1.本发明涉及语音识别技术领域,尤其是一种哭叫声音侦测方法和装置。
背景技术:
2.例如婴儿哭声、跌倒叫声、危险受惊的尖叫声甚或求救声等哭叫声音的侦测,是现阶段智慧家庭、居家生活及小区安全等场景中不可或缺的智能侦测项目之一。其使用的声音侦测方法从早期最简单的声音能量侦测,到诸如基于人声频谱特征的语音识别技术,然后再到目前被普遍使用的基于机器学习、深度学习、等类神经网络技术,前者基于声音能量侦测方法过于简单,容易误报,后者则需要搜集大量的实地场景声音数据,进行训练,在实用上需要较大的运算资源,而且各式各样的场景数据不易搜集。
3.本提案提出一种针对哭叫声类型的声音侦测方法,使用了哭叫声特有的讯号特征来判别,不需要庞大的训练数据库及运算资源,仅需要靠讯号本身特有的特征参数抽取及一些规则性的判断,在低运算的微处理器(mcu)上即可达到侦测的目的。
技术实现要素:
4.本发明提出了一种哭叫声音侦测方法和装置,以解决上文提到的现有技术的缺陷。
5.在一个方面,本发明提出了一种哭叫声音侦测方法,该方法包括以下步骤:
6.s1:在声音采集设备未接收到声音数据时,通过设置初始侦测状态,对侦测所需的参数进行初始化以表征所述声音采集设备尚未侦测到任何声音数据的状态,当声音采集设备接收到声音数据后,对所述声音数据进行包括音框(frame)撷取与频谱等化(equalization)在内的前处理,生成包含若干个一定长度的音框的时域讯号;
7.s2:对所述时域讯号的波形数据的均方根进行计算得到所述时域讯号的能量参数,将所述时域讯号的能量参数与预设的能量阀值进行比较,判断所述时域讯号的能量参数是否超过所述能量阀值,若是,则记录所述时域讯号的长度并执行s3;
8.s3:从多个维度对所述时域讯号进行计算抽取声音特征参数,并储存所述声音特征参数,所述声音特征参数包括频谱峰点位置、基本频率、谐波频率位置、声音清晰度和声音纯度;
9.s4:分析判断所述时域讯号的长度、所述时域讯号中有声音的音框的长度以及所述声音特征参数是否满足预设的条件,若是则将所述声音数据判断为哭叫声。
10.以上方法使用了哭叫声特有的讯号特征来判别,不需要庞大的训练数据库及运算资源,仅需要对讯号本身特有的特征参数进行抽取并进行一些规则性的判断,即可精确地判断出哭叫声。
11.在具体的实施例中,所述音框(frame)撷取具体包括:
12.采用包括汉明窗口(hamming window)在内的方法将所述声音数据撷取为若干个一定长度的音框,并在后续对所述时域讯号中的每个音框进行所述s2至所述s4中的步骤。
13.在具体的实施例中,所述频谱等化(equalization)包括:
14.补偿所述声音采集设备接收声音数据时的失真,具体方法包括强化所述声音数据中的高频的部分。通过补偿声音采集设备接收声音数据时的失真以减少频谱上的失真。
15.在具体的实施例中,所述能量阀值为:
16.一个常数;或
17.所述时域讯号的最大能量乘以某一预设的百分比的值。
18.在具体的实施例中,所述频谱峰点位置的抽取具体包括:
19.对所述时域讯号进行快速傅立叶变换从而估算出频谱振幅,再利用所述频谱振幅估算频谱峰点位置。
20.在具体的实施例中,所述基本频率和所述谐波频率位置的抽取具体包括:
21.利用所述频谱峰点位置对所述时域讯号进行声音周期性检查,从而推算所述时域讯号的基本频率(fundamental frequency)和谐波频率位置。
22.在具体的实施例中,所述声音清晰度的抽取具体包括:
23.根据所述谐波频率位置估算所述时域讯号的总谐波数,再根据所述基本频率和所述时域讯号的最大频率计算出最大可能的谐波数,最后根据所述总谐波数和所述最大可能的谐波数对所述声音清晰度进行定义;
24.所述声音清晰度被定义为:
25.clarity=h
m
/m x 100%=h
m x f0/f
m x 100%
26.其中,clarity表示所述声音清晰度,f0表示所述基本频率,f
m
表示最大信号频率,h
m
表示所述总谐波数,m表示所述最大可能的谐波数,且m=f
m
/f0。
27.在具体的实施例中,所述声音纯度的抽取具体包括:
28.根据各个所述谐波频率位置的波峰的平均值和波谷的平均值的比值来估算谐波波峰的共振强度,再用所述共振强度表示所述声音纯度。通过以上内容可知,通常来说,谐波波峰越陡,表示声音纯度越高,反之,表示声音纯度越低。对每一个音框算好声音特征参数后,先统计储存,直到声音变小,能量低于某个阀值后,若纪录的声音长度够长,则跳转至s4进行分析,看是否符合哭叫声音特征,若是则发出通知或警告,若否则跳转至s1。
29.在具体的实施例中,所述s4具体包括:
30.分析判断所述时域讯号的长度是否在时序讯号长度预设范围内,若否则跳转至s1;若是则
31.分析判断所述时域讯号中所有有声音的音框的长度之和是否大于所述声音数据的长度乘以长度预设比例,若否则跳转至s1;若是则
32.分析判断所述基本频率是否在基本频率预设范围内,若否则跳转至s1;若是则
33.分析判断所述时域讯号中所述声音清晰度大于清晰度预设值的音框的长度之和,是否大于所述时域讯号中所有有声音的音框的长度之和乘以清晰度预设比例,若否则跳转至s1;若是则
34.分析判断所述时域讯号中所述声音纯度大于纯度预设值的音框的长度之和,是否大于所述时域讯号中所有有声音的音框的长度之和乘以纯度预设比例,若否则跳转至s1;若是则将所述声音数据判断为哭叫声。
35.在具体的实施例中,所述判断所述时域讯号的能量参数是否超过所述能量阀值,
若否,则再判断已被记录的所述时域讯号中,连续超过阀值的时域讯号的总长度是否超过预设的长度阀值:
36.若是,则表示在先前的侦测过程中已有侦测到某段符合侦测需求的声音,提取在所述先前的侦测过程中已储存好的声音特征参数来执行s4;
37.若否,则跳转回s1。
38.在具体的实施例中,所述声音采集设备具体包括:
39.麦克风收音装置、放大器、滤波器和模拟数字转换装置。
40.在具体的实施例中,所述时域讯号中有声音的音框的判断通过检测该音框的所述频谱峰点位置之间是否存在谐波特性的倍数关系,若所述基本频率在某定义的频率范围内,则判定此音框为有声音的音框,反之为无声音的音框。
41.根据本发明的第二方面,提出了一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被计算机处理器执行时实施上述方法。
42.根据本发明的第三方面,提出一种哭叫声音侦测装置,该装置包括:
43.初始侦测状态设置单元:配置用于在声音采集设备未接收到声音数据时,通过设置初始侦测状态,对侦测所需的参数进行初始化以表征所述声音采集设备尚未侦测到任何声音数据的状态,当声音采集设备接收到声音数据后,对所述声音数据进行包括音框(frame)撷取与频谱等化(equalization)在内的前处理,生成包含若干个一定长度的音框的时域讯号;
44.声音能量估算单元:配置用于对所述时域讯号的波形数据的均方根进行计算得到所述时域讯号的能量参数,将所述时域讯号的能量参数与预设的能量阀值进行比较,判断所述时域讯号的能量参数是否超过所述能量阀值,若是,则记录所述时域讯号的长度并执行声音特征抽取单元;
45.声音特征抽取单元:配置用于从多个维度对所述时域讯号进行计算抽取声音特征参数,并储存所述声音特征参数,所述声音特征参数包括频谱峰点位置、基本频率、谐波频率位置、声音清晰度和声音纯度;
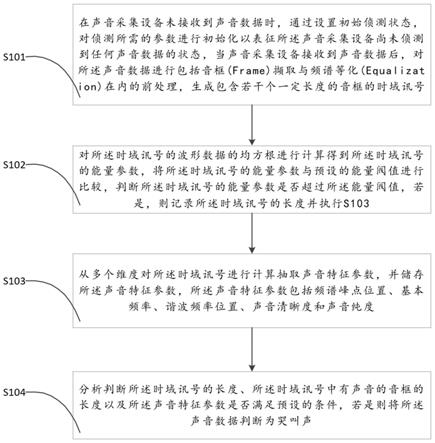
46.哭叫声音判断单元:配置用于分析判断所述时域讯号的长度、所述时域讯号中有声音的音框的长度以及所述声音特征参数是否满足预设的条件,若是则将所述声音数据判断为哭叫声。
47.本发明使用了多种哭叫声特有的讯号特征来判别,不仅提高了侦测准确度,而且不需要庞大的训练数据库及运算资源,只要对讯号本身特有的声音特征参数进行抽取并进行一些规则性的判断,在低运算的微处理器(mcu)上即可达到有效侦测的目的。另外,本提案之方法亦可当作哭叫声的第一阶段侦测,以较省力、省资源的方式,尽量提高正样本的侦测正确率,并可过滤掉大部分的负样本,在第二阶段再以有限的网络资源、后端服务器资源等,做更准确的侦测判断,即可省去大部分的网络带宽及大量的服务器负载。
附图说明
48.包括附图以提供对实施例的进一步理解并且附图被并入本说明书中并且构成本说明书的一部分。附图图示了实施例并且与描述一起用于解释本发明的原理。将容易认识到其它实施例和实施例的很多预期优点,因为通过引用以下详细描述,它们变得被更好地
理解。通过阅读参照以下附图所作的对非限制性实施例所作的详细描述,本技术的其它特征、目的和优点将会变得更明显:
49.图1是本发明的一个实施例的一种哭叫声音侦测方法的流程图;
50.图2是本发明的一个具体的实施例的哭叫声音侦测硬件的架构流程图;
51.图3是本发明的一个具体的实施例的声音采集设备的架构流程图;
52.图4是本发明的一个具体的实施例的哭叫声音侦测方法的流程图;
53.图5是本发明的一个具体的实施例的哭叫声音特征抽取方法的流程图;
54.图6是本发明的一个具体的实施例的哭叫声音判断方法的流程图;
55.图7是本发明的一个实施例的一种哭叫声音侦测装置的框架图。
具体实施方式
56.下面结合附图和实施例对本技术作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释相关发明,而非对该发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与有关发明相关的部分。
57.需要说明的是,在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本技术。
58.根据本发明的一个实施例的一种哭叫声音侦测方法,图1示出了根据本发明的实施例的一种哭叫声音侦测方法的流程图。如图1所示,该方法包括以下步骤:
59.s101:在声音采集设备未接收到声音数据时,通过设置初始侦测状态,对侦测所需的参数进行初始化以表征所述声音采集设备尚未侦测到任何声音数据的状态,当声音采集设备接收到声音数据后,对所述声音数据进行包括音框(frame)撷取与频谱等化(equalization)在内的前处理,生成包含若干个一定长度的音框的时域讯号。
60.在具体的实施例中,本提案提出的一种哭叫声音侦测方法,其硬件包含一个声音采集装置201、一个处理器运算单元202、一个内存单元203及一个警报通知单元204,其架构如图2所示。首先声音经由声音采集设备采集进来。
61.在具体的实施例中,所述声音采集设备如图3所示,具体包括:
62.麦克风收音装置301、放大器302、滤波器303和模拟数字转换装置304。
63.在具体的实施例中,所述音框(frame)撷取具体包括:
64.采用包括汉明窗口(hamming window)在内的方法将所述声音数据撷取为若干个一定长度的音框,并在后续对所述时域讯号中的每个音框进行所述s102至所述s104中的步骤。
65.在具体的实施例中,所述频谱等化(equalization)包括:
66.补偿所述声音采集设备接收声音数据时的失真,具体方法包括强化所述声音数据中的高频的部分。通过补偿声音采集设备接收声音数据时的失真以减少频谱上的失真。
67.在具体的实施例中,麦克风收音装置将声音讯号转成电压讯号,电压讯号经过放大器处理,放大器依使用者之需求,可预先设定好几种度不的灵敏度,将信号调整至适当的大小,然后再经过滤波器处理,在滤波器处理中,可调整信号的频谱响应,做声音加强、频谱等化(equalization)处理或滤噪声处理等,最后经过一个模拟数字转换器,设定好合适的采样频率、位数等,将模拟讯号转成数字讯号。
68.在具体的实施例中,数字讯号被交给处理器运算单元202做进一步声音数据的前处理及声音信号特征分析,在此处理器运算单元202中,我们提出了一种针对哭叫声类型的声音侦测方法,使用了哭叫声特有的讯号特征来判别,并基于一些规则性的判断方法(rule based method)的方法,来侦测哭叫声音,达到在有限资源的低阶平台即能有效侦测的目的,内存单元203则主要是储存运算处理算法所需的程序代码或表格及运算过程中的数据暂存,最后侦测结果判断是否发出警报通知,然后发送信号给警报通知单元204,再将侦测的结果利用无线通信方式发送讯息给用户或相关单位。
69.在具体的实施例中,本方法在处理器运算单元202中,实现了一种哭叫声音侦测方法,其方法流程如图4所示。
70.根据图4所示,在本实施例中,首先设置初始侦测状态401,将各种参数初始化为尚未侦测到任何声音事件的状态,然后声音数据由声音采集设备录制得到后,进行前处理402,此前处理402主要包含了音框(frame)撷取与频谱等化(equalization)处理等,在侦测的流程中,每个音框会运算一次,每个音框大小约为30ms,音框撷取可采用类似汉明窗口(hamming window)等方法,以减少频谱上的失真,频谱等化的部分则主要是补偿麦克风录制音频的失真,通常会强化高频的部分。接着是声音能量估算403,这里的能量参数可以由时域讯号波形数据的均方根(root of mean square)来计算。
71.然后执行判断能量参数是否超过某预设阀值404步骤,此预设阀值可以是一个常数,也可以是最大能量的某一百分比:
72.若是,则纪录声音长度并进行下一个步骤,即声音特征抽取405,并储存声音特征参数406;
73.若否,则再判断之前累计的连续超过阀值的声音总长度是否超过一个预设阀值:
74.若是,则表示已有侦测到某段符合侦测需求的声音,再由储存好的声音特征参数进行哭叫声音判断407;
75.若否,则回到设置初始侦测状态401,将各参数初始化为尚未侦测到任何声音事件的状态。
76.s102:对所述时域讯号的波形数据的均方根进行计算得到所述时域讯号的能量参数,将所述时域讯号的能量参数与预设的能量阀值进行比较,判断所述时域讯号的能量参数是否超过所述能量阀值,若是,则记录所述时域讯号的长度并执行s103。
77.在具体的实施例中,所述能量阀值为:
78.一个常数;或
79.所述时域讯号的最大能量乘以某一预设的百分比的值。
80.s103:从多个维度对所述时域讯号进行计算抽取声音特征参数,并储存所述声音特征参数,所述声音特征参数包括频谱峰点位置、基本频率、谐波频率位置、声音清晰度和声音纯度。
81.在具体的实施例中,s103的流程图如图5所示。
82.在具体的实施例中,所述频谱峰点位置的抽取具体包括:
83.对所述时域讯号进行快速傅立叶变换从而估算出频谱振幅,再利用所述频谱振幅估算频谱峰点位置。
84.在具体的实施例中,所述基本频率和所述谐波频率位置的抽取具体包括:
85.利用所述频谱峰点位置对所述时域讯号进行声音周期性检查,从而推算所述时域讯号的基本频率(fundamental frequency)和谐波频率位置。
86.在具体的实施例中,所述声音清晰度的抽取具体包括:
87.根据所述谐波频率位置估算所述时域讯号的总谐波数,再根据所述基本频率和所述时域讯号的最大频率计算出最大可能的谐波数,最后根据所述总谐波数和所述最大可能的谐波数对所述声音清晰度进行定义;
88.所述声音清晰度被定义为:
89.clarity=h
m
/m x 100%=h
m x f0/f
m x 100%
90.其中,clarity表示所述声音清晰度,f0表示所述基本频率,f
m
表示最大信号频率,h
m
表示所述总谐波数,m表示所述最大可能的谐波数,且m=f
m
/f0。
91.在具体的实施例中,所述声音纯度的抽取具体包括:
92.根据各个所述谐波频率位置的波峰的平均值和波谷的平均值的比值来估算谐波波峰的共振强度,再用所述共振强度表示所述声音纯度。通过以上内容可知,通常来说,谐波波峰越陡,表示声音纯度越高,反之,表示声音纯度越低。对每一个音框算好声音特征参数后,先统计储存,直到声音变小,能量低于某个阀值后,若纪录的声音长度够长,则跳转至s104进行分析,看是否符合哭叫声音特征,若是则发出通知或警告,若否则跳转至s101。
93.在具体的实施例中,所述时域讯号中有声音的音框的判断通过检测该音框的所述频谱峰点位置之间是否存在谐波特性的倍数关系,若所述基本频率在某定义的频率范围内,则判定此音框为有声音的音框,反之为无声音的音框。
94.在具体的实施例中,哭叫声音特征抽取方法流程如图5所示。首先将前处理好的声音数据,经由快速傅立叶变换(fast fourier transform;fft)估算频谱振幅501,再由频谱振幅进行估算频谱峰点位置502,该频谱峰点位置算法举例说明如下:
95.频谱振幅数据以x(k)表示,其中k=1,2,
…
,n,2*n为fft的长度,则
96.扫描所有满足下面峰点条件的位置:
97.x(k)>x(k
‑
1)且x(k)>x(k+1)且
98.x(k)>x(k
‑
2)且x(k)>x(k+2)且
99.x(k)>x(k
‑
3)且x(k)>x(k+3),其中k=6,7,8,
…
,n
‑5100.若k满足上式峰点条件后,再判断是否
101.x(k
‑
10)~x(k
‑
1)之间的最小值小于x(k)/2,其中若k
‑
10<=0则取x(1)~x(k
‑
1)之间的最小值
102.且
103.x(k+1)~x(k+10)之间的最小值小于x(k)/2,其中若k+10>n则取x(k+1)~x(n)之间的最小值
104.若是,则纪录每个峰点位置k为peak(i),其中i=1,2,
…
,p表示第几个峰点,p表示峰点总数。
105.在具体的实施例中,由峰点位置peak(i)做声音周期性检查503,以推算声音的基本频率(fundamental frequency)及正确的谐波频率位置,其方法说明如下:
106.由人声讯号的特性,从频谱上来看,其谐波频率刚好会是基本频率的整数倍,而基本频率就是第一个谐波频率,我们可由谐波频率来检查推算准确的基本频率,这里举例由
前3~4个峰点位置peak(i)来进行推算基本频率504,其规则判断如下:
107.首先分析峰点位置peak(i),i=1,2,3,4
108.1.peak(i)刚好是谐波频率位置,用“1”表示
109.2.peak(i)不是谐波频率位置,用“0”表示
110.3.谐波频率位置没有明显的波峰特征,以致peak(i)其中少了一个谐波频率位置,用“x”表示
111.则真正的谐波频率位置与peak(i)可能有下面对应关系,并得以推算基本频率f0:
112.111
→
f0=peak(3)/3
113.110
→
f0=peak(2)/2
114.101
→
f0=peak(3)/2
115.1001
→
f0=peak(4)/2
116.011
→
f0=peak(3)/2
117.0011
→
f0=peak(4)/2
118.0101
→
f0=peak(4)/2
119.11x1
→
f0=peak(3)/4
120.1x11
→
f0=peak(3)/4
121.x111
→
f0=peak(3)/4
122.要如何判别其对应关系,只需要检测其峰点位置之间是否存在谐波特性的倍数关系即可,若估算出基本频率,且在某定义的频率范围内,则判定此音框为有声(voiced),反之为无声(unvoiced)。
123.接着进行估算谐波频率位置505,找出该音框所有谐波频率位置,即检查声音频谱振幅频率f在基本频率f0的整数倍频率位置附近,
124.f=n*f0,其中n=2,3,4,
…
,且n*f0<n,看是否刚好是峰点位置,若是,则认为该峰点位置为一谐波频率位置,并纪录之。然后再进行估算声音清晰度506,在此定义声音清晰度之计算方式如下:
125.给定基本频率f0及最大信号频率f
m
,通常f
m
=1/2采样频率f
s
,
126.h
m
为该音框所估算之总谐波数,m为最大可能的谐波数即m=f
m
/f0,则定义声音清晰度为
127.clarity=h
m
/m x 100%=h
m x f0/f
m x 100%
128.由此定义可看出,声音的谐波数越多,表示其清晰度越高,声音的谐波数越少,表示其越沙哑。
129.接下来是估算声音纯度507,在此所定义的声音纯度是估算谐波波峰的共振强度,藉由波峰跟波谷的平均大小比值来完成,其方法说明如下:
130.假设每个谐波频率位置为h(m),m=1,2,3,
…
h
m
,则
131.可得到谐波波峰的最大值为
132.x
p
(m)=x(h(m)),m=1,2,3,
…
h
m
,
133.可得到两相邻谐波波谷的最平均值为
134.x
v
(m)=(min(x(h(m
‑
1):h(m))+min(x(h(m):h(m+1)))/2,m=1,2,3,
…
h
m
,
135.其中min(x(h(m
‑
1):h(m))表示波峰位置h(m
‑
1)到波峰位置h(m)之间的最小值,
136.min(x(h(m):h(m+1))表示波峰位置h(m)到波峰位置h(m+1)之间的最小值,
137.且定义h(0)=1,h(h
m
+1)=n,则声音纯度可定义为
138.xp=σ
m
(x
p
(m)),m=1,2,3,
…
h
m
,
139.xv=σ
m
(x
v
(m)),m=1,2,3,
…
h
m
,
140.purity=(xp
‑
xv)x100%/xp
141.由此定义可看出谐波波峰越陡,表示其纯度越高,反之,表示其纯度越低。
142.每一个音框算好声音特征参数后,先统计储存声音特征参数508,直到声音变小,能量低于某个阀值后,若纪录的声音长度够长,则在s104中进行分析,看是否符合哭叫声音特征,若是则发出通知或警告,若否则跳转至s101。
143.s104:分析判断所述时域讯号的长度、所述时域讯号中有声音的音框的长度以及所述声音特征参数是否满足预设的条件,若是则将所述声音数据判断为哭叫声。
144.在具体的实施例中,所述s104具体包括:
145.分析判断所述时域讯号的长度是否在时序讯号长度预设范围内,若否则跳转至s101;若是则
146.分析判断所述时域讯号中所有有声音的音框的长度之和是否大于所述声音数据的长度乘以长度预设比例,若否则跳转至s101;若是则
147.分析判断所述基本频率是否在基本频率预设范围内,若否则跳转至s101;若是则
148.分析判断所述时域讯号中所述声音清晰度大于清晰度预设值的音框的长度之和,是否大于所述时域讯号中所有有声音的音框的长度之和乘以清晰度预设比例,若否则跳转至s101;若是则
149.分析判断所述时域讯号中所述声音纯度大于纯度预设值的音框的长度之和,是否大于所述时域讯号中所有有声音的音框的长度之和乘以纯度预设比例,若否则跳转至s101;若是则将所述声音数据判断为哭叫声。
150.在具体的实施例中,所述判断所述时域讯号的能量参数是否超过所述能量阀值,若否,则再判断已被记录的所述时域讯号中,连续超过阀值的时域讯号的总长度是否超过预设的长度阀值:
151.若是,则表示在先前的侦测过程中已有侦测到某段符合侦测需求的声音,提取在所述先前的侦测过程中已储存好的声音特征参数来执行s104;
152.若否,则跳转回s101。
153.在具体的实施例中,s104的流程图如图6所示。具体说明如下:
154.首先判断声音长度是否在一预设范围内,为方便说明,这里预设为0.32秒到6秒之间,声音采样频率(sampling rate)为16000hz,每个音框长度为512个样本点(samples),fft长度亦为512,每个音框相当于32毫秒(ms),0.32秒即表示10个音框数,若声音长度在此范围内,则再判断有声音框数是否大于声音总长度的某一预设比例,在这里预设当声音长度在0.32秒到3秒之间时,有声音框数需大于等于声音长度的50%,当声音长度在3秒到6秒之间时,有声音框数需大于等于声音长度的70%。接着在判断基本频率变化是否在默认范围内的步骤中,我们假设哭声或叫声的音调是会拉得比较长,而且音调的变化也不大,但并不是完全没变化,在这里,由fft长度换算频率的分辨率为16000hz/512=31.25hz,也就是说频率位置,每相差1代表相差31.25hz,为不失一般性,这里定义当基本频率位置变化在2
~3之间时,表示其变化缓慢,符合哭叫声特征,当基本频率位置变化小于等于1时,表示音调完全没变化,若整体音调都不变,表示这不是自然哭叫声的特征,当基本频率位置变化大于3时,表示可能是大声讲话中或乱叫等,亦不符合哭叫声特征,统计这些符合哭叫声音调变化特征的音框数,然后判断是否大于有声音框数的某个比例,即可藉以判断是否符合哭叫声的特征。接下来,判断声音的清晰度与纯度,清晰度与纯度跟声音本身的特色有关,如婴儿哭声,其清晰度与纯度都相当高,可以到70%以上,一般人说话的声音,其清晰度与纯度大约落在50%以下,这里我们以婴儿哭声为例,为不失一般性,设定当每个音框清晰度大于70%时,则计数此音框,若满足此清晰度之音框数大于有声音框数的30%时,则判定符合侦测条件,并设定当每个音框纯度大于80%时,则计数此音框,若满足此纯度之音框数大于有声音框数的30%时,则判定符合侦测条件。若上述所有侦测条件皆满足,则发出哭叫声音通知提醒,否则回到s101。
155.图7示出了本发明的一个实施例的一种哭叫声音侦测装置的框架图。该装置包括初始侦测状态设置单元701、声音能量估算单元702、声音特征抽取单元703和哭叫声音判断单元704。
156.在具体的实施例中,初始侦测状态设置单元701被配置用于在声音采集设备未接收到声音数据时,通过设置初始侦测状态,对侦测所需的参数进行初始化以表征所述声音采集设备尚未侦测到任何声音数据的状态,当声音采集设备接收到声音数据后,对所述声音数据进行包括音框(frame)撷取与频谱等化(equalization)在内的前处理,生成包含若干个一定长度的音框的时域讯号;
157.声音能量估算单元702被配置用于对所述时域讯号的波形数据的均方根进行计算得到所述时域讯号的能量参数,将所述时域讯号的能量参数与预设的能量阀值进行比较,判断所述时域讯号的能量参数是否超过所述能量阀值,若是,则记录所述时域讯号的长度并执行声音特征抽取单元;
158.声音特征抽取单元703被配置用于从多个维度对所述时域讯号进行计算抽取声音特征参数,并储存所述声音特征参数,所述声音特征参数包括频谱峰点位置、基本频率、谐波频率位置、声音清晰度和声音纯度;
159.哭叫声音判断单元704被配置用于分析判断所述时域讯号的长度、所述时域讯号中有声音的音框的长度以及所述声音特征参数是否满足预设的条件,若是则将所述声音数据判断为哭叫声。
160.本装置使用了多种哭叫声特有的讯号特征来判别,不仅提高了侦测准确度,而且不需要庞大的训练数据库及运算资源,只要对讯号本身特有的声音特征参数进行抽取并进行一些规则性的判断,在低运算的微处理器(mcu)上即可达到有效侦测的目的。另外,本提案之方法亦可当作哭叫声的第一阶段侦测,以较省力、省资源的方式,尽量提高正样本的侦测正确率,并可过滤掉大部分的负样本,在第二阶段再以有限的网络资源、后端服务器资源等,做更准确的侦测判断,即可省去大部分的网络带宽及大量的服务器负载。
161.本发明的实施例还涉及一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被计算机处理器执行时实施上文中的方法。该计算机程序包含用于执行流程图所示的方法的程序代码。需要说明的是,本技术的计算机可读介质可以是计算机可读信号介质或者计算机可读介质或者是上述两者的任意组合。
162.本发明使用了多种哭叫声特有的讯号特征来判别,不仅提高了侦测准确度,而且不需要庞大的训练数据库及运算资源,只要对讯号本身特有的声音特征参数进行抽取并进行一些规则性的判断,在低运算的微处理器(mcu)上即可达到有效侦测的目的。另外,本提案之方法亦可当作哭叫声的第一阶段侦测,以较省力、省资源的方式,尽量提高正样本的侦测正确率,并可过滤掉大部分的负样本,在第二阶段再以有限的网络资源、后端服务器资源等,做更准确的侦测判断,即可省去大部分的网络带宽及大量的服务器负载。
163.以上描述仅为本技术的较佳实施例以及对所运用技术原理的说明。本领域技术人员应当理解,本技术中所涉及的发明范围,并不限于上述技术特征的特定组合而成的技术方案,同时也应涵盖在不脱离上述发明构思的情况下,由上述技术特征或其等同特征进行任意组合而形成的其它技术方案。例如上述特征与本技术中公开的(但不限于)具有类似功能的技术特征进行互相替换而形成的技术方案。