同的寡核苷酸(固体支持物寡核苷酸)。在一些实施方式中,固体支持物寡核苷酸包含对于固体支持物独特的条形码。例如,寡核苷酸可包含对其连接的特定固体支持物具有特异性的条形码。在一些实施方式中,第一固体支持物附接至包含对第一固体支持物独特的第一条形码的第一固体支持物寡核苷酸,第二固体支持物附接至包含对第二固体支持物独特的第二条形码的第二固体支持物寡核苷酸。应理解,固体支持物可被附接至相同固体支持物寡核苷酸的多个拷贝,例如,相同或基本相同的固体支持物寡核苷酸的至少约10、50、100、500、1000、5000、10,000、50,000、100,000、500,000、1,000,000、5,000,000、10,000,000、108、109、10
10
个或更多个拷贝可以被附接至一个(例如同一个)固体支持物。
[0141]
在一些实施方式中,条形码是约4-约250核苷酸的序列,例如,约6-25、约10-24、约8-20、约8-18、约10-20、约10-18或约12-20个核苷酸。在一些实施方式中,条形码是至少4、6、8、10或12个核苷酸的序列。在一些实施方式中,偶联至特定固体表面(例如珠)的寡核苷酸包含在固体表面上多个寡核苷酸中相同或基本相同的条形码序列,但与附接至其他固体表面的多个寡核苷酸相比是独特或基本独特的。在一些实施方式中,条形码可破裂成两个或更多个非连续序列。
[0142]
在一些实施方式中,方法包括合成寡核苷酸的互补序列以产生具有来自两种固体支持物寡核苷酸的条形码的双链多核苷酸。因此,双链多核苷酸可包含两个不同条形码,来自第一固体支持物寡核苷酸的第一条形码,和来自第二固体支持物寡核苷酸的第二条形码。
[0143]
在一些实施方式中,合成寡核苷酸的互补序列以产生双链多核苷酸的步骤发生在分区内(即在分区内容物被释放之前)。在一些实施方式中,合成寡核苷酸的互补序列以产生双链多核苷酸的步骤发生在分区之外(即在分区内容物被释放之后)。在一些情况下,多个分区的内容物被组合,再进行下游步骤,例如测序双链多核苷酸的链。
[0144]
在一些实施方式中,方法包括测序双链多核苷酸的一条或两条链。包含两种不同条形码的序列(sequences)的存在表明,附接至不同固体支持物寡核苷酸的两个固体支持物存在于同一分区中。
[0145]
在一些实施方式中,例如当寡核苷酸在分区内时,从固体支持物裂解包含条形码的固体支持物寡核苷酸。在一些实施方式中,固体支持物寡核苷酸通过可裂解接头(如下所述)连接至固体支持物,并且可以从分区中的珠或固体支持物裂解。
[0146]
在一些情况下,固体支持物寡核苷酸通过二硫键(例如,通过固体支持物的硫化物与共价附接至5’或3’末端,或寡核苷酸的插入核酸的硫化物之间的二硫键)附接至固体支持物。这类情况中,可通过使固体支持物接触还原剂来裂解所述寡核苷酸,所述还原剂例如硫醇或膦试剂,包括但不限于β-巯基乙醇、二硫苏糖醇(dtt)或三(2-羧基乙基)膦(tcep)。在一些实施方式中,可裂解接头是由限制性酶(例如,内切核酸酶,诸如ii型内切核酸酶或
iis型内切核酸酶)裂解的限制性酶位点。例如,在一些实施方式中,可裂解接头包括ii型限制性酶结合位点(例如,hhai、hindiii、noti、bbvci、ecori、bgli)或iis型限制性酶结合位点(例如,foki、alwi、bspmi、mnii、bbvi、bcci、mboi)。在一些实施方式中,可裂解接头在部分核苷酸序列中包含尿苷纳入位点。尿苷纳入位点可以被裂解,例如,使用尿嘧啶糖基化酶(例如,尿苷n-糖基化酶或尿苷dna糖基化(udg)酶)。在一些实施方式中,可裂解接头包括光可裂解核苷酸。光可裂解核苷酸包括例如光可裂解荧光核苷酸和光可裂解生物素化核苷酸。参见例如,li等,pnas,2003,100:414-419;luo等,methods enzymol,2014,549:115-131。
[0147]
在一些实施方式中,互补序列是使用不依赖模板的机制合成的。例如,在一些实施方式中,互补序列是使用r2逆转座子(r2逆转座酶)合成的。在一些实施方式中,互补序列是使用逆转录酶合成的。合适的逆转录酶包括superscript ii(生命技术公司(life tech))、superscript iii(生命技术公司)、superscript iv(生命技术公司)、maxima rna酶+(赛默飞世尔科技公司(thermo))、maxima rna酶-(赛默飞世尔科技公司)和sensiscript(凯杰公司)。通常,逆转录酶通常包括真核rna聚合酶i、ii和iii,和细菌rna聚合酶以及噬菌体和病毒聚合酶。rna聚合酶可以是dna依赖性和rna依赖性的。rna聚合酶可以具有rna酶h+活性和rna酶h-活性。
[0148]
在一些实施方式中,方法还包括将双链衔接子添加至双链多核苷酸。可以通过将双链多核苷酸与载有衔接子的转座酶或标签化酶接触以添加双链衔接子。载有衔接子的标签化酶在本文中和us 2018/0195112(对应于wo 2018/118971)中描述。
[0149]
图1说明不依赖模板的合成的一个实施方式。两个不同的珠显示于同一分区中,每个珠被附接至包含通用标签序列、条形码(bc)和多聚dt序列的寡核苷酸。附接至珠1的寡核苷酸包含bc1,附接至珠2的寡核苷酸包含不同的条形码bc2。寡核苷酸被从珠上裂解,r2逆转座子(在分区内作为反应混合物的部分存在)从寡核苷酸的3’末端起始合成,并产生双链dna分子混合物。如下方的分区中所示,混合物中的一些双链分子包含两个条形码bc1和bc2(见分区底部说明的分子)。然后破乳,释放分区的内容物,并通过连接添加测序衔接子。通用tag序列可用于下游pcr或测序期间。基于连接的文库制备在下方右侧灰色方框中显示。在单个序列读数中存在包含两个条形码的嵌合序列表明在条码化期间两种不同的条形码珠存在于同一分区中。
[0150]
图2说明了不依赖模板的合成的另一个实施方式。该步骤和图1中所示的步骤相同,但是在破乳后,转座酶用于为文库制备添加衔接子。三角形表示转座酶/标签化酶,黑色实心条表示衔接子。
[0151]
图3说明了不依赖模板的合成的另一个实施方式。这些步骤与图2相似,但是不依赖模板的条形码合成是作为由逆转录酶生成嵌合珠寡核苷酸序列的第二反应发生的。如上所述,分区中的一些双链分子包含两个条形码bc1和bc2(见分区底部说明的分子)。在单个序列读数中存在包含两种条形码的嵌合序列表明在条码化期间两种不同的条形码珠存在于同一分区中。
[0152]
图4显示了从嵌合珠寡核苷酸序列的逆转录酶合成产生的序列的代表性实施例,如图3所示。珠寡核苷酸条形码是由条形码(bc)1、bc2和bc3的组合生成。在读数1和读数2中分别发现了两种不同的珠条形码寡核苷酸序列。来自illumina流动池中相同读数或簇的信
息在条形码反应期间将条形码序列下方的相关珠共定位到同一分区。
[0153]
图5说明了不依赖于模板合成的另一个实施方式,使用连接附接被裂解的寡核苷酸。如上所述,在分区化期间,多于一个条形码珠被封装在单个分区内。寡核苷酸被裂解,使得它们不再与珠物理关联。如图所示,单链dna连接酶随机地连接条形码珠寡核苷酸。然后破乳,并使用p7加尾多聚a引物将嵌合分子或多联体转化为分区外的双链分子。制备双链分子用于测序,例如,通过融合pcr,以添加p5和p7标签。制备用于测序的双链分子的其他方法是本领域已知的。例如,在一个替代性实施方式中,2d逆转座子被用于在单个步骤中添加衔接子分子(显示在右侧)。
[0154]
图6说明了在分区中依赖于模板的嵌合寡核苷酸生成的实施方式。在该实施方式中,珠寡核苷酸序列具有回文3’末端。如上所述,寡核苷酸在分区中裂解,其中一部分互相杂交。逆转录用来合成反向互补物。在该实施方式中,通过连接和融合pcr添加测序衔接子以制备用于测序的文库。
[0155]
将小鼠nih3t3和人hek细胞系按1∶1的比例混合,通过单细胞rna seq工作流程进行处理。它们被装载,从而预期有10k个细胞被处理。
[0156]
封装后,用标准的非离子型去污剂裂解细胞,用基于mmlv的逆转录酶逆转录mrna。通过珠条形码寡聚dt引物模板反应驱动逆转录。在液滴中cdna被转化成双链cdna。使液滴破裂,合并内容物,产物使用ampure珠纯化。
[0157]
双链产生之后,在反应中应用标签化酶给ds-cdna加标签。在标签化反应期间,使用同源衔接的tn5标签化酶。然后,通过使用对珠寡核苷酸通用tag序列(存在于寡核苷酸的5
′
末端和tn5衔接子的非嵌合端部分)具有特异性的引物,即分别使用p5和n70x引物,使标签化的ds cdna经历珠衔接的文库3
′
末端的pcr富集。由于pcr抑制作用,被tn5衔接子衔接的插入物只能以相对较差的效率扩增。产物用ampure珠纯化,并在bioanalyzer凝胶上跑样。产物的踪迹如图所示。
[0158]
在另一方面,这些方法使用通过含有尿嘧啶碱基和生物素-偶联碱基的接头附接固体支持物寡核苷酸来官能化的固体支持物。该接头可定位于检测寡核苷酸的5’末端。在一些实施方式中,寡核苷酸包含对于固体支持物独特的条形码。在一些实施方式中,寡核苷酸还包含测序衔接子。在一些实施方式中,寡核苷酸还包含3’末端的“捕获序列”。在一些实施方式中,捕获序列为3’多聚dt序列。在一些实施方式中,捕获序列是随机序列。在一些实施方式中,捕获序列是基因特异性序列。代表性示例如图8所示。
[0159]
珠可以通过将模板(有时称为“伪模板(dummy template)”或“检测寡核苷酸”)杂交至固体支持寡核苷酸来制备,其中伪模板具有与捕获序列互补的3’末端。例如,在一些实施方式中,伪模板包含可以杂交至固体支持寡核苷酸的多聚dt捕获序列的3’多聚a尾。伪模板可以在5’末端包含回文序列。在一些实施方式中,回文序列长度为4-250个寡核苷酸,例如,长度为4-80、10-20、10-30、10-40、20-30或20-40个寡核苷酸。应理解,回文序列包含第一5’区域和第二3’区域,其中至少部分3’区域包含5’区域的反向互补序列,使得第一区域可以是,例如,10到20个寡核苷酸,第二区域可以是10到20个寡核苷酸。在一些实施方式中,固体支持物寡核苷酸比检测寡核苷酸的比率为至少5∶1至100000∶1,例如5∶1、10∶1、100∶1、1000∶1、5000∶1、10000∶1、20000∶1;30000∶1.40000∶1、50000∶1;60000∶1、70000∶1;80000∶1、90000∶1或100000∶1。在一些实施方式中,杂交发生在分区内。
[0160]
杂交可以在dna聚合酶存在下发生。“聚合酶”是指能进行模板引导的多核苷酸(例如,dna和/或rna)合成的酶。该术语同时包括全长多肽和具有聚合酶活性的结构域。dna聚合酶是本领域技术人员熟知的,包括但不限于分离或衍生自激烈火球菌(pyrococcus furiosus)、滨海嗜热球菌(thermococcus litoralis)和海栖热袍菌(thermotoga maritime)的dna聚合酶或其修饰版本。在一些实施方式中,dna聚合酶不包括核酸外切酶活性以防止引物降解。合适的聚合酶的实例包括克列诺(klenow)片段(new england公司)、taq dna聚合酶(凯杰公司(qiagen))、9
°ntm dna聚合酶(new england公司)、deep vent
tm dna聚合酶(new england公司)、manta dna聚合酶(酶学公司)、bst dna聚合酶(new england公司)和dna聚合酶(new england公司)。聚合酶包括dna依赖性聚合酶和rna依赖性聚合酶,如逆转录酶。已知至少5个dna依赖性dna聚合酶家族,虽然大多数落入a、b和c家族。其它类型dna聚合酶包括噬菌体聚合酶。相似地,rna聚合酶通常包括真核rna聚合酶i、ii和iii,和细菌rna聚合酶以及噬菌体和病毒聚合酶。rna聚合酶可以是dna依赖性和rna依赖性的。dna聚合酶延伸固体支持物寡核苷酸,以产生包含检测寡核苷酸的互补物的延伸的固体支持物寡核苷酸。在一些实施方式中,延伸的检测固体支持物寡核苷酸包含互补于回文序列的3’末端。
[0161]
在一些实施方式中,分区含有用于聚合酶延伸的试剂,例如dntp和引物以及udg酶。udg酶是用于从固体支持物裂解含有尿嘧啶碱基接头的固体支持物寡核苷酸(见图9)。因此,在一些实施方式中,该方法包含将固体支持物寡核苷酸与udg酶接触,从而从固体支持物裂解固体支持物寡核苷酸。在一些实施方式中,从固体支持物裂解固体支持物寡核苷酸在分区内进行。
[0162]
在一些实施方式中,该方法还包括杂交延长的固体支持物寡核苷酸的3’末端,并用聚合酶延伸延长的检测固体支持物寡核苷酸的3’末端,从而形成具有来自两种固体支持物寡核苷酸的条形码的双链多核苷酸(见10a)。
[0163]
在一些实施方式中,分区包含生物样品。在一些实施方式中,样品包括细胞,例如单细胞,而该方法进一步包括裂解细胞以释放样品核酸,例如rna。在一些实施方式中,在扩增反应期间细胞和核酸被裂解,例如rna被片段化。由于扩增反应混合物中温度升高和mg
++
的存在,可以发生rna片段化(见图9)。
[0164]
在一些实施方式中,方法包括捕获样品核酸。在一些实施方式中,至少一些固体支持物寡核苷酸捕获序列杂交至样品核酸,并且由聚合酶延伸以产生包含样品核酸的互补物的延长的样品固体支持物寡核苷酸。在一些实施方式中,样品核酸是mrna,通过将mrna的多聚a尾杂交至固体支持寡核苷酸上的寡聚dt序列来捕获mrna。在一些实施方式中,产生延伸样品固体支持物寡核苷酸的反应发生于分区内。
[0165]
在一些方面,描述了一种用于产生用于测序的核酸分子文库的方法。在一些实施方式中,该方法步骤在分区内进行。该方法可以包括提供多个分区,其中至少一些分区包括单个细胞和多个固体支持物,其中不同的固体支持物被连接至同一分区中的第一和第二固体支持物寡核苷酸。在一些实施方式中,第一固体支持物寡核苷酸包含对于固体支持物独特的条形码、捕获序列和测序衔接子,第二固体支持物寡核苷酸包含3’末端的回文序列、测序衔接子和对于固体支持物独特的条形码。在一些实施方式中,捕获序列包含多聚dt、随机序列或基因特异性序列。
[0166]
在一些实施方式中,寡核苷酸从固体支持物释放或裂解,来自生物样品的rna分子杂交至一个或多个第一寡核苷酸的捕获序列,形成rna/寡核苷酸杂交体,而包含回文序列的第二固体支持物寡核苷酸互相杂交。
[0167]
然后,可以使用聚合酶延伸杂交的第二固体支持物寡核苷酸以产生包含第一和第二条形码的双链dna二聚体分子,其中第一和第二条形码来自同一分区中的相同或不同固体支持物寡核苷酸。延伸后,双链dna二聚体分子可以被扩增,例如,通过pcr,使用退火至测序衔接子的引物。在一些实施方式中,扩增步骤包含解链双链dna分子并将引物杂交至测序衔接子,使用聚合酶延伸引物,并通过pcr扩增延伸的分子。
[0168]
在一些实施方式中,引物混合物(例如r1和r2)被用于扩增双链dna二聚体分子。r1和r2测序衔接子引物具有共同的3’末端,因此具有平等的机会退火至测序衔接子的互补区域。参见图10b。用引物混合物扩增产生4中不同产物的文库:r1/r1、r1/r2、r2/r1和r2/r2。测序pcr产物r1/r2和r2/r1产生来自两条链的序列读数。
[0169]
该方法还可以延伸结合至rna/第一寡核苷酸杂交体的rna以产生edna。使用r2逆转座酶进行该rna的逆转录以合成edna。受体分子被添加到反应中,以作为模板用于将3’衔接子添加到edna。然后,可以扩增包含3’衔接子的cdna,例如,通过pcr。在一些实施方式中,rna/第一寡核苷酸杂交体和含有杂交的第二固体支持物寡核苷酸的双链dna二聚体分子在分区外扩增。见图11。
[0170]
在一些实施方式中,文库中的核酸分子被测序,例如,使用下一代测序技术。包含相同条形码的多个序列表示这些固体支持物存在于同一分区。
[0171]
在另一方面,描述了一种检测分区中多个条码化固体支持物存在的方法,该方法包括:a)提供了多个分区,其中至少部分分区包含多个固体支持物,其中每个固体支持物被连接至(i)多个第一固体支持物寡核苷酸,其包含对于固体支持物独特的条形码序列,和捕获序列;(ii)一个或多个第二寡核苷酸,其具有包含互补于捕获序列的序列的3’末端、条形码序列和5’回文序列;其中第一固体支持物寡核苷酸与第二寡核苷酸的比率为至少至少5∶1、10∶1、100∶1、1000∶1、5000∶1、10000∶1、20000∶1;30000∶1.40000∶1、50000∶1;60000∶1、70000∶1;80000∶1、90000∶1或100000∶1;
[0172]
b)从固体支持物释放第一和第二寡核苷酸;
[0173]
c)在第一聚合酶存在的情况下,一些固体支持物寡核苷酸的捕获序列杂交至第二寡核苷酸的3’末端,以产生延长的固体支持物寡核苷酸,其包含第二寡核苷酸的互补物,其中所述延长的固体支持物寡核苷酸包含互补于回文序列的3’末端;和
[0174]
d)杂交延长的固体支持物寡核苷酸的3’末端,并用第二聚合酶延伸该3’末端,从而形成具有来自两种固体支持物寡核苷酸的条形码的双链多核苷酸。
[0175]
和
[0176]
e)测序双链多核苷酸的一条或两条链,其中包含两种不同的条形码的序列表示两个固体支持物存在于同一分区中。
[0177]
在一些实施方式中,互补于捕获序列的序列包含3’终止子或在3’末端被封闭,以防止被聚合酶延伸。
[0178]
在一些实施方式中,步骤(c)中的第一聚合酶不具有核酸外切酶活性。在一些实施方式中,该聚合酶是therminator
tm dna聚合酶或taq dna聚合酶。
[0179]
在一些实施方式中,第一寡核苷酸进一步包括以下一种或多种:a)尿嘧啶碱基;b)生物素碱基;或d)用于测序反应的衔接子序列。
[0180]
在本文所述的任何实施方式中,分区可以是微孔或乳液中的液滴。
[0181]
在一些实施方式中,生物样品包括单细胞,细胞被裂解以释放rna。在一些实施方式中,rna被片段化以产生rna片段。rna可以被片段化,例如通过在二价离子存在的情况下被加热,这些条件在扩增反应中存在。
[0182]
在一些实施方式中,分区包含dna聚合酶、二价离子、测序衔接子、三磷酸脱氧核苷酸(dntp)和具有至少3’序列互补于测序衔接子的引物。在一些实施方式中,分区进一步包含多聚(a)聚合酶和atp,并且多聚-a尾被添加到rna片段上。
[0183]
在一些实施方式中,第一和/或第二寡核苷酸包含尿嘧啶碱基,通过将寡核苷酸与udg酶或user酶接触,从固体支持物释放寡核苷酸。
[0184]
在一些方面,本文所述的方法可用于捕获mrna分子、微小rna或总rna的3’末端来分析。在一些实施方式中,该方法在分区中(例如乳液液滴)发生。在一些实施方式中,该方法在微孔分区中发生。在一些实施方式中,该方法可以与本文所述的条码化固体支持物一起使用。
[0185]
例如,在一个实施方式中,该方法允许捕获mrna的3’末端。在一些实施方式中,该方法包括释放与来自固体支持物或珠的条形码寡核苷酸杂交的mrna。在一些实施方式中,该方法包括条形码寡核苷酸的酶促裂解,从而从固体支持物或珠释放杂交的mrna。在一些实施方式中,该方法包括通过udg酶或user酶在条形码寡核苷酸中酶促裂解尿嘧啶碱基。在一些实施方式中,在杂交至捕获条形码寡核苷酸之前或之后,或杂交体分子被从固体支持物释放之后,mrna被片段化。在一些实施方式中,在二价离子存在的情况下通过加热将rna片段化。在一些实施方式中,杂交的rna用作产生cdna的模板,例如,通过使用逆转录酶、带有模板转换活性的逆转录酶或r2逆转座酶。然后,测序衔接子可如本文所述被添加上去。然后,cdna可被用作模板以产生含有条形码的双链dna。双链的、条码化的dna可如本文所述被测序。
[0186]
在另一个实施方式中,该方法可用以从细胞中捕获微小rna(mirna)。微小rna是小型非编码rna分子(长度为约22个氨基酸),其在rna沉默和基因表达的转录后调控中发挥作用。mirna通常不含3’多聚腺嘌呤(多聚(a))尾。因此,在一些实施方式中,该方法包括将从具有多聚(a)聚合酶(多核苷酸腺苷酰基转移酶)的细胞中分离的rna与atp接触,以在mirna的3’羟基端添加多聚(a)尾。添加3’多聚(a)尾之后,该方法可如上进行以捕获和测序mirna。
[0187]
在另一个实施方式中,该方法可用以捕获总rna。总rna包括不具有多聚(a)尾的rna,例如转移rna(trna)。在一些实施方式中,该方法包括在适合引物与单链rna杂交的条件下,在随机引物存在的情况下,用rna酶(例如rna酶h)将rna片段化。随机引物是不可由酶延伸的,例如聚合酶、转录酶或逆转座酶。引物在随机位置杂交至rna以创建rna∶dna异源双链体的短区域。然后rna与rna酶h接触,在双链rna的短区域裂解rna,从而创建可延伸的3’端。然后可以用多聚(a)聚合酶和atp延伸片段化的rna的3’末端,以添加3’多聚(a)尾。在一些实施方式中,随机引物包含可被rna酶h裂解的延伸封闭物(extension blocker),例如防止由dna聚合酶延伸的丙二醇。添加3’多聚(a)尾之后,该方法可如上所述进行以制备双链
的、条码化的dna用于测序反应。
[0188]
a.纯化
[0189]
在一些实施方式中,随后破乳,释放分区的内容物。在一些实施方式中,合并分区的内容物。在一些实施方式中,释放的固体支持物寡核苷酸(包括延长的样品固体支持物寡核苷酸)被纯化。在一些实施方式中,释放的固体支持物寡核苷酸通过亲和色谱法纯化。在一些实施方式中,释放的固体支持物寡核苷酸包含结合对的一个或第一个成员,并通过结合至结合对的另一个或第二个成员而被纯化。合适的结合对的实例包括配体和受体、抗体和同源抗原,以及生物素-链霉亲和素。例如,释放的固体支持物寡核苷酸(包括延长的样品固体支持物寡核苷酸)可包含生物素,固体支持物寡核苷酸通过结合至链霉亲和素被纯化。在一些实施方式中,固体支持物寡核苷酸通过结合至含有(或连接至)链霉亲和素的固体支持物被纯化。未结合的组分通过洗涤被除去。在一些实施方式中,固体支持物是磁性的,结合的固体支持物寡核苷酸使用磁场纯化,以从未结合的组分中分离结合的固体支持物寡核苷酸。
[0190]
在一些实施方式中,固体支持物寡核苷酸与修饰的转座酶接触,例如(2d基因组学(2d genomics)),具有非常高的加工能力、链置换能力和内置的逆转录酶活性,从而高转化效率地将捕获的rna转化为测序文库。然后可以测序双链多核苷酸的链。如果序列包含两种不同条形码,这表明两种不同的固体支持物存在于相同分区中。
[0191]
在一些实施方式中,结合的固体支持物寡核苷酸被从固体支持物中去除,例如,通过洗脱。寡核苷酸从珠上的洗脱可能涉及到对光可裂解的寡核苷酸基序的光裂解,对将寡核苷酸连接到磁珠上的蛋白复合物的蛋白酶k sds处理,和/或对将寡核苷酸连接到磁珠上的蛋白复合物使用离液剂(如硫氰酸胍)变性。
[0192]
b.标签化酶
[0193]
可以如本文所述使用载有异源衔接子的标签化酶和载有同源衔接子的标签化酶。载有同源衔接子的标签化酶是包含只有一个序列的衔接子的标签化酶,其中衔接子被添加至基因组dna中标签化酶诱导的断裂点的末端之一。载有异源衔接子的标签化酶是包含两种不同的衔接子的标签化酶,从而使不同的衔接子序列被添加至dna中标签化酶诱导的断裂点所产生的两个dna末端。载有衔接子的标签化酶进一步描述于例如美国专利公开号:2010/0120098;2012/0301925;和2015/0291942以及美国专利号:5,965,443;美国专利6,437,109;7083980;9005935;和9,238,671,其中各自内容通过引用全文并入本文用于所有目的。
[0194]
标签化酶是指这样的酶,所述酶能够与含转座子末端的组合物形成功能性复合物并催化含转座子末端的组合物插入或转移到与该组合物在体外转座反应中孵育的双链靶dna中。示例性的转座酶包括但不限于相较于野生型tn5过分活跃的修饰的tn5转座酶,例如,可以具有选自e54k、m56a或l372p的一个或多个突变。野生型tn5转座子是复合型转座子,其中2个几乎相同的插入序列(is50l和is50r)侧接3个抗生素抗性基因(reznikoff ws.annu rev genet 42:269-286(2008))。各is50包含2个反向19-bp末端序列(es),外侧端(outside end,oe)和内侧端(inside end,ie)。然而,野生型es的活性相对较低并且被过分活跃的嵌合端(mosaic end,me)序列体外取代。因此,具有19-bp me的转座酶复合物是转座发生所必需的,只要间插dna足够长以使这些序列中的两个靠近在一起形成活性tn5转座酶
同二聚体(reznikoff ws.,mol microbiol 47:1199-1206(2003))。转座在体内是非常罕见的事件,并且过分活跃的突变体历史上源自tn5蛋白的476个残基中导入三个错义突变(e54k、m56a、l372p),其由is50r编码(goryshin iy,reznikoff ws.1998.j biol chem 273:7367-7374(1998))。转座通过“剪切-和-粘贴”机制起作用,其中tn5将其从供体dna中切除并插入靶序列,产生靶标的9-bp重复(schaller h.cold spring harb symp quant biol 43:401-408(1979);reznikoff ws.,annu rev genet 42:269-286(2008))。在当前的商业解决方案(nextera
tm dna试剂盒,亿明达公司(illumina))中,游离的合成me衔接子与靶dna的5
′‑
端通过转座酶(标签化酶)末端连接。在一些实施方式中,标签化酶连接至固体支持物(例如与连接正向引物的珠不同的珠)。商购的珠连接的标签化酶的实例是nextera
tm dna flex(亿明达公司)。
[0195]
在一些实施方式中,一种或多种衔接子的长度为至少19个核苷酸,例如,19-100个核苷酸。在一些实施方式中,衔接子是具有5’端突出端的双链,其中5’突出端序列在异源衔接子间不同,但是双链部分(通常为19bp)是相同的。在一些实施方式中,衔接子包含tcgtcggcagcgtc(seq id no:3)或gtctcgtgggctcgg(seq id no:4)。在涉及载有异源衔接子的标签化酶的一些实施方式中,标签化酶载有包含tcgtcggcagcgtc(seq id no:3)的第一衔接子和包含gtctcgtgggctcgg(seq id no:4)的第二衔接子。在一些实施方式中,衔接子包含agatgtgtataagagacag(seq id no:1)和其互补物(也就是嵌合端,并且这是tn5转座唯一特别需要的顺式活性序列)。在一些实施方式中,衔接子包含
[0196]
tcgtcggcagcgtcagatgtgtataagagacag(seq id no:5)与agatgtgtataagagacag(seq id no:1)的互补物或gtctcgtgggctcggagatgtgtataagagacag(seq id no:6)与agatgtgtataagagacag(seq id no:1)的互补物。在涉及载有异源衔接子的标签化酶的一些实施方式中,标签化酶载有第一衔接子,所述第一衔接子包含tcgtcggcagcgtcagatgtgtataagagacag(seq id no:5)与agatgtgtataagagacag(seq id no:1)的互补物和gtctcgtgggctcggagatgtgtataagagacag(seq id no:6)与agatgtgtataagagacag(seq id no:1)的互补物。
[0197]
在一些实施方式中,衔接子具有19bp双链区域和5’15bp单链突出端。15bp的序列在异源衔接子间不同,然而双链区域具有衔接子(同源或异源衔接子)之间的共有序列。
[0198]
在一些实施方式中,无论衔接子是否加载有异源或同源衔接子,衔接子对可以经由连接核苷酸序列连接。连接序列可以是连接两个衔接子的任何核苷酸序列。在一些实施方式中,连接序列可以为2个核苷酸至5kb长。在一些实施方式中,连接序列可以包含一个或更多个限制性识别序列,从而使连接序列后续可以被添加至分区的限制酶裂解。为了避免dna区段自身内的裂解,选择罕切限制酶(rare cutting restriction enzyme)可能是有益的,例如,具有8个或更多个核苷酸的识别序列的限制酶。
[0199]
在其他实施方式中,连接序列可以包含1个或更多个(,例如,2、3、4、5、6、7、8、9或10)个尿嘧啶。随后,可以在尿嘧啶-dnan-糖基化酶(例如,“ung”)存在的情况下裂解连接序列,所述尿嘧啶-dna n-糖基化酶可以包含在分区中。
[0200]
在其他实施方式中,连接序列可以包含1个或更多个(例如,2、3、4、5、6、7、8、9或10)个核糖核苷酸。随后,可以在碱基或rna酶存在的情况下裂解连接序列,所述碱基或rna酶可以包含在分区中。
[0201]
选择标签化的条件,从而使标签化酶在dna中产生断裂点并使得加载在标签化酶上的衔接子被添加到断裂点的任一端。标签化酶在断裂点的两端引入单链衔接子序列,形成5’突出端。然后通过聚合酶将5
′
突出端填平(“缺口填平”)以在dna区段的任一端生成双链序列。参见例如图9。非转移底链因此是连续的并与转移的顶链(top strand)互补。该连续的底链与聚合酶延伸反应(例如,pcr)相容。因此,“缺口填平”是标签化后的过程,其使得底链(未转移的链)在dna区段末端与顶链连续。缺口填平是指底链的重建。这优选通过dna聚合酶完成,其由位于缺口上游的底部非转移链的3
′
延伸回来。缺口填平的聚合酶可以具有5
′‑3′
外切活性或链置换活性以协助克服非转移的嵌合端。缺口填平或条形码添加都不涉及连接。
[0202]
还选择条件使得标签化酶保持与dna断裂点结合,从而保持相邻性。已经观察到标签化酶保持与dna结合,直到向反应中加入去污剂如sds(amini等nature genetics 46(12):1343-1349)。
[0203]
c.分区
[0204]
任何类型的分区都可用在本文所述的方法中。虽然已经使用液滴例示了该方法,但是应该理解也可以使用其他类型的分区。
[0205]
在一些实施方式中,分区包含连接至第一固体支持物的第一寡核苷酸和连接至第二固体支持物的第二寡核苷酸。
[0206]
用于分区化的方法和组合物描述于例如公开的专利申请wo 2010/036,352,us 2010/0173,394,us 2011/0092,373和us 2011/0092,376中,其全部内容通过引用并入本文。多个混合物分区可以是多个乳液液滴,或多个微孔等。
[0207]
在一些实施方式中,可以将引物和其他试剂分区化到多个混合物分区中,然后可以将连接的dna区段导入多个混合物分区中。用于将试剂递送至一个或多个混合物分区的方法和组合物包括本领域已知的微流体方法;液滴或微胶囊合并,聚结,融合,破裂或降解(例如,如u.s.2015/0027,892;us 2014/0227,684;wo 2012/149,042;和wo 2014/028,537中所述);液滴注入方法(例如,如wo2010/151,776中所述);及其组合。
[0208]
如本文所述,混合物分区可以是皮米孔、纳米孔或微孔。混合物分区可以是皮米、纳米或微米反应室,例如皮米、纳米或微米胶囊。混合物分区可以是皮米、纳米或微米通道。混合物分区可以是液滴,例如乳液液滴。
[0209]
在一些实施方式中,所述分区是液滴。在一些实施方式中,液滴包含乳液组合物,即不互溶的流体(如水和油)的混合物。在一些实施方式中,液滴是水性液滴,其被不互溶的运载体流体(如油)包围。在一些实施方式中,液滴是油性液滴,其被不互溶的运载体流体(如水性溶液)包围。在一些实施方式中,本文所述液滴是相对稳定的并在两个或更多个液滴之间具有最小聚结。在一些实施方式中,由样品生成的液滴中少于0.0001%、0.0005%、0.001%、0.005%、0.01%、0.05%、0.1%、0.5%、1%、2%、3%、4%、5%、6%、7%、8%、9%或10%与其他液滴聚结。这些乳液还可具有有限的絮凝,一种分散相以薄片中悬浮液产生的过程。在一些情况下,这种稳定性或最小聚结可保持长达4、6、8、10、12、24或48小时或更长时间(例如,在室温下,或在约0、2、4、6、8、10或12℃下)。在一些实施方式中,使油相流过水性样品或试剂,从而形成液滴。
[0210]
该油相可包含氟化基础油,其可通过与氟化表面活性剂(如全氟聚醚)联用而进一
步稳定。在一些实施方式中,该基础油包括以下一种或多种:hfe 7500、fc-40、fc-43、fc-70或其他常见氟化油。在一些实施方式中,该油相包含阴离子含氟表面活性剂。在一些实施方式中,该阴离子含氟表面活性剂是ammonium krytox(krytox-as)、krytox fsh的铵盐或krytox fsh的吗啉代衍生物。krytox-as的浓度可以是约0.1%、0.2%、0.3%、0.4%、0.5%、0.6%、0.7%、0.8%、0.9%、1.0%、2.0%、3.0%或4.0%(w/w)。在一些实施方式中,krytox-as的浓度是约1.8%。在一些实施方式中,krytox-as的浓度是约1.62%。krytox fsh的吗啉代衍生物的浓度可以是约0.1%、0.2%、0.3%、0.4%、0.5%、0.6%、0.7%、0.8%、0.9%、1.0%、2.0%、3.0%或4.0%(w/w)。在一些实施方式中,krytox fsh的吗啉代衍生物的浓度是约1.8%。在一些实施方式中,krytox fsh的吗啉代衍生物的浓度是约1.62%。
[0211]
在一些实施方式中,该油相还包含用于调节油性质(如蒸气压、粘度或表面张力)的添加剂。非限制性示例包括全氟辛醇和1h,1h,2h,2h-全氟癸醇。在一些实施方式中,1h,1h,2h,2h-全氟癸醇添加至约0.05%、0.06%、0.07%、0.08%、0.09%、0.1%、0.2%、0.3%、0.4%、0.5%、0.6%、0.7%、0.8%、0.9%、1.0%、1.25%、1.50%、1.75%、2.0%、2.25%、2.5%、2.75%或3.0%(w/w)的浓度。在一些实施方式中,1h,1h,2h,2h-全氟癸醇添加至约0.18%(w/w)的浓度。
[0212]
在一些实施方式中,该乳液配制为生成具有类液界面膜的高度单分散液滴,其可通过加热转化为具有类固界面膜的微胶囊;这类微胶囊可作为生物反应器以通过一段时间的孵育保持其内容物。转化为微胶囊可在一经加热后即发生。例如,这类转化可发生在大于约40
°
、50
°
、60
°
、70
°
、80
°
、90
°
或95℃的温度下。加热过程期间,流体或矿物油覆盖物可用于阻止蒸发。过量的连续相油可在加热前去除或留在原位。这些微胶囊可在大范围的热和机械处理下抗聚结和/或絮凝。
[0213]
在将液滴转化成微胶囊之后,这些微胶囊可储存于约-70℃、-20℃、0℃、3℃、4℃、5℃、6℃、7℃、8℃、9℃、10℃、15℃、20℃、25℃、30℃、35℃或40℃下。在一些实施方式中,这些微胶囊可用于储存或运输分区混合物。例如,可在一个位置处收集样品,分区化到含有酶、缓冲剂和/或引物或其它探针的液滴中,任选地可进行一个或多个聚合反应,然后可加热该分区以进行微囊化,并且可储存或运输微胶囊用于进一步分析。
[0214]
在一些实施方式中,将样品分区化为至少500个分区,1000个分区,2000个分区,3000个分区,4000个分区,5000个分区,6000个分区,7000个分区,8000个分区,10,000个分区,15,000个分区,20,000个分区,30,000个分区,40,000个分区,50,000个分区,60,000个分区,70,000个分区,80,000个分区,90,000个分区,100,000个分区,200,000个分区,300,000个分区,400,000个分区,500,000个分区,600,000个分区,700,000个分区,800,000个分区,900,000个分区,1,000,000个分区,2,000,000个分区,3,000,000个分区,4,000,000个分区,5,000,000个分区,10,000,000个分区,20,000,000个分区,30,000,000个分区,40,000,000个分区,50,000,000个分区,60,000,000个分区,70,000,000个分区,80,000,000个分区,90,000,000个分区,100,000,000个分区,150,000,000个分区或200,000,000个分区。
[0215]
在一些实施方式中,生成的液滴在形状和/或尺寸方面基本均匀。例如,在一些实施方式中,这些液滴在平均直径方面基本均匀。在一些实施方式中,生成的液滴的平均直径为约0.001微米、约0.005微米、约0.01微米、约0.05微米、约0.1微米、约0.5微米、约1微米、
约5微米、约10微米、约20微米、约30微米、约40微米、约50微米、约60微米、约70微米、约80微米、约90微米、约100微米、约150微米、约200微米、约300微米、约400微米、约500微米、约600微米、约700微米、约800微米、约900微米或约1000微米。在一些实施方式中,生成的液滴的平均直径为小于约1000微米、小于约900微米、小于约800微米、小于约700微米、小于约600微米、小于约500微米、小于约400微米、小于约300微米、小于约200微米、小于约100微米、小于约50微米,或小于约25微米。在一些实施方式中,生成的液滴在形状和/或尺寸方面是不均匀的。
[0216]
在一些实施方式中,生成的液滴在体积上基本均匀。例如,液滴体积的标准偏差可以低于约1皮升、5皮升、10皮升、100皮升、1nl或低于约10nl。在一些情况中,液滴体积的标准偏差可低于平均液滴体积的约10-25%。在一些实施方式中,生成的液滴的平均体积为约0.001nl、约0.005nl、约0.01nl、约0.02nl、约0.03nl、约0.04nl、约0.05nl、约0.06nl、约0.07nl、约0.08nl、约0.09nl、约0.1nl、约0.2nl、约0.3nl、约0.4nl、约0.5nl、约0.6nl、约0.7nl、约0.8nl、约0.9nl、约1nl、约1.5nl、约2nl、约2.5nl、约3nl、约3.5nl、约4nl、约4.5nl、约5nl、约5.5nl、约6nl、约6.5nl、约7nl、约7.5nl、约8nl、约8.5nl、约9nl、约9.5nl、约10nl、约11nl、约12nl、约13nl、约14nl、约15nl、约16nl、约17nl、约18nl、约19nl、约20nl、约25nl、约30nl、约35nl、约40nl、约45nl或约50nl。
[0217]
如上所述,分区将包含每个分区一个或若干个(例如,1、2、3、4)珠,其中各珠与具有游离3
′
末端的第一寡核苷酸引物连接。第一寡核苷酸引物将具有珠特异性条形码和与衔接子互补的3
′
末端。在一些实施方式中,条形码的长度将是例如2-10个核苷酸,例如2、3、4、5、6、7、8、9或10个核苷酸。条形码可以是连续的或不连续的,即被其他核苷酸打断。在一些实施方式中,3’端将与整个衔接子序列互补。在一些实施方式中,寡核苷酸的最3
′
的6、7、8、9、10、11、12、13、14、15、16、17、18、19或20个与衔接子中的序列互补。在一些实施方式中,第一寡核苷酸引物进一步包含通用序列或其他附加序列,以协助扩增子测序或下游操作。例如,当使用基于illumina的测序时,第一寡核苷酸引物可以具有5’p5或p7序列(任选地具有第二寡核苷酸引物,所述第二寡核苷酸引物具有两个序列中的另一个)。任选地,第一寡核苷酸引物包含限制或裂解位点,以在需要时从珠移下第一寡核苷酸引物。在一些实施方式中,一旦dna区段与珠连接的第一寡核苷酸引物在分区中时,第一寡核苷酸引物在扩增前被从珠裂解下来。
[0218]
术语“珠”指可以存在于分区中的任何固体支持物,例如,小颗粒或其他固体支持物。示例性珠可包含水凝胶珠。一些情况中,水凝胶是溶胶(sol)形式。一些情况中,水凝胶是凝胶(gel)形式。示例性水凝胶是琼脂糖水凝胶。其它水凝胶包括但不限于例如下列文件中所述:美国专利号4,438,258;6,534,083;8,008,476;8,329,763;美国专利申请号2002/0,009,591;2013/0,022,569;2013/0,034,592;以及国际专利申请号wo/1997/030092和wo/2001/049240。
[0219]
将寡核苷酸与珠连接的方法述于例如wo 2015/200541和美国专利公开us2016/006,0621 a1中。在一些实施方式中,配制为连接水凝胶和条形码的所述寡核苷酸共价连接至水凝胶。本领域已知用于共价连接寡核苷酸与一种或多种水凝胶基质的许多方法。仅举一例,醛衍生化琼脂糖可共价连接至合成寡核苷酸的5
’‑
胺基团。
[0220]
在一些实施方式中,分区还可以包含第二寡核苷酸引物,其可以任选地与珠连接
acid res.28,e87;wo 2000/018957;在此通过引用全文纳入本文)。
[0225]
通常,高通量测序都具有大规模平行这一共同特征,高通量策略的目的是使成本比之前的测序方法低(参见如voelkerding等,clinical chem.,55:641-658,2009;maclean等,nature rev.microbiol.,7:287-296;两者在此都通过引用全文纳入本文)。此类方法可大致分成通常用和不用模板扩增两大类。需要扩增的方法包括罗氏公司以454技术平台商业化的焦磷酸测序(例如,gs 20和gs flx),illumina销售的solexa平台,和应用生物系统公司(applied biosystems)销售的支持态寡核苷酸连接和检测(supported oligonucleotide ligation and detection,solid)平台。非扩增方法也称为单分子测序,其示例有螺旋生物科学公司(helicos biosciences)销售的heliscope平台,visigen公司、牛津纳米孔技术公司(oxford nanopore technologies)、生命技术公司(life technologies)/离子流(ion torrent)和太平洋生物科学公司销售的平台。
[0226]
焦磷酸测序(voelkerding等,clinical chem.,55:641-658,2009;maclean等,nature rev.microbial.,7:287-296;美国专利号6,210,891和6,258,568;其各自通过引用全文纳入本文)中,模板dna被片段化、末端修复、连接衔接子、并用珠捕获单模板分子来进行原位克隆性扩增,珠上载有与衔接子互补的寡核苷酸。载有单模板类型的各珠被划分入油包水微泡中,模板被克隆性扩增,所用技术被称作乳液pcr。扩增后破乳,珠被置入皮升微孔板(picotitre plate)的各孔内,孔在测序反应中作为流动室。在测序酶和发光报告物如萤光素酶的存在下,流动室中发生四种dntp试剂各自的有序迭代引入。合适的dntp被加到测序引物的3
′
末端时,所产生的atp导致孔内发光脉冲,用ccd相机予以记录。能够实现大于或等于400个碱基的读数长度,且能够实现106个序列读数,得到最多达5亿碱基对(mb)的序列。
[0227]
在solexa/illumina平台中(voelkerding等,clinical chem.,55.641-658,2009;maclean等,nature rev.microbial.,7:287-296;美国专利号6,833,246;7,115,400和6,969,488;其各自通过引用全文纳入本文),以较短的读数形式产生测序数据。该方法中,单链的片段化dna末端修复产生5
′‑
磷酸化钝端,然后由klenow介导添加单一a碱基至这些片段的3
′
末端。添加a便于添加t-突出端衔接子寡核苷酸,后者将被用来捕获流动室表面上模板-衔接子分子,流动室中插有寡核苷酸锚。锚被用作pcr引物,但由于模板的长度且其靠近其它邻近的锚寡核苷酸,pcr延伸导致分子“拱跨(arching over)杂交邻近的锚寡核苷酸在流动室表面形成桥式结构。”这些dna环被变性并裂解。正链随后通过可逆染料终止子来测序。通过检测纳入后荧光来确定所纳入核苷酸的序列,在下一轮dntp添加前除去各荧光团并封闭。序列读数长度从36个核苷酸到超过50个核苷酸,总体输出为每次运行分析超过10亿个核苷酸对。
[0228]
用solid技术(voelkerding等,clinical chem.,55:641-658,2009;maclean等,nature rev.microbial.,7:287-296;美国专利号5,912,148;和6,130,073;其各自通过引用全文纳入本文)对核酸分子进行测序还包括片段化模板,连接寡核苷酸衔接子,连接珠,以及乳液pcr克隆性扩增。此后,载有模板的珠被固定化在玻璃流动室的衍生化表面,与衔接子寡核苷酸互补的引物发生退火。但该引物并不用作3
′
延伸,而是用来提供5
′
磷酸基团供连接至问询探针,这些探针含有两个探针特异性碱基及其后6个简并碱基和四种荧光标记其一。solid系统中,问询探针中每个探针3
′
的两个碱基有16种可能的组合而在5
′
末端是
四种荧光标记之一。荧光颜色,及由此辨识的各探针对应于指定的颜色-空间编码方案。多轮(通常7轮)探针退火、连接和荧光检测后变性,然后用相对初始引物错开一位碱基的引物进行第二轮的测序。以此方式,模板序列可通过计算得以重建,而且模板碱基问询两次,得到更高的精确度。序列读数长度平均为35个核苷酸,总体输出为每次测序运行超过40亿个碱基。
[0229]
某些实施方式中,采用纳米孔测序(参见如astier等,j.am.chem.soc.2006年2月8日;128(5)1705-10,通过引用纳入本文)。纳米孔测序的原理涉及纳米孔浸入传导液并跨纳米孔施加电压(伏特)时所发生的现象。这些条件下,可观察到由于离子传导有微弱电流通过纳米孔,而电流的量对纳米孔的大小极度敏感。随着核酸的每个碱基通过该纳米孔,就会导致通过纳米孔的电流幅度有变化,这种变化对于四种碱基的每一种是不同的,从而允许确定dna分子的序列。
[0230]
某些实施方式中,采用螺旋生物科学公司(helicos biosciences corporation)的heliscope(voelkerding等,clinical chem.,55.641-658,2009;maclean等,nature rev.microbial,7:287-296;美国专利号7,169,560;7,282,337;7,482,120;7,501,245;6,818,395;6,911,345和7,501,245;其各自通过引用全文纳入本文)。模板dna被片段化并在3
′
末端多腺苷化,最后的腺苷载有荧光素标记。变性的多腺苷化模板片段连接到流动室表面上的聚(dt)寡核苷酸上。由ccd相机记录被捕获模板的初始物理位置,然后裂解并洗去标记。通过添加聚合酶并系列添加带荧光标记的dntp试剂来实现测序。纳入事件产生对应于dntp的荧光信号,而ccd相机在每轮dntp添加前捕捉信号。序列读数长度在25-50个核苷酸,总体输出为每次运行分析超过10亿个核苷酸对。
[0231]
离子激流技术是基于对dna聚合所释放氢离子的检测的dna测序方法(参见如science 327(5970):1190(2010);美国专利申请号2009/0026082;2009/0127589;2010/0301398;2010/0197507;2010/0188073和2010/0137143;全部通过引用全文纳入本文用于所有目的)。微孔含有待测序的模板dna链。微孔层下方是超敏isfet离子传感器。所有层都包含在cmos半导体芯片内,该芯片与电子工业中所用的类似。在dntp被纳入生长中的互补链时释放氢离子,触发超敏离子传感器。若模板序列中存在均聚重复序列,单次循环中会纳入多个dntp分子。这导致对应数量的氢释放,和成比例的更高电子信号。这一技术与其它测序技术的区别之处在于不使用带修饰核苷酸或光学元件。离子流测序仪的单碱基精确度为每50碱基读数约99.6%,每次运行产生约100mb。读数长度是100个碱基对。5个重复的均聚重复序列的精确度是约98%。离子半导体测序的优势在于测序速度快且前期和运行成本低。
[0232]
可适用于本发明的另一示例性核酸测序方法是由stratos genomics公司开发并用到xpandomer分子的测序方法。该测序方法通常包括提供由模板引导的合成产生的子链。该子链通常包括按对应于靶核酸全部或部分的连续核苷酸序列偶联的多个亚单元,各亚单元含有系连物(tether)、至少一个探针或核碱基残基和至少一个选择性可裂解的键。一种或多种选择性可裂解的键是被裂解以获得xpandomer,其长度大于子链的所述多个亚单元的长度。xpandomer通常包括系连物和报告物元件,报告物元件用以解析序列中对应于靶核酸的全部或部分的连续核苷酸序列的遗传信息。xpandomer的报告物元件随后被测得。对基于xpandomer的方法的补充细节在文献中有记载,例如美国专利公开号2009/0035777,其通
过引用全文纳入本文。
[0233]
其它单分子测序方法包括利用visigen平台通过合成来实时测序(voelkerding等,clinical chem.,55:641-58,2009;美国专利号7,329,492;和美国专利申请序列号11/671,956;和11/781,166;其各自通过引用全文纳入本文),其中,固定化的带引物dna模板用带荧光素修饰的聚合酶和荧光素受体分子来进行链延伸,在核苷酸添加时产生可测的荧光共振能量转移(fret)。
[0234]
另一由太平洋生物科学公司(pacific biosciences)开发的实时单分子测序系统(voelkerding等,clinical chem.,55.641-658,2009;maclean等,nature rev.microbiol.,7:287-296;美国专利号7,170,050;7,302,14;7,313,308;和7,476,503;其各自通过引用全文纳入本文)利用直径50-100nm含有约20仄升(10-21
l)反应体积的反应孔。利用固定化模板、修饰的dna聚合酶和高局部浓度荧光素标记的dntp来进行测序反应。高局部浓度和连续反应条件允许采用激光激发、光学波导和ccd相机来通过荧光信号检测实时捕捉纳入事件。
[0235]
在某些实施方式中,单分子实时(smrt)dna测序方法采用太平洋生物科学公司(pacific biosciences)开发的零级波导(zero-mode waveguide,zmw)或类似方法。用此技术,dna测序在smrt芯片上进行,这些芯片各自含有数千个零级波导(zmw)。zmw是孔,直径是纳米的几十分之一,制造在100nm金属膜中,该膜置于二氧化硅底物上。每个zmw成为提供检测体积仅20仄升(10-21
l)的纳米光子可视化室。以此体积,可在数千个标记的核苷酸背景中检测出单个分子的活性。zmw通过合成进行测序,为观察dna聚合酶提供了窗口。各zmw室内,单个dna聚合酶分子结合在底面从而永久保持在检测体积内。磷酸连接的(phospholinked)核苷酸每种标记有不同颜色的荧光团,这些核苷酸随后以高浓度引入反应溶液中,这些浓度提高酶速度、精确性和处理能力(processivity)。由于zmw体积小,即使在这些高浓度下,检测体积被核苷酸占据的时间占比很小。此外,由于扩散需要携带核苷酸的距离很短,因此对检测体积的经停很快,仅持续几微秒。结果是背景很低。
[0236]
可调试用于本发明的用于此类实时测序的方法和系统记载于,例如,美国专利号7,405,281;7,315,019;7,313,308;7,302,146和7,170,050;美国专利公开号2008/0212960;2008/0206764;2008/0199932;2008/0199874;2008/0176769;2008/0176316;2008/0176241;2008/0165346;2008/0160531;2008/0157005;2008/0153100;2008/0153095;2008/0152281;2008/0152280;2008/0145278;2008/0128627;2008/0108082;2008/0095488;2008/0080059;2008/0050747;2008/0032301;2008/0030628;2008/0009007;2007/0238679;2007/0231804;2007/0206187;2007/0196846;2007/0188750;2007/0161017;2007/0141598;2007/0134128;2007/0128133;2007/0077564;2007/0072196;和2007/0036511;以及korlach等(2008)“选择性铝钝化用于将单个dna聚合酶分子靶向固定在零级波导纳米结构中(selective aluminum passivation for targeted immobilization of single dna polymerase molecules in zero-mode waveguide nanostructures)”pnas105(4):1176-81,其全部在此通过引用全文纳入本文。
[0237]
在一些实施方式中,至少一些分区进一步包含样品(例如一种或多种把核酸,或一种或多种细胞)。在一些实施方式中,包含靶核酸的样品包括dna、rna或其组合或杂合体。在一些实施方式中,样品是包含细胞的样品,例如是单细胞样品。
[0238]
在一些实施方式中,分区还包含用于聚合、扩增、逆转录或引物延伸的其它试剂或组分(例如,聚合酶、盐、核苷酸、缓冲液、稳定剂、引物、可检测试剂或无核酸酶的水)。
[0239]
组合物
[0240]
在一方面,提供了本文所述的包含条码化固体支持物的组合物,与其他固体支持物相比,其中的每个固体支持物被连接至或附接至不同的寡核苷酸(固体支持物寡核苷酸)。在一些实施方式中,固体支持物寡核苷酸包含对于其附接的固体支持物独特的条形码(条形码寡核苷酸)。在一些实施方式中,该组合物包含第一固体支持物,其附接至包含对第一固体支持物独特的第一条形码的第一固体支持物寡核苷酸,和第二固体支持物,其附接至包含对第二固体支持物独特的第二条形码的第二固体支持物寡核苷酸。
[0241]
在一些实施方式中,组合物包含连接或附接至两个或更多不同的寡核苷酸(例如,两个或更多固体支持物寡核苷酸)的固体支持物。两个或更多寡核苷酸可包含:(i)多个第一寡核苷酸,其包含对于固体支持物独特的条形码、捕获序列和测序衔接子;和(ii)一个或多个第二寡核苷酸,其包含3’末端的回文序列、测序衔接子和对于固体支持物独特的条形码。在一些实施方式中,第一寡核苷酸与第二寡核苷酸的比率为至少5∶1、10∶1、100∶1、1000∶1、5000∶1、10000∶1、20000∶1;30000∶1.40000∶1、50000∶1;60000∶1、70000∶1;80000∶1、90000∶1或100000∶1。在一些实施方式中,第二寡核苷酸还包含捕获序列。
[0242]
在一些实施方式中,捕获序列位于第一和第二寡核苷酸的3’末端。在一些实施方式中,捕获序列为多聚dt序列。在一些实施方式中,捕获序列是随机序列。在一些实施方式中,捕获序列是基因特异性序列。
[0243]
在一些实施方式中,组合物包含固体支持物,其连接至(i)多个第一固体支持物寡核苷酸,其包含对固体支持物独特的条形码序列,和捕获序列;和(ii)多个第二寡核苷酸,其具有包含互补于捕获序列的序列的3’末端、条形码序列和5’回文序列。在一些实施方式中,第一固体支持物寡核苷酸和第二寡核苷酸包含相同的条形码序列。
[0244]
本文所述的任何实施方式中,第一固体支持物寡核苷酸与第二寡核苷酸的比率为至少5∶1、10∶1、100∶1、1000∶1、5000∶1、10000∶1、20000∶1;30000∶1.40000∶1、50000∶1;60000∶1、70000∶1;80000∶1、90000∶1或100000∶1。
[0245]
在一些实施方式中,回文序列长度为4-250个寡核苷酸,或其中的任何子范围,例如,长度为4-80、10-20、10-30、10-40、20-30或20-40个寡核苷酸。
[0246]
在一些实施方式中,条形码序列长度为4-250个核苷酸,或其中的任何子范围,如上所述。
[0247]
在一些实施方式中,第一和/或第二寡核苷酸进一步包括以下一种或多种:尿嘧啶碱基;生物素碱基;或用于测序反应的衔接子序列。
[0248]
在一些实施方式中,组合物包含本文所述的分区。分区可包含两个或更多、或多个本文所述的条码化固体支持物,其中每个固体支持物被连接至或附接至不同的寡核苷酸(固体支持物寡核苷酸)。在一些实施方式中,固体支持物寡核苷酸包含对于其附接的固体支持物独特的条形码。在一些实施方式中,分区包含第一固体支持物,其附接至包含对第一固体支持物独特的第一条形码的第一固体支持物寡核苷酸,和第二固体支持物,其附接至包含对第二固体支持物独特的第二条形码的第二固体支持物寡核苷酸。
[0249]
在一些实施方式中,分区包含两个或更多、或多个固体支持物,其中每个固体支持
物连接至或附接至两个或更多不同的寡核苷酸,其中两个或更多寡核苷酸可包含:(i)第一寡核苷酸,其包含对于固体支持物独特的条形码、捕获序列和测序衔接子;和(ii)第二寡核苷酸,其包含3’末端的回文序列、测序衔接子和对于固体支持物独特的条形码。在一些实施方式中,第二寡核苷酸还包含捕获序列。
[0250]
在一些实施方式中,分区包含两个或更多固体支持物,其中每个固体支持物连接至(i)多个第一固体支持物寡核苷酸,其包含对固体支持物独特的条形码序列,和捕获序列;和(ii)多个第二寡核苷酸,其具有包含互补于捕获序列的序列的3’末端、条形码序列和5’回文序列。在一些实施方式中,第一固体支持物寡核苷酸和第二寡核苷酸包含相同的条形码序列。
[0251]
在一些实施方式中,分区包含用于合成或扩增核酸序列的其他组分,例如转座酶、r2逆转座酶、逆转录酶、聚合酶、连接酶、udg酶或标签化酶、核苷酸(如dntp)、引物、缓冲液、二价离子和盐。
[0252]
在一些实施方式中,分区包含用于将多核苷酸尾添加到rna分子上的试剂,例如3
′
多聚(a)尾。该试剂可包含多聚(a)聚合酶和atp。在一些实施方式中,分区包含用于片段化rna的试剂,例如rna酶h和随机引物。随机引物可以是被封闭的,以防止由酶(例如聚合酶、转录酶或逆转座酶)延伸。
[0253]
在一些实施方式中,固体支持物是珠或磁珠。
[0254]
还提供了反应混合物,其包含两个或更多、或多个本文所述的条码化固体支持物,其中每个固体支持物被连接至或附接至不同的寡核苷酸(固体支持物寡核苷酸)。在一些实施方式中,固体支持物寡核苷酸包含对于其附接的固体支持物独特的条形码。在一些实施方式中,该反应混合物包含用于合成或扩增核酸序列的其他组分,例如转座酶、逆转录酶、聚合酶、连接酶、udg酶或标签化酶、核苷酸(如dntp)、引物、缓冲液和盐。在一些实施方式中,固体支持物是珠或磁珠。
[0255]
还提供了试剂盒,其包含两个或更多、或多个本文所述的条码化固体支持物,其中每个固体支持物被连接至或附接至不同的寡核苷酸(固体支持物寡核苷酸)。在一些实施方式中,固体支持物寡核苷酸包含对于其附接的固体支持物独特的条形码。在一些实施方式中,该试剂盒包含用于合成或扩增核酸序列的其他组分,例如转座酶、逆转录酶、聚合酶、连接酶、udg酶或标签化酶、核苷酸(如dntp)、引物、缓冲液和盐。在一些实施方式中,固体支持物是珠或磁珠。在一些实施方式中,试剂盒包含为终端用户使用试剂盒组件的说明书。
[0256]
产生固体支持物的方法
[0257]
还提供了产生固体支持物的方法,该方法包括将寡核苷酸附接至固体支持物,其中寡核苷酸包含对固体支持物独特的条形码序列。在一些实施方式中,寡核苷酸被化学偶联至固体支持物。在一些实施方式中,寡核苷酸被非共价附接至固体支持物。在一些实施方式中,寡核苷酸包含具有通用标签序列或引物序列、条形码序列和寡聚dt序列的核酸序列。在一些实施方式中,寡核苷酸进一步包含连接至检测寡核苷酸的捕获序列,所述检测寡核苷酸具有互补于捕获序列的3’末端,和5’回文序列。
[0258]
在一些实施方式中,一种用于产生连接至寡核苷酸的固体支持物的方法,其包括:
[0259]
i)提供连接至多个第一固体支持物寡核苷酸的固体支持物,包含对于固体支持物独特的条形码序列和3’捕获序列的第一寡核苷酸;
[0260]
ii)将一些固体支持物寡核苷酸的3’捕获序列杂交至具有包含互补于捕获序列的序列的3’末端和5’回文序列的第二寡核苷酸,其中第一固体支持物寡核苷酸与第二寡核苷酸的比率是至少5∶1、10∶1、100∶1、1000∶1、5000∶1、10000∶1、20000∶1;30000∶1.40000∶1、50000∶1;60000∶1、70000∶1;80000∶1、90000∶1或100000∶1;
[0261]
iii)用聚合酶延伸第一固体支持物寡核苷酸,以产生包含第二寡核苷酸的互补物和互补于回文序列的3’末端的延长的固体支持物寡核苷酸;从而产生固体支持物。
[0262]
在一些实施方式中,第一寡核苷酸包含条形码序列的5’尿嘧啶碱基,且来自步骤(iii)的延长的固体支持物寡核苷酸通过udg酶从固体支持物上释放。在一些实施方式中,分区包含udg酶,且来自步骤(iii)的延长的固体支持物寡核苷酸从分区内的固体支持物上释放。
[0263]
在一些实施方式中,通过变性和洗涤除去第二寡核苷酸。在一些实施方式中,在第一扩增循环期间(例如在第一个pcr循环期间)通过变性除去第二寡核苷酸。在一些实施方式中,变性在分区中发生。在一些实施方式中,在将固体支持物添加到分区之前,第二寡核苷酸通过变性被除去。
[0264]
实施例
[0265]
实施例1
[0266]
该实施例提供了用于生成分区的反应混合物,在这种情况下是液滴,并反转录以生成本文所述的嵌合条形码。
[0267][0268][0269]
液滴生成
[0270]
1.用50ul引发溶液引发大芯片。
[0271]
2.向每个细胞孔加入100ul细胞悬浮混合物。
[0272]
3.向每个珠孔加入100ul珠溶液。
[0273]
4.每个油孔上样700ul油。
[0274]
5.放上衬垫,将芯片置于dg上,开始生成液滴。
[0275]
6.将液滴收集到96孔ddpcr板中。
[0276][0277]
1.液滴化条形码和细胞混合悬浮液,在pcr板中每孔转移100ul乳液/油。
[0278]
2.rt在50c下运行45分钟,在c1000上设置体积为125ul。
[0279]
3.bst在70c下运行45分钟。
[0280]
4.rt和bst在85c下热失活5分钟。
[0281]
5.将来自1个样品的所有的孔汇集到1.5ml lobind管中。去除油,留下约20ul。每孔添加50ul液滴破坏剂。
[0282]
6.从试管底部去除50ul油/液滴破坏剂。
[0283]
7.加入200ul水+230ul ampure xp。(结合10分钟,磁体10分钟,etoh洗涤2次,干燥5分钟,洗脱2分钟,磁体2分钟。)
[0284]
8.在100ul rsb+0.05%tween20中洗脱样品。
[0285]
9.向每个样品中加入60ul ampure xp用于第二清理。(结合5分钟,磁体5分钟,2etoh洗涤,干燥5分钟,etoh洗涤2次,洗脱2分钟,磁体2分钟。)
[0286]
10.将样品洗脱于11ul rsb中。
[0287]
11. 1ul cdna在生物分析仪(bioanalyzer)上跑样。
[0288]
12.继续标签化、pcr、最终清理和文库定量。
[0289]
06082018_v2_标签_大芯片_hek/3t3_10k_标签化和nxtera
[0290]
标签化和pcr,来自(surecell v1方案)
[0291][0292]
标签化反应体系(rxn)在55c孵育5分钟并在4c保持
[0293]
当温度达到4c时立即移开板,不要置于4c超过5分钟
[0294]
加入10ul标签化终止缓冲液,混合并沉降,在装配pcr混合物之前在室温下静置5分钟。
[0295][0296]
pcr循环方案(eureka)
[0297][0298]
实施例2
[0299]
本实施例描述了单细胞总rna文库制备工作流程中条形码寡核苷酸嵌合体的形成。
[0300]
细胞制备。k-562细胞(atcc,ccl-243)和nih3t3细胞(atcc,crl-1658)被用于ddseq试剂设置。从t75培养瓶中收获细胞并用冷的1x pbs+0.1%bsa溶液洗涤3次,然后在bio-rad的tc20细胞计数器上进行细胞计数。细胞计数后,细胞在1x pbs+0.1%bsa溶液中被稀释到终浓度为300个细胞/μl。k-562和nih3t3细胞以1∶1的比率混合用于实验。
[0301]
单细胞分离和条码化。制备细胞和珠悬浮混合物,然后加载到surecell ddseq m料筒(biorad,pn12008720)中。细胞悬浮混合物的组合物包括tris缓冲液、盐、dntp、5’和3’衔接子引物、去污剂、密度梯度介质、酶混合物、dna聚合酶和52个细胞/μl的k-562/nih3t3细胞。珠悬浮混合物包括tris缓冲液、盐、atp、去污剂、密度梯度介质、酶、和10,000个条码化珠/μl(注:条码化珠由2种寡核苷酸类型组成,3’多聚(dt)和3’回文序列)。细胞悬浮混合物和珠悬浮混合物各20μl,以及80μl封装油,被分配到surecell ddseq m料筒中对应的带标记的孔中。将料筒装入ddseq单细胞分离器(single cell isolator)(bio-rad,pn 12004336)中并运行大约5分钟以在液滴中形成组合细胞和珠的乳液。
[0302]
乳液液滴被转移到bio-rad的ddppcr 96孔板中,并使用8盖条密封。在bio-rad的c1000 touch热循环仪中进行液滴孵育,并设置为37℃ 30分钟、94℃ 2分钟、59℃ 2分钟、72℃ 2分钟、95℃ 30秒,48℃保持1分钟,72℃ 2分钟,以0.1c/秒的速度下降至4℃,并在4℃下保持15分钟。
[0303]
文库制备。通过向每个样品中添加40μl液滴破坏剂来释放乳液液滴的内容物。来自珠寡核苷酸的未结合dt尾被过量的多聚(da)封闭。在含有tris缓冲液、盐、dntp、3’衔接子寡核苷酸、rna酶抑制剂和2d酶的100μl反应中,条码化的捕获的rna被逆转录并加上3’衔接子。反应在bio-rad的c1000touch热循环仪中在34c孵育1小时。然后按照制造商的说明书使用80μl agencourt ampure xp珠纯化cdna文库。
[0304]
纯化的cdna经扩增,并在含有kapa hifi hotstart ready混合物和nextera p5和p7标引引物的50μl体积中进行样品标引。pcr在bio-rad的c1000 touch热循环仪中进行,初始变性步骤为95℃ 3分钟,循环条件为98℃ 20秒、60℃ 45秒和72℃ 60秒,12个循环,最后一个循环72℃ 5分钟。使用40μl agencourt ampure xp珠对pcr产物进行大小选择和纯化。最终的dna文库在测序前在安捷伦生物分析仪(agilent bioanalyzer)上进行分析和定量。
[0305]
测序。使用nextseq 500/550高输出试剂盒(150个循环)在illumina的nextseq系统中对dna文库进行测序。文库以1.8pm的最终浓度加载到系统中,运行设置为读数1为54个循环、读取2为75个循环和标引1为8个循环。
[0306]
分析。使用bio-rad的内部scrna seq流程分析测序数据。分析和结果概括在下图中。
[0307]
结果:输入样品的细胞总数为1040个(52个细胞/ul x 20ul)。珠合并前读出的细胞数为1480(图12a),珠合并后读出的细胞数为792(图12b)。数据显示珠合并是功能性和有效的。细胞回收率为76%,与细胞输入和预期产量一致。观察到的和预期的珠分布也彼此紧密匹配(图14),且支持条形码合并的有效性。总体而言,结果表明珠条形码去卷积可以通过本实施例中采用的方法实现。
[0308]
实施例3
[0309]
本实施例描述了液滴中珠条形码寡核苷酸多联体的形成,使用r2逆转座酶。
[0310]
r2逆转座酶用于在3'wta文库中生成异二聚体,用于珠去卷积。工作流程如下图所说明。在封装细胞和珠(步骤1)后,r2逆转座酶被添加到划分反应(compartmentalized reaction)中(步骤2),并在逆转录和第二链合成之前形成多联体。纯化过程中(步骤3)的磁珠大小分离会产生小尺寸部分(<300bp)和大尺寸部分(>300bp)。然后工作流程分为小部分(<300bp)(步骤4、6、7)和大部分(>300bp)(步骤5)。每个部分都经过独立处理以生成测序文库,并在加载到测序仪之前进行组合。r2逆转座酶形成的二聚体用于生物信息学珠去卷积。
[0311][0312]
虽然通过阐述和举例的方式详细描述了上述公开以清晰理解,但本发明技术人员应理解可在所附权利要求书范围内实施某些改变和修改。此外,本文提供的各参考文献,包括专利、专利申请、非专利文献和genbank登录号,通过引用全文纳入本文,就如同各参考文献单独通过引用纳入本文。
[0313]
当即时应用和本文提供的参考之间存在冲突时,即时应用占主导地位。