(4), 386
‑
390, 2010)。进一步地,还有学者提出了在多项式中用语言清晰度c
50
代替混响时间t
60
进行教室语言可懂度的预测(j.s. bradley and h. sato, the intelligibility of speech in elementary school classrooms, j acoust soc am, 123 (4), 2078
‑
2086, 2008)。但需要指出的是服务机器人的工作场所和教室的声环境不尽相同,且有些应用中,为了增加交互的趣味性,服务机器人发声的语调和教师正常授课的语调有明显差异,并不能将包括教室在内的现有语言可懂度的预测模型直接用于服务机器人的发声系统,而需要专门针对服务机器人的发声内容和声场景建立专门的语言可懂度模型。
技术实现要素:
5.发明目的:为了克服现有技术中存在的不足,本发明提供一种基于声环境感知的服务机器人语音输出增益获取方法,通过考虑周边环境反射以及背景噪声的影响,快速获取机器人语音输出时的合适增益。
6.技术方案:为实现上述目的,本发明采用的技术方案为:一种基于声环境感知的服务机器人语音输出增益获取方法,通过实际测量客观声学参量,结合预先建立的专用语言可懂度预测模型,根据需要的语言可懂度快速获取合适的语音输出增益,具体包括以下步骤:步骤1,确定语言可懂度指标。
7.步骤2,测量单位幅度信号驱动时,机器人发声系统在目标位置处产生的语声级零敏度ss。
8.步骤3,获取服务机器人工作场所的混响时间t
60
。
9.步骤4,使用机器人自身的传声器获取所在场景的背景噪声级nl。
10.步骤5,根据步骤1确定的语言可懂度指标、步骤3得到的混响时间t
60
、步骤4得到的语音背景噪声级nl代入语言可懂度预测模型得到目标位置的期望语声级spl。
11.步骤6,根据步骤2得到的语声级零敏度ss和步骤5得到的期望语声级spl得到语音输出增益。
12.gai=spl
‑
ss其中,gai表示语音输出增益。
13.优选的:步骤5中语言可懂度预测模型为:si = a
ꢀ×ꢀ
(spl
‑
nl) + b
ꢀ×ꢀ
(spl
‑
nl)
2 + c
ꢀ×ꢀ
t
60 + d (%)式中,si为语言可懂度指标,spl为期望语声级,nl为背景噪声级,t
60
为混响时间,a、b、c、d为常系数。
14.优选的:步骤3中获取服务机器人工作场所的混响时间t
60
的方法,混响时间通过调研获取,或者用仪器测量,或者由机器人自身的扬声器发声,或者由机器人驱动外部声源发声,机器人自身的传声器接收测量。
15.优选的:机器人自身的扬声器发声时,将机器人自身的传声器通过线缆延长移动至测量点或外接传声器至机器人测量。
16.优选的:目标位置所在的区域为距离机器人发声系统的水平距离为0.8
‑
1.2 m,垂直高度为1.3
‑
1.7m的区域。
17.本发明相比现有技术,具有以下有益效果:
本发明可以考虑周边环境声反射以及背景噪声的影响,快速获得合适的语音输出增益,同时获得的语音输出增益更适用于实际应用。
附图说明
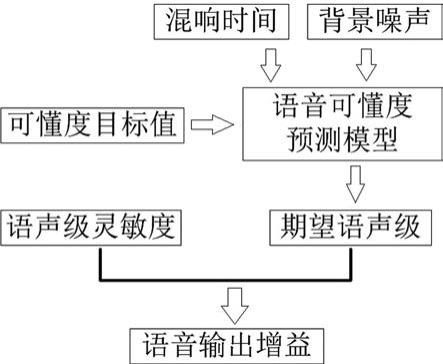
18.图1为本发明的原理框图。
具体实施方式
19.下面结合附图和具体实施例,进一步阐明本发明,应理解这些实例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本技术所附权利要求所限定的范围。
20.一种基于声环境感知的服务机器人语音输出增益获取方法,如图1所示,包括以下步骤:步骤1,确定语言可懂度指标,语言可懂度指标可根据实际需要进行确定。
21.步骤2,测量单位幅度信号驱动时,机器人发声系统在目标位置处产生的语声级零敏度ss(归一化单位为db)。目标位置所在的区域为距离机器人发声系统的水平距离为0.8
‑
1.2 m,垂直高度为1.3
‑
1.7m的区域。
22.步骤3,调研或测量服务机器人工作场所的混响时间t
60
。
23.混响时间可以通过调研获取,或者用仪器测量,或者由机器人自身的扬声器发声,或者由机器人驱动外部声源发声,机器人自身的传声器接收测量。机器人自身的扬声器发声时,将机器人自身的传声器通过线缆延长移动至测量点或外接传声器至机器人测量。
24.步骤4,使用机器人自身的传声器获取所在场景的背景噪声级nl。
25.步骤5,根据步骤1确定的语言可懂度指标、步骤3得到的混响时间t
60
、步骤4得到的语音背景噪声级nl代入语言可懂度预测模型得到目标位置的期望语声级spl。
26.语言可懂度预测模型为:si = a
ꢀ×ꢀ
(spl
‑
nl) + b
ꢀ×ꢀ
(spl
‑
nl)
2 + c
ꢀ×ꢀ
t
60 + d (%)式中,si为语言可懂度指标,spl为期望语声级,nl为背景噪声级,t
60
为混响时间,a、b、c、d为常系数,事先由大量的主观听音实验确定。
27.步骤6,根据步骤2得到的语声级零敏度ss和步骤5得到的期望语声级spl实时得出服务机器人的语音输出增益。
28.gai=spl
‑
ss其中,gai表示语音输出增益。
29.实例假设某服务机器人语音输出的目标区域为距其水平距离为1 m,垂直高度为1.5m处的某用户。针对该位置,语言可懂度预测模型为,si = 2.26
ꢀ×ꢀ
(spl
‑
nl)
ꢀ–
0.0888
×ꢀ
(spl
‑
nl)
2 + 13.9
×ꢀ
t
60 + 95(%)可以按以下步骤实施:(1)确定语言可懂度指标(语言可懂度的目标值)为95%。
30.(2)实际测得单位幅度信号驱动时,机器人发声系统在目标位置处产生的语声级零敏度ss为60 db。
31.(3)获取服务机器人工作场所的混响时间t
60
为 0.2 s。
32.(4)使用机器人自身的传声器测得工作场所的背景噪声级nl 为40 dba。
33.(5)将语言可懂度指标、测得的背景噪声级nl和混响时间t
60
代入语言可懂度预测模型,计算得到期望语声级spl为66.5 dba,将期望语声级spl减去语声级灵敏度得到语言输出增益为6.5 db。
34.如果不考虑背景噪声和环境混响,要实现95%的语言可懂度,期望语言级spl仅要求达到25.5 dba,对应的语言输出增益为
‑
34.5 db,比实际需求降低了41 db。
35.本发明在机器人所处复杂声环境中时可考虑反射声和背景噪声的影响,有效提升机器人发声时的语音可懂度,并降低对周边环境的影响。
36.以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。