1.本技术涉及语音合成(tts)技术领域,具体而言,涉及一种基于线性自注意力的语音合成方法及系统。
背景技术:
2.语音合成(tts)是近些年来研究比较热门的课题,其为一种将计算机自己产生的、或外部输入的文字信息转变为可以听得懂的、流利的汉语口语输出的技术,是语音信号处理中具有挑战性的研究问题之一。
3.一般来说,一个说话人的一段语音可以由三个因素组成,1)语言层面的句子结构,词汇选择;2)语音的韵律特征;3)语音的短时特征,例如频谱和共振峰。当语言层面固定时,韵律信息和短时因素是关系到说话人个性的相关因素。因而语音合成主要需要解决的问题为,从文本信息重建其他的所有信息。
4.虽然现实生活中语音合成系统有着广泛的应用,但是目前很多因素限制着语音合成在实际中的应用。例如,自回归语音合成模型需要的训练和推理时间较长,而基于注意力机制的并行语音合成模型的时间空间复杂度与序列长度程二次方关系。
技术实现要素:
5.本技术的目的在于解决传统并行语音合成声学模型时间、空间复杂度较高的问题。
6.为实现上述目的,本技术提供了一种基于线性自注意力的语音合成方法及系统。
7.第一方面,本技术实施例提供的一种基于线性自注意力的语音合成方法,所述方法包括:根据音频进行处理,获得对应文本的音素序列;根据所述音素序列通过神经网络编码器得到第一文本特征,所述神经网络编码器用于对所述音素序列进行线性自注意力计算和乘性位置编码以得到第一文本特征序列;根据所述第一文本特征序列通过时长预测模型扩增得到第二文本特征序列;根据所述第二文本特征序列通过神经网络解码器解码得到对应的梅尔谱特征序列;根据所述梅尔谱特征通过神经网络声码器得到转换后的语音。
8.作为一种可以实现的实施方式,所述方法还包括:提取训练集中的音频的对数梅尔谱特征序列;所述音频为带有标注文本的语音信号;获取所述音频对应的文本的音素序列;基于所述音素序列和梅尔谱特征序列联合训练所述神经网络编码器、时长预测模型、神经网络解码器和/或神经网络声码器,得到训练好的所述神经网络编码器、时长预测模型、神经网络解码器和或神经网络声码器。
9.作为一种可以实现的实施方式,所述提取训练集中的音频的梅尔谱特征序列,包括,将所述训练集中的音频进行预加重和分帧处理;对分帧后所述音频的每一帧进行加窗和快速傅里叶变换,得到所述音频的频谱和能量谱;对所述音频的能量谱计算通过梅尔滤波器的能量,并取对数,得到所述音频的对数梅尔谱特征序列。
10.作为一种可以实现的实施方式,所述输入神经网络编码器至少包括嵌入层和第一
全局自注意力神经网络;所述根据所述音素序列通过神经网络编码器得到第一文本特征序列,包括:将所述音素序列输入所述嵌入层,得到第一特征序列,所述第一特征序列的长度等于音素序列长度;将所述第一特征序列通过所述第一全局自注意力神经网络,得到所述第一文本特征序列。
11.作为一种可以实现的实施方式,所述全局自注意力神经网络至少包括第一线性自注意力模块;所述将所述第一特征序列通过所述全局自注意力神经网络,得到所述第一文本特征序列,包括:将所述第一特征序列经过线性自注意力模块,采用多头自注意力,对于每个头,先对所述第一特征序列进行线性投影,得到至少三个线性投影矩阵,然后对所述至少三个线性投影矩阵进行线性注意力操作,得到向量m,将所述向量m拼接并做线性投影,输出第二特征序列,所述第二特征序列的长度和所述音素序列的长度相同。
12.作为一种可以实现的实施方式,所述全局自注意力神经网络包括第一乘性位置编码模块,所述第一乘性位置编码模块用于对所述线性投影矩阵加入乘性位置信息得到第三特征序列。
13.作为一种可以实现的实施方式,所述全局自注意力神经网络包括第一前馈神经网络,所述第一前馈神经网络由两个线性投影组成,中间由修正线性单元作为激活函数进行连接,得到两个线性投影的权重矩阵,所述第一前馈神经网络输入为第三特征序列,输出为第一文本特征序列。
14.作为一种可以实现的实施方式,所述时长预测模型包括卷积结构,所述根据所述第一文本特征通过时长预测模型扩增得到第二文本特征,包括:通过对所述音素序列的每个音素的持续时长进行预测,并对所述第一文本特征序列进行扩增,得到得到所述第二文本特征序列;所述第二文本特征序列与所述梅尔谱序列长度相同。
15.第二方面,本技术实施例提供一种基于线性自注意力的语音合成系统,所述系统包括:信号处理模块,用于根据音频进行处理,获得对应文本的音素序列;神经网络编码器,用于根据所述音素序列得到第一文本特征;所述神经网络编码器包括线性自注意力模块和乘性位置编码模块;时长预测模型,用于根据所述第一文本特征扩增得到第二文本特征;神经网络解码器,用于根据所述第二文本特征得到对应的梅尔谱特征序列;所述神经网络解码器包括线性自注意力模块和乘性位置编码模块;神经网络声码器,用于根据所述梅尔谱特征得到转换后的语音。
16.第三方面,本技术实施例提供一种电子设备,包括存储器和处理器;所述处理器用于执行所述存储器所存储的计算机执行指令,所述处理器运行所述计算机执行指令执行上述任意一项所述方法。
17.第四方面,本技术实施例提供一种存储介质,包括可读存储介质和存储在所述可读存储介质中的计算机程序,所述计算机程序用于执行上述任意一项所述方法。
18.本技术提供一种基于线性自注意力的语音合成方法和系统。该方法以音素序列为输入,通过自注意力机制对特征间的依赖关系建模,以线性的时间、空间复杂度输出梅尔谱,输入神经网络声码器得到语音。该方法解决了传统并行语音合成声学模型时间、空间复杂度较高的问题。
19.本技术使用线性注意力机制,降低了并行语音合成声学模型的时间、空间复杂度。
附图说明
20.为了更清楚地说明本说明书披露的多个实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本说明书披露的多个实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
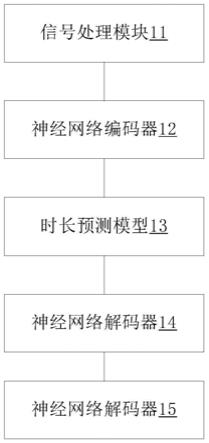
21.图1为本技术实施例提供的一种基于线性自注意力的语音合成系统的架构图;
22.图2为本技术本技术实施例提供的一种基于线性自注意力的语音合成方法的模型训练流程图;
23.图3为本技术本技术实施例提供的一种基于线性自注意力的语音合成方法的流程图;
24.图4为本技术本技术实施例提供的一种电子设备示意图。
具体实施方式
25.下面通过附图和实施例,对本技术的技术方案做进一步的详细描述。
26.本技术公开了一种基于端到端语音合成系统和方法,如图1所示,该系统包括:信号处理模块11、神经网络编码器12、时长预测模型13、神经网络解码器14和神经网络神经网络声码器15。
27.其中,信号处理模块11用于对待识别的音频进行进行处理,得到待转换音频的音素序列。
28.神经网络编码器12用于将音素序列编码为文本特征序列,记为第一文本特征。包括线性自注意力模块和乘性位置编码模块模块。
29.在一些可以实现的实施方式中,神经网络编码器12包括前端的嵌入层和后端的第一全局自注意力神经网络。
30.第一全局自注意力神经网络包括第一线性自注意力模块、第一乘性位置编码模块和第一前馈神经网络。
31.神经网络编码器12的输入是音素序列x=[x1,x2,
…
,x
n
],其中n为自然数,x
n
为第n个音素;神经网络编码器12的前端嵌入层根据输入的音素序列x,输出256维特征序列c1=[c1,c2,
…
,c
t
],其中t为自然数,c
t
为第t个特征元素;特征序列c的长度等于音素序列x的长度。神经网络编码器12的后端有4层全局自注意力神经网络,根据特征序列c输出256维特征序列h1=[h1,h2,
…
,h
t
],其中t为自然数,h
t
为第t个特征元素;特征序列h1的长度和全局自注意力神经网络输出的序列长度相同。
[0032]
时长预测模型13用于对每个音素的持续时长进行预测,并对文本特征序列h1=[h1,h2,
…
,h
t
]进行扩增,得到特征序列c2=[c
′1,c
′2,
…
,c
′
t
],使其与梅尔谱序列长度相同。
[0033]
神经网络解码器14用于将经过扩增的文本特征序列c2=[c
′1,c
′2,
…
,c
′
t
]转换为梅尔谱序列,包括线性自注意力模块和乘性位置解码模块。
[0034]
神经网络解码器14包括4层全注意力神经网络和前向计算模块。输入256维特征序列c2=[c
′1,c
′2,
…
,c
′
t
]。后端有4层全局自注意力神经网络,输出256维特征序列h2=[h
′1,h
′2,
…
,h
′
t
],特征序列的长度和梅尔谱序列长度相同。
[0035]
神经网络神经网络声码器15包括基于转置卷积神经网络、带有残差模块的卷积模块的生成器和基于卷积神经网络的判别器,将转换后的特征序列h2=[h
′1,h
′2,
…
,h
′
t
]经过神经网络声码器15得到转换后的语音。
[0036]
本技术公开了一种基于线性自注意力的语音合成方法,基于文本,生成目标说话人的谱特征,再利用谱特征经过神经网络声码器15生成转换后的语音,且模型的复杂度与语音长度程线性关系。方法包括:对文本进行处理,得对数梅尔谱特征序列和音素序列数据对;将音素序列经过包含线性自注意力模块和乘性位置编码模块的神经网络编码器12得到文本特征;利用音素序列,经过时长预测模型13得到扩增过的文本特征;将扩增过的文本特征经过包含线性自注意力模块和乘性位置编码模块的神经网络解码器14得到转换后的梅尔谱特征序列;将转换后的梅尔谱特征序列经过神经网络声码器15得到转换后的语音。
[0037]
如图2所示,在执行本技术的方法之前首先建立带有标注的音频训练集,提取相应的梅尔谱特征,基于训练集训练语音合成系统的神经网络编码器12、时长预测模型13、神经网络解码器14和神经网络声码器15。
[0038]
在一些可以实现的实施方式中,上述训练过程具体包括:
[0039]
步骤101)对音频训练集中的音频进行预加重,提升高频部分;
[0040]
步骤102)对预加重后音频进行分帧,示例性地,可以将预加重后音频分帧为每帧25毫秒,帧移10毫秒;
[0041]
步骤103)对每一帧进行加窗,窗函数为汉明窗;
[0042]
步骤104)对加窗后每一帧进行快速傅里叶变换得到每一帧对应的频谱,进一步得到每一帧的能量谱;
[0043]
步骤105)对每一帧的能量谱计算通过梅尔滤波器的能量,并取对数,得到对数梅尔谱序列,示例性地,梅尔滤波器的个数可以为80,得到80维的对数梅尔谱特征序列。
[0044]
步骤106)根据该音频对应的标注文本得到对应的音素序列,获得音素序列和对数梅尔谱特征序列的数据对。
[0045]
根据音素序列和对应的对数梅尔谱特征序列,训练神经网络编码器12、时长预测模型13、神经网络解码器14和神经网络声码器15。
[0046]
基于上述训练好的神经网络编码器12、时长预测模型13、神经网络解码器14和神经网络神经网络声码器15,执行本技术的方法,如图3所示,包括如下步骤:
[0047]
s201,对该音频对应的标注文本进行处理,转换为音素序列,得到对应文本的音素序列x=[x1,x2,
…
,x
n
]。
[0048]
s202,利用步骤s201得到的音素序列,经过包含线性自注意力模块和乘性位置编码模块的神经网络编码器12得到第一文本特征系列。
[0049]
在一些可以实现的实施方式中,神经网络编码器12的输入是音素序列包括前端的嵌入层,和后端的4层第一全局自注意力神经网络;第一全局自注意力神经网络包括第一自注意力子层、第一乘性位置编码模块和第一前馈神经网络。神经网络编码器12输出的特征序列的长度和第一全局自注意力神经网络输出的序列长度相同。
[0050]
在一些可以实现的实施方式中,将音素序列x=[x1,x2,
…
,x
n
]输入神经网络编码器12,经过前端的嵌入层,得到256维度的特征序列c1=[c1,c2,
…
,c
t
],记为第一特征序列;特征序列c1的长度等于音素序列x长度。后端的4层全局注意力神经网络,根据特征序列c1=
[c1,c2,
…
,c
t
]输出为256维特征序列h1=[h1,h2,
…
,h
t
],特征序列h1=[h1,h2,
…
,h
t
]的长度和梅尔谱序列的长度相同。
[0051]
在一些可以实现的实施方式中,第一全局注意力神经网络包括第一线性自注意力模块,第一线性自注意力模块采用多头自注意力,对于每个头,先对输入的256维特征序列h1=[h1,h2,
…
,h
t
]的矩阵进行线性投影,得到三个矩阵q、k、v,然后对这三个矩阵进行线性注意力(linear attention)操作,得到向量m,将所有头的向量m拼接并做线性投影得到该子层的输出,拼接后的输出序列记为第二特征序列。向量m由下式计算:
[0052][0053]
其中为elu激活函数。
[0054]
在一些可以实现的实施方式中,第一全局注意力神经网络包括第一乘性位置编码模块,用于对q、k矩阵进行乘性位置编码,加入乘性位置信息,输出第三特征序列。
[0055]
定义q为维度为n*2的矩阵,q
m
=(q
m,1
,q
m,2
)为q中绝对位置为m的二维向量,对q中每个位置的二维向量做如下操作以加入乘性位置信息:
[0056][0057]
对q、k矩阵中每相邻的两列都进行乘性位置编码操作以引入位置信息。示例性地,矩阵q、k维度分别为n*256,对矩阵q的第一、第二列,矩阵k的第一、第二列使用相同的θ1,对矩阵q的第三、第四列,矩阵k的第三、第四列使用相同的θ2,以此类推,每个乘性位置编码模块有128个可学习的θ角,这128个可学习的θ角在训练中完成学习。
[0058]
在一些可以实现的实施方式中,第一全局注意力神经网络包括第一前馈神经网络,前馈神经网络由两个线性投影组成,中间由修正线性单元作为激活函数进行连接,如下:
[0059]
ffn(x)=max(xw1+b1,0)w2+b2ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0060]
式(3)中ffn(
·
)为修正线性单元,w1、w2为两个线性投影的权重矩阵,维度分别为d
×
d
f
和d
f
×
d;b1、b2为偏置向量。x为线性注意力层输出的特征,d为线性注意力层输出的特征的维度,d
f
为前馈神经网络的隐层维度。最终的计算将输出的256维的第一文本特征序列h1=[h1,h2,
…
,h
t
]。
[0061]
s203,根据音素序列,通过时长预测模型13对每个音素的持续时长进行预测,并对文本特征序列h1进行扩增,得到特征序列c2=[c
′1,c
′2,
…
,c
′
t
],记为第二文本特征序列;使其与梅尔谱序列长度相同。该时长预测模型13包括卷积结构。
[0062]
需要理解的是,编码器12输出的编码过的文本特征序列h1,其长度和音素序列长度相等,扩增就是直接复制,持续时长由语音中每个音素的实际持续长度得到。
[0063]
在一些可以实现的实施方式中,步骤3)具体包括:根据神经网络编码器12得到的h1=[h1,h2,
…
,h
t
],经过一个包含卷积结构的时长预测模型13,得到每个音素的预测持续帧数,再根据时长扩增每个音素对应的文本特征序列,得到扩增过的文本特征矩阵c2=[c
′1,c
′2,
…
,c
′
t
]。
[0064]
s204,将步骤s203中提取的扩增过的文本特征序列c2=[c
′1,c
′2,
…
,c
′
t
]经过神
经网络解码器14解码得到转换后的梅尔谱特征序列。
[0065]
在一些可以实现的实施方式中,步骤s204具体包括:根据步骤s203得到的经过扩增的文本特征矩阵c2=[c
′1,c
′2,
…
,c
′
t
],经过神经网络解码器14解码,神经网络解码器14包括后端的4层第二全局注意力神经网络,输出256维文本特征序列,该文本特征序列的长度和梅尔谱序列长度相同。
[0066]
在一些可以实现的实施方式中,第二全局注意力神经网络包括第二线性自注意力模块,第二线性自注意力模块采用多头自注意力,对于每个头,先对输入文本特征矩阵c2=[c
′1,c
′2,
…
,c
′
t
]进行线性投影,得到三个矩阵q'、k'、v',然后对这三个矩阵进行线性注意力(linear attention)操作,得到向量m',将所有头的m'拼接并做线性投影得到该子层的输出。m'由式(1)的公式计算获得,此处不再赘述。
[0067]
在一些可以实现的实施方式中,第二全局注意力神经网络包括第二前馈神经网络,第二前馈神经网络由两个线性投影组成,中间由修正线性单元作为激活函数进行连接,根据公式(3)计算,此处不再赘述。
[0068]
最终的计算将输出的256维的文本特征序列,经过第二全局注意力神经网络最后的线性映射层得到80维的梅尔谱特征序列。
[0069]
s205,将该梅尔谱特征序列经过神经网络声码器15得到转换后的语音。
[0070]
在一些可以实现的实施方式中,步骤s205具体包括:根据步骤s204得到的梅尔谱特征序列作为神经网络声码器15的输入,通过包括转置卷积和残差连接层等神经子网络的神经网络声码器15得到最终的合成语音。
[0071]
本技术实施例提供一种电子装置1100,如图4所示,包括处理器1101和存储器1102;处理器1101用于执行所述存储器1102所存储的计算机执行指令,处理器1101运行计算机执行指令执行上述任意实施例所述的基于线性自注意力的语音合成方法。
[0072]
本技术实施例提供一种存储介质1103,包括可读存储介质和存储在所述可读存储介质中的计算机程序,所述计算机程序用于实现上述任意一实施例所述的所述的基于线性自注意力的语音合成方法。
[0073]
本领域普通技术人员应该还可以进一步意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,为了清楚地说明硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以硬件还是软件方式来执轨道,取决于技术方案的特定应用和设计约束条件。本领域普通技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本技术的范围。
[0074]
结合本文中所公开的实施例描述的方法或算法的步骤可以用硬件、处理器执轨道的软件模块,或者二者的结合来实施。软件模块可以置于随机存储器(ram)、内存、只读存储器(rom)、电可编程rom、电可擦除可编程rom、寄存器、硬盘、可移动磁盘、cd
‑
rom、或技术领域内所公知的任意其它形式的存储介质中。
[0075]
以上具体实施方式,对本技术的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上仅为本技术的具体实施方式而已,并不用于限定本技术的保护范围,凡在本技术的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本技术的保护范围之内。