1.使用具有一个或多个固态纳米孔的系统和用于精确和准确定量的数学方法确定样品的特定多核苷酸序列的分数丰度的方法。
背景技术:
2.通过确定样品中存在的组分的相对丰度来表征液体样品可以为许多科学领域和应用提供有价值的信息。例如,循环细胞游离dna中的点突变的相对丰度可用于诊断或监测患者中癌症的进展。作为另一个实例,确定遗传修饰生物体(gmo)的转基因序列与基因组dna(例如从种子集合获得的)内的非gmo参照序列的分数量对于管理和经济原因是重要的。
3.存在一些用于灵敏检测样品中目标分析物的分数量的方法,然而,这些方法通常是昂贵且耗时的,或具有其他限制。例如,定量实时pcr(qpcr)测定仍然是用于确定靶核酸序列相对于测试样品内的非变体参照序列的相对量的标准方法。然而,qpcr的定量性能受到每个样品和每个扩增子的扩增效率的变异性的限制。影响扩增效率的因素包括来自样品基质以及提取试剂本身的抑制剂和伴随污染物。这些因素因样品和制备而异,但也在于它们影响一个序列与另一个序列相比的扩增效率的程度。目标扩增子相对于参照扩增子的扩增效率的轻微的可变差异限制了qpcr解析》1.5倍的量差异。此外,扩增反应需要专门的试剂组并且必须适当地储存,并且可能是耗时的并且对反应条件敏感。
4.纳米孔装置的使用已经成为用于单分子鉴定的敏感工具,其中单个分子在施加的电压下通过纳米孔移位时鉴定。纳米孔装置适合于现场应用,并且对于日常使用情况、人类健康、农业或其他任何方面而言足够便宜和高效。然而,来自纳米孔的数据的使用可能遭受可影响样品中分析物的定量估计的确定的误差,使得可靠地使用该数据是不可行的。
5.因此,所需要的是确定样品中的目标分析物与参照分析物相比的分数丰度的改进方法,其是通用的、经济的且易于使用的。
技术实现要素:
6.根据一些实施方案,本文提供了使用纳米孔装置确定混合的未知样品中目标分析物的真实相对丰度的改进估计值的方法,包括在纳米孔装置中施加跨纳米孔的电压以单独地针对以下各项产生可检测的电子特征和诱导带电分析物通过所述纳米孔的移位:对照样品,其包含已知的目标分析物与参照分析物的相对丰度,以及包含所述目标分析物和所述参照分析物的混合未知样品,其中所述样品中所述目标分析物的相对丰度待确定;对于每个样品产生通过所述目标分析物或所述参照分析物移位通过所述纳米孔产生的多个事件特征;从所述多个事件特征中鉴定与所述目标分析物相关的第一事件特征的量和与所述参照分析物相关的第二事件特征的量,以确定每个样品的第一和第二事件特征的检测相对丰度;和使用所述对照样品中所述第一和第二事件特征的检测相对丰度来调整所述混合未知样品中所述第一和第二事件特征的检测相对丰度,以校正检测相对丰度的误差,从而确定在所述混合未知样品中所述目标分析物的真实相对丰度的改进估计值。在一些实施方案
中,样品是液体样品。
7.在一些实施方案中,对照样品是包含所述目标分析物但不包含所述参照分析物的目标对照样品。在一些实施方案中,对照样品是参照对照样品,其包含所述参照分析物,但不包含所述目标分析物。
8.在一些实施方案中,使用纳米孔装置确定混合未知样品中的目标分析物的真实相对丰度的改进估计值的方法还包括向纳米孔装置施加电压以对于包含所述目标分析物但不包含所述参照分析物的目标对照样品诱导带电分析物通过纳米孔传感器的移位。
9.在一些实施方案中,所述未知样品中所述第一和第二事件特征的所述检测相对丰度的调整包括使用所述目标对照样品和所述参照对照样品中的所述第一和第二事件特征的检测相对丰度以校正检测相对丰度的所述误差。在一些实施方案中,误差包括所述目标分析物的假阳性或假阴性检测误差。
10.在一些实施方案中,使用纳米孔装置确定混合未知样品中目标分析物的真实相对丰度的改进估计值的方法还包括向纳米孔装置施加电压以对于包含所述目标分析物和所述参照分析物的混合对照样品诱导带电分析物通过纳米孔传感器的移位,其中所述目标分析物和所述参照分析物的相对丰度是已知的。
11.在一些实施方案中,所述未知样品中所述第一和第二事件特征的所述检测相对丰度的调整包括使用所述目标对照样品、所述参照对照样品和所述混合对照样品中所述第一和第二事件特征的检测相对丰度以校正检测相对丰度的所述误差。
12.在一些实施方案中,误差包括假阳性目标分析物检测误差、假阴性目标分析物检测误差、所述目标分析物和所述参照分析物之间的捕获率常数差异或其任何组合。
13.在一些实施方案中,对照样品是包含所述目标分析物和所述参照分析物的混合对照样品,其中所述目标分析物和所述参照分析物的相对丰度是已知的。在一些实施方案中,误差包括所述目标分析物和所述参照分析物之间的捕获率常数差异。
14.在一些实施方案中,混合对照样品包含的所述目标分析物与所述参照分析物的相对丰度相对于所述混合的未知样品相差不超过1.2倍,1.5倍,2倍,5倍或10倍。
15.在一些实施方案中,真实相对丰度的估计值是所述混合未知样品中所述目标分析物与所述参照分析物的真实比率的估计值。在一些实施方案中,真实比率的估计值通过确定,其中参数ρ是可以补偿假阳性检测误差、假阴性检测误差或者两者的比率的估计值,并且其中参数α可用于补偿所述目标分析物和所述参照分析物之间的捕获率常数差异。在一些实施方案中,参数α是参照分析物捕获率除以目标分析物捕获率的比率的估计值。
16.在一些实施方案中,真实相对丰度的估计值是所述混合未知样品中所述参照分析物和所述目标分析物的群体中的所述目标分析物的真实分数的估计值。在一些实施方案中,真实分数的估计值通过确定,其中参数ρ是可以补偿假阳性检测误差、假阴性检测误差或两者的比率的估计值,并且其中参数α可用于补偿所述目标分析物和所述参照分析物之间的捕获率常数差异。在一些实施方案中,参数α是参照分析物捕获率除以目标分析物捕获率的比率的估计值。
17.在一些实施方案中,参数并且在一些实施方案中,如果使用所述对照样品,则参数q
targ
是在所述目标对照样品中观察到的所述第一事件特征的分数,或者如果没有使用目标对照样品,则q
targ
=1。在一些实施方案中,如果使用所述参照对照样品,则参数q
ref
是在所述参照对照样品中观察到的所述第一事件特征的分数,或者如果不使用参照对照样品,则参数q
ref
=0。在一些实施方案中,参数q
x:y
,是在所述混合对照样品中观察到的所述第一事件特征的分数,并且其中是混合对照样品中目标分析物(x)与参照分析物(y)的已知比率(如果使用所述对照样品),或者如果不使用混合对照样品,则α=1。在一些实施方案中,参数q
mix
是在所述混合未知样品中观察到的所述第一事件特征的分数。
18.在一些实施方案中,通过核酸扩增制备未知或对照样品。在一些实施方案中,未知或对照样品不通过核酸扩增制备。在一些实施方案中,样品纯化以基本上由参照和目标分子组成。在一些实施方案中,样品未经纯化。
19.在一些实施方案中,所述混合未知样品中所述参照分析物的量或浓度是已知的。在一些实施方案中,使用纳米孔装置确定混合未知样品中目标分析物的真实相对丰度的改进估计值的方法还包括使用所述混合未知样品中所述目标分析物与所述参照分析物的真实相对丰度的所述估计值和所述混合未知样品中所述参照分析物的所述已知量或浓度来确定所述混合未知样品中所述目标分析物的绝对量或浓度的估计值。在相关的实施方案中,所述目标分析物的所述绝对量或浓度可以使用源自一个或多个纳米孔装置的多个纳米孔的信息来确定。
20.在一些实施方案中,根据定义的阈值鉴定与所述目标分析物相关的第一事件特征的量和与所述参照分析物相关的所述第二事件特征的量。在一些实施方案中,使用纳米孔装置确定混合未知样品中目标分析物的真实相对丰度的改进估计值的方法还包括使用q检验、支持向量机或期望最大化算法优化所述阈值以提高所述参照分析物和/或所述目标分析物的检测准确度。在一些实施方案中,使用来自包含已知量的目标分析物和参照分析物的对照样品的电子特征来训练支持向量机。
21.在一些实施方案中,所定义的阈值是选自以下各项的事件特征的一个或多个特征的函数:事件持续时间、最大δg、中值δg、平均δg、事件特征的标准偏差、低于50hz的事件的噪声功率的平均值或中值、所述事件特征中的独特模式、事件的面积或其任何组合。
22.在一些实施方案中,使用q检验、支持向量机或期望最大化算法来执行所述混合未知样品中所述第一和第二事件特征的所述检测相对丰度的调整以校正所述检测相对丰度的误差。
23.在一些实施方案中,目标分析物和所述参照分析物各自包含多核苷酸。在一些实施方案中,目标分析物多核苷酸和所述参照分析物多核苷酸具有不同的长度。在一些实施方案中,长度相差至少10个核苷酸,至少20个核苷酸,至少50个核苷酸,至少100个核苷酸,至少150个核苷酸或至少200个核苷酸。
24.在一些实施方案中,使用纳米孔装置确定混合未知样品中目标分析物的真实相对丰度的改进估计值的方法还包括使所述对照或未知样品与结合第一有效负载的第一探针
接触,其中所述第一探针配置成与所述第一分析物特异性结合。在一些实施方案中,使用纳米孔装置确定混合未知样品中目标分析物的真实相对丰度的改进估计值的方法还包括使所述对照或未知样品与结合第二有效负载的第二探针接触,其中所述第二探针配置成特异性结合所述第二分析物。
25.在一些实施方案中,目标分析物与遗传修饰的生物体相关。在一些实施方案中,目标分析物包含与患者中癌症的存在或不存在相关的标志物。
26.本文还提供一种确定样品中目标分析物的相对量的方法,包括在纳米孔系统中单独地运行以下各项:包含参照分析物且不含目标分析物的第一对照样品,包含目标分析物并且不含参照分析物的第二对照样品,包含已知相对丰度的所述目标分析物和所述参照分析物的第三对照样品,以及包含未知相对丰度的所述目标分析物和所述参照分析物的实验样品;对于每个样品检测与参照分析物相关的第一事件特征的量和与目标分析物相关的第二事件特征的量;并且比较来自所述实验样品的所述第一和第二事件特征的量的相对丰度与来自所述第一对照样品、所述第二对照样品和所述第三对照样品中每一个的所述第一和第二事件特征的量的相对丰度以确定所述实验样品中所述参照分析物和所述目标分析物的真实相对丰度的估计值。
27.在一些实施方案中,事件特征包括由所述参照分析物通过所述纳米孔移位诱导的电信号。
28.在一些实施方案中,目标分析物和所述参照分析物各自包含多核苷酸。在一些实施方案中,参照分析物和所述目标分析物通过长度区分。
29.在一些实施方案中,参照分析物和所述目标分析物各自与包含有效负载的序列特异性探针结合,以利于所述参照分析物与所述目标分析物在所述纳米孔装置中的区分。
30.在一些实施方案中,相对丰度是所述目标分析物与所述样品中目标分析物和参照分析物的总群体相比的分数量。
31.本文还提供了确定未知样品中目标分析物的相对丰度的方法,包括提供包含多个参照分析物和多个目标分析物的未知样品;将所述未知样品加载到纳米孔装置的第一室中,所述纳米孔装置包括设置在所述第一室和第二室之间的纳米孔;跨所述纳米孔施加电压以使所述参照分析物和所述目标分析物通过所述纳米孔从所述第一室移动到所述第二室;检测各自与所述参照分析物通过纳米孔的移位相关的第一电信号的数量;检测各自与所述目标分析物通过纳米孔的移位相关的第二电信号的数量;和使用考虑至少一个与所述电信号相对丰度相关的误差的参照值将检测的第一电信号的数量和检测的第二电信号的数量的相对丰度转换为所述未知样品中所述目标分析物的真实相对丰度的估计值。
32.在一些实施方案中,参照值从包含已知量的目标分析物和参照分析物的混合对照样品确定的所述第一电信号的分数丰度确定。在一些实施方案中,参照值从包含已知量的目标分析物和参照分析物的混合对照样品确定的所述第一电信号的分数丰度确定。在一些实施方案中,参照值从包含已知量的目标分析物和参照分析物的混合对照样品确定的所述第一电信号的分数丰度确定。
33.在一些实施方案中,混合对照样品、所述目标对照样品或所述参照对照样品与在来自所述未知样品的所述第一和第二电信号的所述检测期间所述纳米孔装置中的条件基本相同的条件下,在所述纳米孔装置中运行。
34.在一些实施方案中,纳米孔装置包括将装置的内部空间分隔成第一室和第二室的膜,其中所述膜包含所述纳米孔,其中所述第一室和所述第二室通过所述纳米孔流体连通,并且其中所述装置包括在每个室中用于施加跨所述纳米孔的电压的电极。在一些实施方案中,电极配置成监测通过所述纳米孔的电流。在一些实施方案中,电极连接到电源。
35.在一些实施方案中,本文提供的方法通过考虑假阳性或假阴性检测误差或所述目标分析物和参照分析物之间的捕获率常数差异提高了混合未知样品中目标分析物的分数丰度的估计的准确度。在一些实施方案中,运行一系列对照以提高分数丰度估计的准确度,包括仅参照对照以考虑假阳性目标分析物检测误差、仅目标对照以考虑假阴性目标分析物检测误差和一个或多个混合对照样品以考虑目标分析物和参照分析物之间的捕获率常数差异。
36.在一些实施方案中,混合未知样品中目标分析物与参照分析物之间的捕获率是相对一致的,使得不需要使用混合对照来改进相对丰度的估计。在一些实施方案中,混合样品中目标分析物与参照分析物之间的相对捕获率是已知的,使得校正项可以应用于来自混合未知样品的数据以补偿该差异从而改进分数丰度的估计而无需运行混合对照样品。在一些实施方案中,来自使用与混合未知样品中相同的目标分析物和参照分析物种类在基本相同的纳米孔条件下运行的混合对照样品的数据用于改进分数丰度的估计而不实际运行混合对照样品作为方法的部分。
37.在一些实施方案中,确定阈值使得来自混合未知样品的假阳性值是可忽略的,并且不需要使用仅参照对照来改进相对丰度的估计。在一些实施方案中,来自混合样品的假阳性值是已知的,使得校正项可以应用于来自混合未知样品的数据以补偿假阳性误差从而改进分数丰度的估计而不运行仅参照对照样品。在一些实施方案中,来自使用与混合未知样品中相同的参照分析物种类在基本上相同的纳米孔条件下运行的仅参照对照样品的数据用于改进分数丰度的估计而不实际运行仅参照对照作为方法的部分。
38.在一些实施方案中,确定阈值使得来自混合未知样品的假阴性值是可忽略的,并且不需要使用仅目标对照来改进相对丰度的估计。在一些实施方案中,来自混合样品的假阴性值是已知的,使得校正项可以应用于来自混合未知样品的数据以补偿假阴性误差从而改进分数丰度的估计而不运行仅目标对照样品。在一些实施方案中,来自使用与混合未知样品中相同的目标分析物种类在基本上相同的纳米孔条件下运行的仅目标对照样品的数据用于改进分数丰度的估计而不实际运行仅目标对照作为方法的部分。
39.在一些实施方案中,本文提供了一种确定混合样品中目标分析物相对于参照分析物的相对丰度的估计值的方法,包括向纳米孔装置施加电压以单独地对于以下各项诱导带电分析物通过纳米孔传感器的移位:包含已知相对丰度的目标分析物与参照分析物的混合对照样品,以及包含所述目标分析物和所述参照分析物的混合未知样品,其中所述目标分析物与所述参照分析物的相对丰度是未知的;对于每个样品检测与所述参照分析物相关的第一事件特征的量和与目标分析物相关的第二事件特征的量;和通过使用所述混合未知样品中所述第一和第二事件特征的检测相对丰度和所述混合对照样品中所述目标分析物与所述参照分析物的真实相对丰度调整来自所述混合未知样品的所述第一和第二事件特征的检测相对丰度,确定所述混合未知样品中所述目标分析物与所述参照分析物的真实相对丰度的估计值。
40.在一些实施方案中,本文提供了确定混合样品中目标分析物与参照分析物的相对丰度的估计值的方法,包括向纳米孔装置施加电压以单独对于以下各项诱导带电分析物通过纳米孔传感器的移位:包含目标分析物但不包含参照分析物的目标对照样品,包含参照分析物但不包含目标分析物的参照对照样品,以及包含所述目标分析物和所述参照分析物的混合未知样品,其中所述目标分析物与所述参照分析物的相对丰度是未知的;对于每个样品检测与所述参照分析物相关的第一事件特征的量和与目标分析物相关的第二事件特征的量;和通过使用所述目标对照样品和所述参照对照样品中所述第一和第二事件特征的检测相对丰度调整所述混合未知样品中所述第一和第二事件特征的检测相对丰度,确定所述混合未知样品中所述目标分析物与所述参照分析物的真实相对丰度的估计值。在一些实施方案中,目标对照样品提供用于来自所述混合未知样品的目标分析物的假阴性检测的校正项。在一些实施方案中,参照对照样品提供用于所述混合未知样品中目标分析物的假阳性检测的校正项。
41.在一些实施方案中,本文提供了确定混合样品中目标分析物与参照分析物的相对丰度的估计值的方法,包括向纳米孔装置施加电压以单独对于以下各项诱导带电分析物通过纳米孔传感器的移位:包含已知相对丰度的目标分析物与参照分析物的混合对照样品,包含目标分析物但不包含参照分析物的目标对照样品,包含参照分析物但不包含目标分析物的参照对照样品,和包含所述目标分析物和所述参照分析物的混合未知样品,其中所述目标分析物与所述参照分析物的相对丰度是未知的;对于每个样品检测与所述参照分析物相关的第一事件特征的量和与目标分析物相关的第二事件特征的量;和通过使用所述目标对照样品和所述参照对照样品中所述第一和第二丰度的检测相对丰度以及所述混合对照样品中所述第一和第二事件特征的检测相对丰度和所述混合对照样品中所述目标分析物与所述参照分析物的真实相对丰度来调整来自所述混合未知样品的所述第一和第二事件特征的检测相对丰度,确定所述混合未知样品中所述目标分析物与所述参照分析物的真实相对丰度的估计值。
42.在一些实施方案中,确定混合样品中目标分析物与参照分析物的相对丰度的估计值的方法还包括向纳米孔装置施加电压以对于包含所述目标分析物但不包含所述参照分析物的目标对照样品诱导带电分析物通过纳米孔传感器的移位。
43.在一些实施方案中,确定混合样品中目标分析物与参照分析物的相对丰度的估计值的方法还包括向纳米孔装置施加电压以对于包含所述参照分析物但不包含所述目标分析物的参照对照样品诱导带电分析物通过纳米孔传感器的移位。确定所述混合未知样品中所述目标分析物与所述参照分析物的所述真实相对丰度的估计值的方法包括使用所述目标对照样品、所述参照对照样品和所述混合对照样品中所述第一和第二事件特征的检测相对丰度及所述混合对照样品中所述目标分析物与所述参照分析物的真实相对丰度调整所述混合未知样品中所述第一和第二事件特征的检测相对丰度。
44.在一些实施方案中,混合对照样品包含所述目标分析物与所述参照分析物的相对丰度,其相对于所述混合未知样品相差不超过1.2倍、1.5倍、2倍、5倍或10倍。
45.在一些实施方案中,相对丰度包括目标分析物:参照分析物的比率。在一些实施方案中,所述混合未知样品中目标分析物与所述参照分析物的真实比率的估计值通
过确定,其中参数ρ为可以补偿假阳性检测误差、假阴性检测误差或两者的比率的估计值,和其中参数α可用于补偿所述目标分析物和所述参照分析物之间的捕获率常数差异。在一些实施方案中,参数α是参照分析物捕获率除以目标分析物捕获率的比率的估计值。
46.在一些实施方案中,相对丰度包括所述目标分析物和所述参照分析物的群体中所述目标分析物的分数。在一些实施方案中,所述混合未知样品的所述参照分析物和所述目标分析物的群体中所述目标分析物的真实分数的估计值通过来确定,其中参数ρ是可以补偿假阳性检测误差、假阴性检测误差或两者的比率的估计值,并且其中参数α可以用于补偿所述目标分析物和所述参照分析物之间的捕获率常数差异。在一些实施方案中,参数α是参照分析物捕获率除以目标分析物捕获率的比率的估计值。
47.在一些实施方案中,本文提供了试剂盒,其包括包含已知相对丰度的目标分析物和参照分析物的对照样品;和用于在纳米孔装置中运行所述对照样品及包含所述参照分析物和所述目标分析物的未知样品以确定所述未知样品中所述参照分析物和所述目标分析物的相对丰度的说明书。
48.在一些实施方案中,本文提供了试剂盒,其包括包含目标分析物的第一对照样品,其中所述第一对照样品不含参照分析物;包含所述参照分析物的第二对照样品,其中所述第二对照样品不含所述目标分析物;包含已知相对丰度的所述目标分析物和所述参照分析物的第三对照样品;和用于在纳米孔装置中分别运行所述第一对照样品、所述第二对照样品、所述第三对照样品和包含所述参照分析物和所述目标分析物的未知样品以确定所述未知样品中所述参照分析物和所述目标分析物的相对丰度的说明书。
49.在一些实施方案中,本文提供了一种计算机执行的确定样品中目标分析物的真实分数丰度的估计值的方法,包括:从纳米孔传感器获得来自参照分析物对照或目标分析物对照的至少一个的数据,其中所述数据包括移位通过所述纳米孔的目标分析物或参照分析物的多个事件特征;鉴定事件特征的一个或多个特性以区分与目标分析物相关的那些事件特征和与参照分析物相关的那些事件特征;训练所述支持向量机以鉴定优化的阈值而区分所述第一事件与所述第二事件并且生成样品中所述参照分析物和所述目标分析物的真实相对丰度的估计值,其中所述训练包括使用选自参照对照样品、目标对照样品和混合对照样品的对照,并且其中训练包括使用已知混合样品的验证;并且使用所述训练的支持向量以从来自混合样品的在纳米孔装置上记录的事件确定样品中目标分析物的分数丰度。
50.在一些实施方案中,本文提供了一种计算机执行的确定样品中目标分析物的真实分数丰度的估计值的方法,包括:从纳米孔装置获得一组数据,所述数据包括来自至少一个对照样品和至少一个未知样品的事件特征;鉴定用于产生阈值以区分与所述目标分析物相关的第一事件特征和与所述参照分析物相关的第二事件特征的一组特性;并使用训练的支持向量机估计所述未知样品中分数丰度的真实值。
51.在一些实施方案中,本文提供了确定样品中目标分析物的分数丰度的估计值的计算机执行的方法,其包括:从一个或多个纳米孔装置获得一组数据,每个纳米孔装置包括一个或多个纳米孔;用多孔分析模型处理从该组数据导出的一组输入,该组输入包括来自该
组纳米孔中的每一个的调用;以及基于所述多孔分析模型的返回输出,生成样品中目标分析物的分数丰度的估计值和分数丰度的可靠性。
附图说明
52.如从附图中所示的本发明的特定实施方案的以下描述,前述和其他目的、特征和优点将是显而易见的,附图中相似的附图标记在不同视图中指代相同的部分。附图不一定按比例绘制,而是将重点放在说明本发明的各种实施方案的原理上。
53.图1a显示了由穿过纳米孔的dsdna引起的单分子事件的典型电子特征,其具有移位的特征持续时间和移位期间电流的减少。
54.图1b显示了在22nm直径的纳米孔中记录的5.6kb dsdna的maxδg对持续时间的全事件散点图。
55.图2a显示当727bp dna在1m licl中100mv下通过25nm直径固态纳米孔时的典型事件。事件区域有阴影。
56.图2b示出了事件持续时间随dsdna长度的增加而增加,而事件深度是保守的。
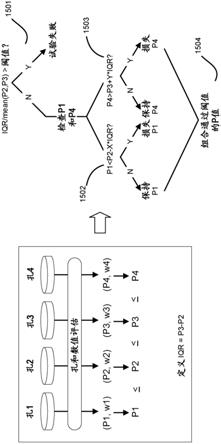
57.图2c显示了对于所示的每个长度的dsdna记录的所有事件的面积的log
10
分布的图。
58.图3a描绘了在来自类型1分析物(正方形)和类型2分析物(圆形)的事件之间产生的阈值的实例。
59.图3b示出了输入特征向较高维空间的转化以增加来自类型1分析物(正方形)和类型2分析物(圆形)的事件之间的线性阈值的准确度的结果的示例。
60.图4a显示了根据事件面积来自参照分析物样品、目标分析物样品和混合样品的所有事件的概率直方图。
61.图4b描绘了来自仅参照分析物(qref)、仅目标分析物(qtarg)以及目标分析物和参照分析物的混合样品(qmix)的低于面积阈值的事件百分比的图。
62.图4c示出了分数量参数ρ(q)如何在q值处图形表现。q=5pa*ms阈值(垂直虚线)对应于0.05的假阳性(即,q
ref
=0.05)和0.1的假阴性(即,q
targ
=0.9)。
63.图5a显示了目标基因相对丰度的估计值(gmo(%))相对目标基因的真实相对丰度(gmo(%))的确定的结果。显示高于或低于零误差线(斜率=1)的10%的误差容限用于比较。
64.图5b显示使用两个分离的对照和六个已知混合物测定样品中遗传修饰生物体的真实相对丰度的估计值的结果。将预测的目标丰度百分比的值相对于真实的目标丰度百分比作图。为了比较,显示了高于和低于零误差线(斜率=1)的10%误差容限。
65.图6显示了在用于根据事件面积区分目标分析物与参照分析物的阈值范围上目标分析物丰度(gmo(%))的估计值的结果。
66.图7显示了来自训练的支持向量机的一组测试数据的准确度预测,其具有用于区分来自目标和参照分析物的事件特征的最佳参数。
67.图8显示了两种分子类型(与探针/有效负载结合的94bp目标dsdna和与探针/有效负载结合的74bp参照dsdna)的事件图,其在相同孔上作为分离的对照顺序地运行。
68.图9a显示了重叠的100%目标分析物对照样品(实心圆)和100%参照分析物对照样品(空心方块)的平均δg相对于持续时间的代表性事件图。目标分析物是具有与3分支peg连接的g12d结合探针(表示为g12d-3bpeg)的89bp dna。参照分析物是具有与8臂peg连接的野生型(c.35g)-结合探针(表示为wt-8armpeg)的89bp dna。用于确定事件特征来自穿过纳米孔的目标分析物的阈值(q1=1毫秒,q2=0.4ns和q3=0.65ns)建立目标标记框(虚线)。
69.图9b显示了来自图9a的图,其中来自未知样品a(三角形)和包含目标分析物和参照分析物的样品b(星形)的数据覆盖在该图上。
70.图10显示了重叠的100%目标分析物对照样品(实心圆)和100%参照分析物对照样品(空心方块)的平均δg相对持续时间的代表性事件图。还绘制了用于区分目标分析物与参照分析物的支持向量机鉴定的决策边界(即阈值)。
71.图11显示了在maxδg相对持续时间的全事件散点图上绘制的50%目标/50%参照混合物样品的事件。目标域的框包含与探针结合的突变体目标相关的事件。
72.图12显示了将使用3-高斯混合物模型的高斯混合物期望最大化算法(emgm)应用于来自图11中所示的50%目标/50%参照混合物样品的数据的结果,用于鉴定目标(突变体)和参照(野生型)群体。
73.图13显示了将使用3-高斯混合物模型的emgm应用于来自仅参照对照样品的数据以建立假阳性分数的结果。
74.图14显示了将使用3-高斯混合物模型的emgm应用于来自混合未知样品的数据以鉴定未知样品中突变体(目标)分子的相对丰度的结果。
75.图15a描绘了使用来自多个孔的一致性调用(consensus call)来确定样品中目标分析物的分数丰度的方法的流程图。
76.图15b描绘了使用来自四个孔的一致性调用来确定分数丰度的实施方案。
77.图15c描绘了由任意数目的纳米孔通过图15b的系统的实施方案实施的方法的流程图。
78.图15d描述了使用来源于单个纳米孔和来源于多个纳米孔的信息确定目标分子浓度的方法的输出。
79.图16a描绘了根据一个或多个实施方案用于预过滤来自纳米孔的数据的方法的流程图。
80.图16b描绘了图16a所示方法的输出,其中来自纳米孔的事件数据通过电信号的振幅相对停留时间作图。
81.图16c描述了图16a和16b中所示方法的输出,其中系统使用pca操作的分量(pc1和pc2)来为每个样品群体产生计数相对pc1的高斯分布。
82.图16d描绘了用于使用图16c所示的pca操作的输出来生成分离分数的数据。
83.图16e描绘了最大电流振幅针对停留时间(以秒计)的对数函数的图,以检查样品的校准比。
具体实施方式
84.在下面的说明书中阐述了本发明的各种实施方案的细节。根据说明书和附图以及权利要求,本发明的其他特征、目的和优点将显而易见。
85.定义
86.在整个本技术中,该文本涉及本发明营养素、组合物和方法的各种实施方案。所描述的各种实施方案旨在提供各种说明性实例,而不应解释为对可选种类的描述。相反应该注意,这里提供的各种实施方案的描述可以是重叠的范围。这里讨论的实施方案仅仅是说明性的,并不意味着限制本发明的范围。
87.而且在整个本公开中,各种出版物、专利和公开的专利说明书通过标识引用来参考。这些出版物、专利和公开的专利说明书的公开内容通过引用结合到本公开中以更全面地描述本发明所属领域的状态。
88.如说明书和权利要求书中所用,单数形式“一”、“一个”和“该”包括复数指代,除非上下文另有明确说明。例如,术语“一电极”包括多个电极,包括其混合物。
89.如本文所使用的,术语“包含”旨在表示所述装置和方法包括所述及的组件或步骤,但不排除其他组件或步骤。当用于定义装置和方法时,“基本上由......组成”意味着排除对组合具有任何必要意义的其他组件或步骤。“由......组成”是指排除其他组件或步骤。由这些过渡术语中的每一个定义的实施方案都在本发明的范围内。
90.所有数字指示,例如距离、尺寸、温度、时间、电压和浓度,包括范围,是旨在涵盖参数测量中的普通实验变异的近似值,并且该变异旨在所描述的实施方案的范围内。应理解,尽管并非总是明确指出所有数字指示前面都有术语“约”。还应理解,尽管并非总是明确说明,但本文描述的组件仅仅是示例性的,并且这些组件的等同物在本领域中是已知的。
91.如本文所用,术语“分析物”是指任何分子、化合物、复合物或其他实体,其存在可以使用纳米孔传感器检测以便于确定孔中分析物的相对丰度。当提及目标分析物或参照分析物时,术语目标分子或参照分子可互换使用。
92.如本文所用,术语“目标分析物”是指样品中感兴趣的分子或复合物。在一些实施方案中,目标分析物包含具有感兴趣的核酸序列的多核苷酸的部分。如本文所述,目标分析物可以特异性地靶向于通过探针结合以促进纳米孔传感器中目标分析物的检测。
93.如本文所用,术语“参照分析物”是指样品中感兴趣的分子或复合物,其丰度用作目标分析物的定量的相对量度。在一些实施方案中,参照分析物包含具有感兴趣的核酸序列的多核苷酸的部分。如本文所述,参照分析物可以特异性地靶向通过探针结合以促进纳米孔传感器中目标分析物的检测。
94.如本文所用,术语“特异性结合”或“特异性地结合”是指探针与目标分析物或参照分析物的靶向结合。
95.如本文所用,术语“探针”是指与目标分析物或其片段特异性结合的分子。在一些实施方案中,探针包含配置成影响在复合物移位时产生的电子特征的有效负载分子,所述复合物包含与探针-有效负载分子或复合物结合的目标或参照分析物。在一些实施方案中,探针包含适于结合有效负载分子的有效负载分子结合部分。
96.如本文所用,术语“有效负载分子”是指具有当在相关的尺寸范围内的纳米孔捕获中时有助于产生独特的电信号的物理尺寸的分子。有效负载分子可以与目标分析物或参照分析物结合以促进纳米孔装置中目标分析物或参照分析物的检测。在一些实施方案中,有效负载分子也可带电以充当驱动分子。在一些实施方案中,有效负载分子包含能够特异性结合探针分子的探针结合部分,该探针特异性结合目标分析物或参照分析物。
97.如本文所用的术语“纳米孔”(或仅“孔”)是指分隔两个体积的膜中的单个纳米级开口。孔可以是例如插入脂质双层膜中的蛋白质通道,或者可以通过钻孔或蚀刻或者使用电压脉冲方法通过薄的固态基底(例如氮化硅或二氧化硅或石墨烯或这些或其他材料的组合的层)建造。几何上,孔具有直径不小于0.1nm,且直径不大于1微米的尺寸;孔的长度由膜厚度决定,膜厚度可以是亚纳米厚度,或厚度高达1微米或更大。对于厚度大于几百纳米的膜,纳米孔可称为“纳米通道”。
98.如本文所用,术语“纳米孔仪器”或“纳米孔装置”是指将一个或多个纳米孔(并联或串联)与用于感测单分子事件的电路组合的装置。纳米孔装置内的每个纳米孔,包括其用于促进用该纳米孔的感测的腔室和电极,在本文中称为纳米孔传感器。具体而言,纳米孔仪器使用灵敏的电压钳放大器以施加跨一个或多个孔的指定电压而同时测量通过孔的离子电流。当单个带电分子如双链dna(dsdna)被捕获并通过电泳驱动通过孔时,测量的电流发生偏移,表明捕获事件(即分子通过纳米孔的移位,或分子捕获在纳米孔中),并且事件的(电流振幅)偏移量和持续时间用于表征纳米孔中捕获的分子。在实验期间记录许多事件之后,分析事件的分布以根据其偏移量(即,其电流特征)来表征相应的分子。通过这种方式,纳米孔为生物分子感测提供了简单、无标记、纯电子的单分子方法。
99.如本文所使用的,术语“电信号”包括根据电子电路的配置随时间收集的关于电流、阻抗/电阻或电压的一系列数据。常规地,电流以“电压钳”配置测量;电压以“电流钳”配置测量,并且电阻测量可以使用欧姆定律v=ir在任一配置中导出。还可以通过从纳米孔装置收集的电流或电压数据测量来产生阻抗。这里所称的电信号的类型包括电流特征和电流阻抗特征,尽管可以使用各种其他电信号来检测纳米孔中的颗粒。
100.如本文所用,术语“事件”是指可检测分子或分子复合物通过纳米孔的移位及其通过电信号的相关测量,例如,通过纳米孔的电流随时间的变化。它可以通过纳米孔中其电流、相对基线开放通道的电流变化、持续时间和/或分子检测的其他特征来定义。具有相似特征的多个事件指示相同或具有相似特征(例如,体积、电荷)的分子或复合物的群体。
101.如本文所使用的,事件的“面积”是指事件的持续时间的绝对值(即,电流偏离开放通道电流信号的持续时间)乘以事件持续时间内相对于开放通道的电流平均变化(即pa*ms)。
102.如本文所使用的,术语“相对丰度”是指某项目相对于组中相关项目总数的量。例如,在样品中的目标分析物的情况中,目标分析物的相对丰度是指与参照分析物相比,样品中存在的目标分析物的量。这可以表示为分数丰度,例如,与目标分析物和参照分析物的总群体相比,样品中目标分析物的百分比。相对丰度也可以表示为例如目标分析物:参照分析物的比率。关于电子特征,一组电子特征的相对丰度可以指相比于与参照分析物相关的第二电子特征的量,与目标分析物相关的第一电子特征的量。为了区分样品中目标分析物的实际相对丰度(即,先前测量或制备为具有已知的相对丰度)和根据本文提供的方法测定的相对丰度,我们经常将实际相对丰度称为“真实相对丰度”,以及通过本文描述的方法测定的相对丰度作为“真实相对丰度的估计值”。
103.如本文所用,术语“对照样品”是指含有已知相对丰度的目标分析物与参照分析物的样品。本文使用对照样品,例如参照对照样品、目标对照样品和混合对照样品,以提高未知样品中分数丰度的估计值的准确度。在一些实施方案中,对照样品包含目标分析物、参照
分析物或两者。
104.如本文所用,术语“未知样品”或“未知混合样品”或“混合未知样品”是指含有未知的参照分析物相对丰度的样品。如果要通过本文提供的方法确定相对丰度,则参照分析物的相对丰度被认为是未知的,即使已经知道估计值的一些值。对于一些未知样品,样品中参照分析物的量或浓度是已知的。
105.如本文所用,术语“已知样品”是指含有已知相对丰度的目标分析物与参照分析物的样品,并且用于训练、验证或提供精确的估计值,分数丰度估计模型或模型的特征(例如阈值)。
106.引言/综述
107.在一些实施方案中,本文提供的发明是用于确定目标分析物相对于样品中存在的参照分析物的真实相对丰度(例如,分数量或比率)的估计值的方法。该方法利用纳米孔单分子计数器(即,纳米孔装置)来检测和区分样品中的目标分析物和参照分析物。
108.使用与目标分析物和参照分析物相关的原始电子事件特征来确定样品中目标分析物的相对丰度的估计值可能是不准确的,原因有多种,包括假阳性检测误差、假阴性检测误差以及与混合样品中目标分析物和参照分析物之间的捕获率常数差异相关的误差。在本文中,根据一些实施方案,我们提供了提高估计样品中参照和目标分析物的真实分数丰度的准确度的方法。在一些实施方案中,这些方法需要使用专门设计来校正与混合样品中的电子信号检测相关的一个或多个误差的对照样品。当混合样品包含已知量或浓度的参照分析物时,相对丰度的改进估计值可用于提供样品中目标分析物的真实量或浓度的改进估计值。
109.在一些实施方案中,本文提供的方法通过考虑假阳性或假阴性检测误差或所述目标分析物与所述参照分析物之间的捕获率常数差异来提高混合未知样品中目标分析物的分数丰度的估计值的准确度。在一些实施方案中,运行一系列对照以提高分数丰度估计值的准确度,包括考虑假阳性目标分析物检测误差的仅参照对照、考虑假阴性目标分析物检测误差的仅目标对照及考虑目标分析物和参照分析物之间的捕获率常数差异的一个或多个混合对照样品。
110.在一些实施方案中,混合未知样品中目标分析物和参照分析物之间的捕获率是相对一致的,使得不需要使用混合对照来改进相对丰度的估计值。在一些实施方案中,混合样品中目标分析物与参照分析物之间的相对捕获率是已知的,使得校正项可以应用于来自混合未知样品的数据以补偿该差异而改进分数丰度的估计值而无需运行混合对照样品。在一些实施方案中,使用与混合的未知样品中相同的目标和参照分析物种类在基本相同的纳米孔条件下运行的来自混合对照样品的数据用于改进分数丰度的估计值而不实际运行混合对照样品作为方法的部分。
111.在一些实施方案中,确定阈值以使得来自混合未知样品的假阳性值是可忽略的,并且不需要使用仅参照对照来改进相对丰度的估计值。在一些实施方案中,来自混合样品的假阳性值是已知的,使得校正项可以应用于来自混合未知样品的数据以补偿假阳性误差从而改进分数丰度的估计值而不运行仅参照对照样品。在一些实施方案中,来自在基本上相同的纳米孔条件下使用与混合未知样品中相同的参照分析物种类运行的仅参照对照样品的数据用于改进分数丰度的估计值而不实际运行仅参照对照作为方法的部分。
112.在一些实施方案中,确定阈值以使得来自混合未知样品的假阴性值是可忽略的,并且不需要使用仅目标对照来改进相对丰度的估计值。在一些实施方案中,来自混合样品的假阴性值是已知的,使得校正项可以应用于来自混合未知样品的数据以补偿假阴性误差从而改进分数丰度的估计值而不运行仅目标对照样品。在一些实施方案中,来自在基本上相同的纳米孔条件下使用与混合未知样品中相同的目标分析物种类运行的仅目标对照样品的数据用于改进分数丰度的估计值而不实际运行仅目标对照作为方法的部分。
113.样品使用
114.确定与参照核酸分子相比,核酸片段内靶序列的分数量具有许多应用。
115.在一个示例应用情况中,我们使用本文的方法来确定遗传修饰生物体(gmo)的转基因序列相对于基因组dna(例如从种子集合获得的)内的非gmo参照序列的分数量。出于监管和经济原因,这种测定很重要。具有期望性状的种子的买方和卖方需要精确和准确地了解包含期望性状的种子的分数以使定价和交易是公平的。
116.因此,在一些实施方案中,本文提供的方法提供来自推测含有1-100%gmo含量的集合种子、谷粒、面粉和饲料的%gmo含量测定。种子开发商、种植者和监管机构需要精确的手段和能力以解析gmo含量的10%差异(1.1倍)。%gmo定义为100x(gmo事件拷贝数)/(分类群特异性基因组基准拷贝数)。
117.作为另一个示例应用情况,我们使用本文所述的方法来监测来自血液或尿液样品的无细胞循环dna内包含点突变的多核苷酸序列与非突变(野生型)序列的相对丰度。特定基因组位点的点突变的相对丰度与癌症类型和治疗结果相关。确定对于非突变体序列的突变体相对丰度可用于指导诊断、治疗和疾病进展监测。尽管肿瘤成像结果可能需要数周才能显示出收缩/生长的团块,但本文所述的方法允许通过使用易于获得的样品类型快速鉴定突变标志物的相对丰度,从而允许有效且频繁的测试(例如,每天)。关键的是,这种技术可以通过提供疾病动态的更多时间点来更有效地揭示治疗反应,同时还允许早期检测复发。
118.在一些实施方案中,本文提供的方法在遗传性癌症筛选测定中提供拷贝数变异(cnv)测定。用于遗传性癌症倾向的拷贝数变异(cnv)测试。目标是检测基因调控元件与参照的小于1.5倍差异的缺失或重复。例如,brca1基因拷贝数的10%差异(1.1倍)可能需要临床行动。
119.纳米孔检测
120.在固态硅基基底中形成纳米孔,并且通过在缓冲电解溶液中跨孔施加电压来执行单分子实验。
121.图1a显示由dsdna穿过纳米孔引起的典型单分子事件。通过持续时间宽度和最大电导深度,maxδg来定量事件。maxδg是电流衰减δi除以施加的电压v。图1b显示了在5分钟内用22nm直径纳米孔(v=100mv,1nm dna,1m licl,10mm tris,1mm edta,ph=8.8)记录的1072个5.6kb dsdna的事件的maxδg对持续时间的全事件散点图。
122.除了maxδg和持续时间之外,可以定量的事件分布的其他特性是:平均δg、中值δg、事件信号的标准偏差以及其他更高阶特性。另一个有用的特性是事件的积分面积的绝对值,其可以计算为平均δg乘以持续时间(storm,aj,jh chen,h w zandbergen和c dekker.“translocation of double-strand dna through a silicon oxide nanopore“.physical review e 71,no.5(2005年5月):051903,doi:10.1103/physreve.71.051903)。积分面积,或仅“面积”,也被称为电荷缺陷(fologea,daniel,marc gershow,bradley ledden,david s mcnabb,jene a golovchenko和jiali li.“detecting single stranded dna with a solid state nanopore“.nano letters 5,no.10(2005年10月):1905-9.doi:10.1021/nl051199m)。
123.对于足够长以在折叠状态下穿过纳米孔的dsdna(》700bp),事件可以显示多于一个幅度。图1b是这样的实例,其中完全折叠的事件显示更大的maxδg值和更短的持续时间,并且展开的事件显示更长的持续时间和更浅的maxδg值。部分折叠的事件在事件内同时显示两个幅度水平,从较深的水平开始并以较浅的水平结束,并且具有在展开的和完全折叠的事件之间的总持续时间宽度。虽然δg和持续时间分布对于可以折叠的dsdna显示出模式的混合,但事件面积对于dsdna具有单一模式分布,无论dna是否足够长以在通过纳米孔时折叠。
124.使用纳米孔对目标分析物和参照分析物的区分是基于在各自通过纳米孔移位时检测到足够不同的事件特征,以实现可靠和灵敏的检测。平均事件特征的差异可以基于特征持续时间、电流的变化、事件特征内的特性或其他可区分的特性及其组合。所使用的特性是确定阈值的基础,该阈值用作鉴定与用于本文所述的分数丰度测定的参照分析物和目标分析物相关的事件特征的方法。
125.在一些实施方案中,目标和参照片段是具有足够不同长度的dsdna分子以产生不同的纳米孔事件持续时间。
126.在一些实施方案中,目标分析物和参照分析物都是dsdna,并且产生不同事件类型的特性可以是目标分析物和参照分析物的长度差异。在这样的实施方案中,由目标和参照分析物的长度差异产生的目标和参照事件面积的差异用于区分目标和参照事件特征(即,事件分布)。
127.dsdna的事件面积分布具有单一模式。当目标和参照分析物是具有足够不同的长度的dsdna时,这使得面积成为将事件分类为目标类型或参照类型的有用的事件特性。为了产生足够不同的面积分布,对于直径大于20nm的纳米孔,长度应该相差至少100bp。对于直径为1-20nm的较小纳米孔,例如,通过受控的介电击穿形成的(yanagi,itaru,rena akahori,toshiyuki hatano和ken-ichi takeda.“fabricating nanopore with diameters of sub 1nm to 3nm using multilevel pulse-voltage injection.“scientific reports 4(2014):5000doi:10.1038/srep05000),目标和参照的dsdna长度应相差至少20bp。
128.对于目标分子和参照分子的dsdna长度可以如何不同没有明显的上限。
129.图2a显示当727bp dna在1m licl中100mv下通过25nm直径的固态纳米孔时的典型事件。事件面积显示为阴影区域。图2b显示事件面积如何随dsdna长度增加。主要地,是事件持续时间增加而事件深度保持保守,且事件面积(平均深度乘持续时间)捕获这种长度相关的增加,因为它与持续时间成比例。图2c显示了对于在相同的纳米孔上顺序运行的所示的每个dna长度记录的所有事件的面积(pa*ms)的以10为底的log的分布。事件面积的以10为底的log的分布近似正态(高斯)。随着dna长度的增加,分布的平均值增加。
130.为了产生包含目标序列的dsdna和包含参照序列的dsdna,其中两个dsdna长度为
至少300bp,长度为至多100,000bp。在一些实施方案中,目标和参照dsdna分析物的长度差异为至少10bp,20bp,30bp,40bp,50bp,60bp,70bp,80bp,90bp,100bp,150bp,200bp或300bp。通常,当通过大小区分时,目标和参照dsdna分析物之间的长度差异增加有助于与目标和参照分析物相关的事件特征测定的更高灵敏度和特异性,这改进了样品中相对丰度的估计。
131.在一些实施方案中,指明从基因组dna(gdna)切除的多核苷酸片段的性质是用于分数丰度测定的工作流程的一部分。这些片段规格可包括例如它们的序列、长度和二级结构。在一些实施方案中,片段规格增强纳米孔装置对特定序列的捕获和检测。
132.在一些实施方案中,目标和参照片段与不同的有效负载分子结合,使得目标/有效负载和参照/有效负载分子产生足够不同的纳米孔事件特征。在一些实施方案中,不同事件特征是事件持续时间、事件最大深度、事件平均深度和/或其他事件性质的组合。
133.在一些实施方案中,通过序列特异性有效负载区分目标和参照分析物,当每个分子或复合物类型(目标-有效负载,参照-有效负载)通过孔时,该有效负载产生独特的纳米孔事件特征。在国际公开号wo/2015/171169,“target detection with a nanopore”,国际公开号wo/2014/182634,“a method of biological target detection using a nanopore and a fusion protein binding agent”,国际公开号wo/2016/049657,“target sequence detection by nanopore sensing of synthetic probes”,国际公开号wo/2016/126746,“nanopore detection of target polynucleotides from sample background”和国际公开号wo/2017/173392,“nanopore discrimination of target polynucleotides from sample background by fragmentation and polyload binding”中描述了使用与结合于每种分子类型的有效负载结合的探针以促进区分的方法,其各自通过引用整体并入本文。
134.在一些实施方案中,目标分析物和/或参照分析物是dsdna,其中独特的有效负载结合的pna侵入每种dsdna类型(靶标和参照)以产生待用纳米孔检测的两种大分子类型。在一些实施方案中,目标分析物和/或参照分析物是单链核酸(ssna),包括dna或rna。有效负载结合的互补核酸(例如,lna)与ssna上的区域杂交,并且一个或多个侧翼引物与ssna的其他区域杂交,以产生具有结合的有效负载的双链分子,并且有效负载是对于目标和参照独特的,以建立独特的目标和参照事件分布。
135.分数丰度框架
136.在一些实施方案中,分数丰度框架涉及:1)对于目标分析物和参照类型两者设计和应用生物化学方法以将样品材料转化为纳米孔感测形式;2)应用特定的纳米孔实验方案;和3)应用分析方法以产生目标与参照分析物的相对丰度的定量估计值。本节重点在于框架的部分1。
137.用于纳米孔检测的样品制备
138.包含靶序列的分子(称为“目标分析物”或“目标分子”)和包含参照序列的分子(称为“参照分析物”或“参照分子”)可以在物理上相似:例如目标和参照分子可以具有相似的分子量或多核苷酸长度,并且可以仅相差单核苷酸。生物化学方法的目标是在没有偏差的情况下使目标和参照分子在通过纳米孔移位时产生不同的“目标”或“参照”事件分布。以这种方式,在纳米孔上测量的目标:参照混合物代表样品中目标:参照浓度比率。
139.在一些使用情况中,将多核苷酸序列添加至目标分子、参照分子或两者以产生不同的事件分布可能是有利的。例如,从血液或尿液的无细胞循环dna部分获得的大多数dna片段的长度均匀地短至150-200bp。通过常规方法(包括pcr、连接和直接寡核苷酸杂交)添加多核苷酸序列允许最大化纳米孔事件的区别的灵活性。在其他情况下,携带共价结合的聚合物有效负载的化学修饰寡核苷酸探针的杂交用于改变目标或参照分析物电荷和分子量而不影响多核苷酸长度。在所有情况下,目的是每个目标和参照分子组的不同事件分布。
140.存在着其中有足够的起始材料(其可以在纳米孔感测之前使用富集策略而无需pcr)的使用情况,包括gmo实例(含有gmo靶序列的大豆种子的分数量)。还存在着其中需要pcr作为富集的部分的其他情况,包括液体活组织检查,因为血液或尿液样品可含有每毫升液体《10个靶序列。所提出的方法与样品制备要求不相干,包括样品收集、纯化及目标和参照的浓缩。纳米孔测量和随后的分数丰度定量可以实现,只要目标和参照与背景(《1pm)相比充分富集(》10pm),且目标和参照分析物产生可以彼此区分和区别于背景(在存在的情况下)的电事件特征。
141.在一些实施方案中,目标或参照分析物包括长度为20nt-100,000nt的多核苷酸序列(包括双链和单链dna、rna和合成多核苷酸)。在一些实施方案中,包含靶序列的多核苷酸源自有机体gdna,包括来自植物、人、动物、昆虫、细菌或病毒。在一些实施方案中,目标多核苷酸序列源自外源的非基因组序列,包括来自包括质粒、bac、线性序列验证的基因块、表达盒的来源的双链或单链rna或dna。
142.在一些实施方案中,我们提供特异于通过纳米孔装置的分数丰度(例如拷贝数变异)检测的富集。在一些实施方案中,我们使用定点片段化方法来制备用于纳米孔检测的样品。在一些实施方案中,本文提供的检测方法包括核酸样品的多核苷酸片段化的上游片段化,例如,长度为20-100,000nt或碱基对大小的gdna。在一些实施方案中,核酸是使用限制性酶序列特异性地片段化或通过使用包括cas9/sgrna、talens、锌指蛋白/核酸酶的定点核酸酶或本领域已知的另一种片段化方法。
143.在一些实施方案中,使用正向和负向尺寸选择进行目标或参照分析物富集以保留、丢弃和洗脱目标片段大小。例如,低比例的spri珠:dna(0.6)在peg存在下保留和丢弃高分子量多核苷酸种类(例如》8,000bp dna),然后是spri珠:dna(1.5:1)以结合、洗涤和洗脱片段大小(例如2000-8000bp)。在一些实施方案中,目标或参照核酸可经历核酸扩增以促进纳米孔中的检测。
144.纳米孔检测
145.分数丰度框架涉及:1)对于目标分析物和参照类型两者设计和应用生物化学方法以将样品材料转化为纳米孔感测形式;2)应用特定的纳米孔实验方案;和3)应用数学方法以生成对于目标-参照(目标:参照)分析物的分数量的定量估计值。本节重点在于部分2,实验方案。
146.本文描述了样品在纳米孔中运行的重复以提供混合未知样品中目标分析物的真实相对丰度的改进估计值。在一些实施方案中,制备目标分析物和参照分析物以确保使用纳米孔传感器在各个种类之间可靠的区分。在一些实施方案中,选择包含目标序列的片段(即“目标片段”)的特征和包含参照序列的片段(即“参照片段”)的特征,使得这两个片段产生可以通过一个或多个信号性质区分的纳米孔事件特征。
147.在一些实施方案中,使用一种或多种对照混合物(即对照样品)来校准未知混合物中目标与参照的分数量的估计值。在一些实施方案中,该校准补偿目标和参照分子类型之间纳米孔捕获效率的差异。
148.在一些实施方案中,在纳米孔上测量目标和参照分析物的未知混合物,并且在数学上量化目标与参照的分数丰度。在一些实施方案中,在相同纳米孔上顺序测量源自相同样品的目标和参照分子类型的一个以上未知混合物。在一些实施方案中,在不同纳米孔上平行测量源自相同样品的目标和参照分子类型的一个以上未知混合物。
149.在一些实施方案中,在未知混合物之前和/或之后,在纳米孔上测量一种或多种对照(包括单独的100%目标、单独的100%参照以及目标和参照分子的已知混合物)。
150.在一些实施方案中,实验方案包括在纳米孔上运行未知混合物之前或之后,或者在此之前和之后,在纳米孔上顺序运行一个或多个对照。对照可以由100%目标分析物或100%参照分析物制成,且这些被称为“分离的对照”。对照也可以是目标和参照分析物的任何已知的混合物,称为“混合物对照”或“对照混合物”。对照混合物可以是1:1比率的目标:参照分析物,或0.01:1到100:1的任何其他比率的目标:参照分析物,或任何小于0.01:1(例如,0.001:1)的比率或任何大于100:1(例如,1000:1)的比率的目标:参照分析物。一个或多个对照可以运行超过一次。对照(分离的和混合物)和未知混合物可以在相同的纳米孔上以任何顺序依次运行。在对照和未知样品之间,冲洗纳米孔捕获分子的流体通道(即腔室)。
151.在一些实施方案中,不运行对照,而仅运行未知混合物,并与通过在单独的先前实验中运行对照建立的参照表进行比较(即,对照不在使用点运行)。
152.在一些实施方案中,一个或多个流体隔离通道和纳米孔传感器与测量未知物的一个或多个流体隔离通道和纳米孔传感器平行地测量对照。超过一个纳米孔可以达到每个流体通道。在平行化实施方式中,可能不需要冲洗,因为每个孔仅看到一个试剂组,即对照(分离的或混合的)或未知的(来自1个或多个未知物的组)。
153.在一些实施方案中,在对照混合物浓度中对照分析物与目标分析物的比率接近未知样品中参照分析物与目标分析物的预期比率,尽管这可能不是事前知道的。
154.可以在相同的纳米孔上顺序地运行多种未知混合物,在添加每个新的未知物用于测量之前冲洗掉先前的未知物。这要求未知混合物由相同的目标和参照分析物类型组成,尽管它们的比率在不同的未知物中可能相同或不同的。
155.每个记录时间段应该足够长以检测每种试剂类型的至少100个事件,并且随着记录更多事件而性能改善,其中当记录超过500个事件时改善是显著的,并且当记录超过1000个事件时非常显著。每个试剂组的记录时间段可以相同或不同。适应性方案可以当检测到目标分子数时动态地停止记录。我们之前已经建立了用于确定达到所需置信水平(例如,95%,98%,99%,99.9%等)所需的分子数量的方法,其可应用于所提出的工作流程中的任何试剂组(对照或未知)(si section 10.2,morin,trevor j,tyler shropshire,xu liu,kyle briggs,cindy huynh,vincent tabard-cossa,hongyun wang和william b dunbar。“nanopore-based target sequence detection”.编辑meni wanunu.plos one 11,no.5(2016年5月5日):e0154426-21.doi:10.1371/journal.pone.0154426)。
156.在一些实施方案中,具有单个纳米孔的实验方案是运行1)100%目标记录时间段t,2)冲洗纳米孔室,3)100%参照记录时间段t,4)冲洗纳米孔室,5)50:50目标:参照混合物
记录时间段t,6)冲洗纳米孔室,7)未知混合物记录时间段t。记录时间段t可以是15秒,30秒,45秒,1分钟,5分钟,10分钟,或在1-15秒之间或10-60分钟之间的任何持续时间。
157.另一种常见的实验方案是运行(1)-(7),然后是8)冲洗纳米孔腔室,9)重复100%目标记录时间段t,10)冲洗纳米孔腔室,11)重复100%参照记录时间段t,12)冲洗纳米孔室,13)重复50:50目标:参照混合物记录时间段t。
158.另一种常见的实验方案是运行(1)-(7),然后是8)冲洗纳米孔腔室,9)重复50:50目标:参照混合物记录时间段t,10)冲洗纳米孔腔室,11)重复100%参照记录时间段t,12)冲洗纳米孔室,13)重复100%目标记录时间段t。
159.再另一个常见的实验方案是运行1)怀疑大约接近未知混合物中的目标:参照比率的目标:参照对照混合物比率,记录时间段t,2)冲洗纳米孔室,3)未知混合物,记录时间段t。
160.再另一个常见的实验方案是运行1)1:1目标:参照对照混合物比率,记录时间段t,2)冲洗纳米孔室,3)未知混合物,记录时间段t。
161.在一些实施方案中,具有单个纳米孔的实验方案是运行1)100%目标,记录时间段t,2)冲洗纳米孔腔室,3)100%参照,记录时间段t,4)冲洗纳米孔腔室,5)未知混合物,记录时间段t。
162.在一些实施方案中,具有单个纳米孔的实验方案是运行1)100%目标,记录时间段t,3)冲洗纳米孔室,4)未知混合物,记录时间段t。
163.在一些实施方案中,具有单个纳米孔的实验方案是运行1)100%参照,记录时间段t,2)冲洗纳米孔室,3)未知混合物,记录时间段t。
164.在一些实施方案中,具有单个纳米孔的实验方案是仅运行未知混合物记录时间段t,并使用来自查找表或先前数据的数据,其包含从100%参照对照样品、100%目标对照样品、已知目标:参照对照混合物或其任何组合得到的误差校正信息,各运行在与未知混合物的实验方案基本相似的条件下,以对由记录时间段t产生的数据提供至少一个校正项而改进未知混合物中目标分析物的分数丰度的估计值。
165.在完成实验方案后,对来自对照(如果运行)的记录事件和来自未知物的记录事件进行数学分析以预测一个或多个未知物中目标与参照的分数量。
166.分数丰度估计和阈值确定
167.分数丰度框架涉及:1)对于目标分析物和参照类型两者设计和应用生物化学方法以将样品材料转化为纳米孔感测形式;2)应用特定的纳米孔实验方案;和3)应用数学方法以生成对目标-参照(目标:参照)分析物的分数量的定量估计。本节重点在于框架的部分3。
168.在一些情况下,定量目标序列“t”与参照序列“r”的估计浓度比率r=[t]/[r]。转基因百分比或gmo%是转换为百分比的比率r。在一些情况下,定量目标序列与总量(目标加参照序列)的估计分数量f=[t]/([t]+[r])。存在着比率r和分数f之间的简单转换,即f=r/(r+1)或等同地,r=f/(1-f)。
[0169]
分数丰度方法预测目标与参照或目标与总量(目标和参照的总和)的相对量。在一些实施方案中,可以添加校准分子以确定目标或参照分子的绝对浓度。在一些实施方案中,目标分子vs校准物分子在恒定浓度下的相对捕获率可以与样品中目标分子的浓度相关联,且源自多个纳米孔的信息可用于确定目标分子的浓度。
[0170]
在一些实施方案中,在目标分析物和参照分析物类型之间比较单个纳米孔事件的特性以计算分数丰度。在一些实施方案中,在目标分析物和参照分析物类型之间比较多于一个纳米孔事件的特性以计算分数丰度。
[0171]
我们在此描述了三种方法来改进阈值确定以区分与目标分析物和参照分析物相关的事件特征,并校正来自纳米孔的事件特征的使用的误差以确定分数丰度:1)q-检验方法,2)支持向量机(svm),以及3)高斯混合的期望最大化算法(emgm)方法。
[0172]
以下一般概念应用于这些方法。首先,目标分析物“t”与参照分析物“r”的真实比率表示为r=[t]/[r]。目标分析物与总量(目标加参照)分析物的真实分数表示为f=[t]/([t]+[r])。比率r和分数f之间的简单转换是f=r/(r+1)或等同地,r=f/(1-f)。未知混合物的真实比率表示为r
mix
,且混合物的真实分数表示为f
mix
。数学方法生成f
mix
和r
mix
的估计值,其表示为和设计和建立目标分子和参照分子构建体以提供不同的纳米孔事件特征。
[0173]
q-检验方法
[0174]
数学方法首先设计用于将所有记录的事件分箱(binning)到一个或两个类别的标准,即,目标阳性(等同地,参照阴性)或目标阴性(等同地,参照阳性)。事件标准使用一个或多个事件特性。在一些实施方案中,单个特性用于创建用于分箱事件的标准。根据该标准,每个事件被标记为目标事件或参照事件。这些被称为“目标标记的”或“参照标记的”。
[0175]
目标标记事件的分数表示为q,等于目标标记事件的数量除以事件总数。参照标记事件的分数是1-q。标记的分数q是纳米孔上浓度分数f的函数,写为q(f)。
[0176]
混合物中目标标记事件的分数q(f
mix
)表示为q
mix
;100%目标对照中的目标标记事件的分数q(1)表示为q
targ
;100%参照对照中的目标标记事件的分数q(0)表示为q
ref
;目标:参照对照混合物中目标标记事件的分数表示为q
x:y
,其中x:y是对照混合物中目标-参照的混合物的比率。对于分数z=x/(x+y),我们得到q(z)=q
x:y
。在一些实施方案中,优选1:1比率对照混合物,其中z=0.5,并且标记的分数写为q
1:1
或q
50:50
。
[0177]
通常,q
targ
接近1,其中1-q
targ
表示假阴性分数。通常,q
ref
接近0,其中q
ref
表示假阳性分数。对照满足q
targ
≥q
x:y
≥q
ref
。混合物满足q
targ
≥q
mix
≥q
ref
。
[0178]
在一些实施方案中,来自对照的目标标记分数(q
targ
,q
ref
,q
x:y
)单独运行,并且查找表用于参照测量q
mix
的任何新测定法的值。在一些实施方案中,(q
targ
,q
ref
,q
x:y
)在使用点作为测定的部分建立。在一些实施方案中,(q
targ
,q
ref
)单独运行并且查找表用于参照它们的值,而(q
x:y
)值在使用点建立作为测量q
mix
的测定法的部分。
[0179]
在一些实施方案中,来自对照的目标标记分数(q
targ
,q
ref
,q
x:y
)在使用点运行超过一次,并且它们的值被平均用于下面的公式中的后续使用。
[0180]
用于真实分数量f
mix
的估计值的公式通过下式给出:
[0181][0182]
其中且
[0183]
用于真实比率r
mix
的估计值的公式通过下式给出:
[0184][0185]
在用于预测转基因的分数量(gmo)的实例中,gmo(%)等于
[0186]
参数ρ是可以补偿假阳性检测误差、假阴性检测误差或两者的比率的估计值。在一些实施方案中,q
ref
的值可用于补偿假阳性误差。如果不使用假阳性误差的补偿,则可以将q
ref
设置为0。在一些实施方案中,q
targ
的值可以用于补偿假阴性误差。如果不使用假阴性误差补偿,则q
targ
可以设置为0。
[0187]
参数α是比率补偿乘数。分析上,参数α是两个捕获速率常数的比率。捕获速率常数是纳米孔事件速率除以给定分子类型的浓度。具体地,参数α是参照分子捕获速率常数除以目标分析物捕获速率常数。因此,乘数α补偿目标和参照分子类型之间纳米孔捕获和检测的差异。
[0188]
当对照混合物为1:1比率时,
[0189]
当不使用目标分析物和参照分析物之间的捕获速率常数差异的补偿时,在等式(1)和(2)中将α设置为等于1,以分别提供和的估计值。
[0190]
应用等式(1)和(2)分别提供和的估计值。还可以计算和的不确定性估计值或误差条。对于分离的和混合物对照以及对于未知混合物的每个q具有与其相关的标准误差,其中n是事件的总数。在数值上,可以多次绘制来自每个q分布的随机样品,以通过应用等式(1)和(2)来生成和的值的分布。然后可以使用和的分布来计算不确定性边界,从而得到和
[0191]
在一些实施方案中,匹配或超过事件特性标准的事件的比率或分数用于估计未知混合物中目标与参照的分数量。在一些实施方案中,标准是阈值。
[0192]
我们之前的工作描述了如何使用单一标记标准来计算q及其误差棒(morin,trevor j,tyler shropshire,xu liu,kyle briggs,cindy huynh,vincent tabard-cossa,hongyun wang和william b dunbar.“nanopore-based target sequence detection.”meni wanunu编辑.plos one 11,no.5(2016年5月5日):e0154426-21.doi:10.1371/journal.pone.0154426)。如该工作中详述的,通过应用该标准,每个事件j具有分配给它的变量zj。如果事件j被标记,则zj=1;否则,zj=0。对于每个试剂组(对照和未知物),q=(∑jzj)/n,其中n是事件总数。将相同的标准应用于所有对照、分离的和混合物以及所有未知物,以计算在上面的公式(等式(1)-(2))中使用的所有q值。
[0193]
该标准涉及一个或多于一个不等式方程,并且可以是一个或多个事件特性的线性或非线性函数。每个不等式方程具有与之相关的阈值或阈值范围。因此,标准由不等式集和相应的阈值集完全指定。
[0194]
在一些实施方案中,针对一类目标和参照分子类型建立标准,并且使用该类别的分子类型的新测定将利用已经建立的标准。
[0195]
在一些实施方案中,从针对任何新测定收集的对照数据鉴定标准。也就是说,该标准在运行时作为分数丰度实验方案的部分建立。
[0196]
在一些实施方案中,使用相当的目标和参照分子类型从先前实验的集合中先验地建立用于标准的不等式集,而使用对照数据在运行时建立一个或多个标准不等式的阈值集。
[0197]
在一些实施方案中,单一的事件特性用于建立标准。
[0198]
标记为“q”的阈值是基于不等式将目标标记事件与非目标标记(即,参照标记)事件分开的标量值。当在标准中使用多于一个不等式时,q可以表示用于该不等式集的阈值的向量。
[0199]
考虑对于目标和参照使用两个不同长度的dsdna的示例。通常,使用事件面积的单个不等式是可行的标准。当目标是比参照dsdna长的dsdna时,如果面积超过阈值,则事件被标记。当目标是比参照dsdna短的dsdna时,如果面积小于阈值,则事件被标记。
[0200]
可以利用不同的方法来自动选择一个或多个q-阈值,其中一个q值用标准中的各个不等式鉴定。
[0201]
在一些实施方案中,q-阈值被发现为产生q
ref
的期望假阳性的值。例如,q-阈值可以设置为q
ref
的95百分位以产生5%的假阳性。在这种情况下,95%的参照分子事件具有小于q的面积。或者,sft q-阈值发现为产生q
targ
的期望假阴性的值,即,q-阈值可以设置在q
targ
的第5百分位以产生5%的假阴性。
[0202]
在一些实施方案中,发现sft q-阈值为minq{q
targ
(q)-q
ref
(q)}的解。该阈值将是对应于q
targ
和q
ref
之间的最大距离的值。
[0203]
在一些实施方案中,q-阈值范围被计算为产生q
ref
的期望假阳性范围的值。例如,q-阈值范围可以跨q
ref
的95百分位数到99百分位数。
[0204]
在其中利用q阈值范围的一些实施方案中,等式(1)和(2)产生和值的范围,并且计算这些范围的平均值和报告为预测的和值。
[0205]
考虑使用与目标dna和参照dna结合的两种不同有效负载的实例。通常,使用事件平均电导和事件持续时间的三个不等式是可行的标准。具体而言,对于特定的有效负载-目标dna分子构建体,目标事件在平均δg对持续时间的2d事件图上创建独特子空间,并且当持续时间大于阈值时,和当平均δg高于一个阈值且低于另一个阈值时,事件被标记。在这种情况下,标记标准使用两个事件特性(平均δg,持续时间)由三个线性不等式和三个阈值表示。
[0206]
svm方法
[0207]
在一些实施方案中,机器学习用于鉴定用于将每个事件标记为目标分析物事件或参照分析物事件的特性集和特性标准。在一些实施方案中,支持向量机用于将事件分类为目标或参照分析物。
[0208]
在一些实施方案中,开发支持向量机工作流程具有以下步骤:1)加载纳米孔数据,2)选择纳米孔事件特性以区分事件,3)使用对照进行模型训练和测试,4)使用对照进行数据校准,5)预测未知目标:参照混合物。在一些实施方案中,实施已经开发和减化的支持向
量机工作流程以用于自动分数丰度预测。
[0209]
在一些实施方案中,应用机器学习工具来使标准选择自动化,包括事件的特性、不等式的形式(线性和/或非线性)和不等式中使用的阈值q的选择。在一些实施方案中,实施支持向量机(svm),即解决分类问题的监督机器学习方法,以生成标记标准。关于svm的参考文献包括:cortes,c.&vapnik,v.machine learning(1995)20:273和boser,b.e.,guyon,i.m.和vapnik,v.n.(1992)“a training algorithm for optimal margin classifiers,”proceedings of the fifth annual workshop on computational learning theory,其各自通过引用整体并入。
[0210]
下面提供了svm方法应用于我们的分数丰度框架的示例:
[0211]
对于可线性分离的数据,使{x1,...,xn}为数据集和使yi∈{1,-1}为xi的类标签(class label),决策边界应按以下方式对所有点进行分类:
[0212][0213]
为了最大化对所有点进行分类的边际,分类问题成为以下优化问题:
[0214]
最小化
[0215]
条件是
[0216]
接近于决策边界的数据点称为支持向量。
[0217]
对于真实世界(real-word)的问题,由于某些异常值或噪声,数据通常不能线性分离。为了优化分类,调整边际以允许一些错误分类的点。同时,错误分类的情况受到高代价的惩罚。这一边际变为软边际。通过在代价函数中添加“松弛”变量,可以使用软边际分类(图3a):
[0218]
最小化
[0219]
条件是:yi(w
t
xi+b)≥1-εi,εi≥0
[0220]
处理不可线性分离数据的第二种方式是核方法(boser,b.e.等人,上面引用)。它将输入的特征空间转换为更高维度的空间。通过这样做,数据可以是可线性分离的(图3b)。将映射函数表示为则核函数k可写为:
[0221][0222]
存在可用的核函数类型集。这里列出了最常见的类型:
[0223]
线性核
[0224]
k(xi,xj)=x
it
xj+c
[0225]
多项式核
[0226]
k(xi,xj)=(αx
it
xj+c)d[0227]
高斯(rbf)核
[0228]
k(xi,xj)=exp(-γ||x
i-xj||)
[0229]
通常,核技巧和软边际一起用于产生分类问题的更好解决方案。
[0230]
将svm应用于纳米孔数据以获得分数丰度具有以下步骤:1)加载对照和未知数据集,包括每个集的所有事件;2)特性选择;3)模型训练和测试;4)数据校准;5)预测和在所提供的实例中,更详细地说明了这5个步骤的应用。等式(3)和(4),包括核类型、软边际常数和核函数可能依赖的任何参数的超参数网格搜索,作为应用该方法的部分而求解。基于从svm生成的广义模型(包括共同决策边界和共同校准比率)的测定可以应用于未知混合物而不需要对照数据集。
[0231]
基于从svm生成的广义模型(包括共同决策边界和共同校准比率)的测定可以应用于未知混合物而不需要对照数据集。其他数据挖掘方法,包括决策树、神经网络、native bayer、逻辑回归、k-最近邻和增强,也被称为纳米孔数据的适用方法。
[0232]
emgm方法(高斯混合的期望最大化算法)
[0233]
在一些实施方案中,应用聚类方法以创建用于标记目标事件和参照事件的标准。每个事件标记为目标事件或参照事件。在一些实施方案中,分数丰度是目标事件相对于目标和参照事件的总和的比例。运行提供补偿信息的对照允许进行调整以改进分数丰度的估计值。
[0234]
在一些实施方案中,聚类方法是应用于一个或多个事件参数的分布的参数化模型的最大似然方法。最大似然估计对对照集的迭代应用导致拟合的模型参数,其中一个分布集与目标分析物类型相关和另一个分布集与参照分析物类型相关。随后,将参数化模型应用于未知混合物导致将事件分配给目标或参照分布,以及分配给目标分布的事件与分配给目标加参照分布的事件总数的比率用于生成分数量估计值。
[0235]
对数似然函数用作算法迭代中跟踪进度的度量,其递归地更新对照数据中每个事件的成员身份分配,并改善分布对数据的拟合。在一些实施方案中,使用参数化高斯分布的混合来对数据建模。使用有限混合模型(包括高斯混合模型)来表征数值数据的方法在统计学和应用数学中得到了很好的表征(hand,david j.,heikki mannila和padhraic smyth,principles of data mining.mit press,2001)。
[0236]
在一些实施方案中,给定高斯混合(gm)模型,该方法相对于包括分量的均值和协方差以及混合系数的参数使似然函数最大化。由于对于对数似然没有封闭形式的解,因此使用期望最大化(em)技术(c.m.bishop,pattern recognition and machine learning,springer,2006)迭代地计算用于将数据分配给模式的模式参数和权重。
[0237]
为了产生分数丰度估计值的目的,将em算法应用于gm模型的应用于纳米孔数据的方法被称为emgm。与q检验方法类似,emgm方法使用关于一个或多个纳米孔事件特征的先验知识,其可用于将目标事件与参照事件区分开。
[0238]
如上所述,目标群体可以由单一分布或多于一个分布表示。同样,参照群体可以由单一分布或多于一个分布表示。通过将算法应用于一个或多个分离的对照和一个或多个对照混合物来建立目标和参照分布。
[0239]
随后,在建立目标分布之后,如果未知混合物中的事件与建模的目标分布相关,则将该事件标记为目标事件。
[0240]
举例来说,总共三个高斯分布可以拟合1:1对照混合物中的整个数据集,其中一个模式与目标类型相关和两个模式与参照类型相关。
[0241]
对于emgm的应用,该算法仅需要一个对照混合物。随后,所得模型可应用于未知混合物。在一些实施方案中,使用另外的分离的参照对照来抵消假阳性的影响。具体而言,将emgm模型应用于100%参照对照建立了假阳性分数,其从通过将emgm模型应用于未知混合物而产生的预测分数中减去。这一减去可以称为假阳性补偿(或“fp”补偿)。
[0242]
实现多孔一致调用(consensus call)的实施方案
[0243]
在一些应用中,以上和以下所描述的系统的实施方案可从多个孔产生目标样品组分的分数丰度和/或浓度的估计值,以产生更准确的分数丰度和/或浓度估计值。因此,可以组合地处理来自(例如,一个或多个纳米孔装置的)单个孔的输出以产生分数丰度和/或浓度的改进的估计值。特别地,分数丰度和/或浓度的估计值可以由具有有助于估计值产生的来自一个或多个纳米孔的结果的处理不同等份的共同样品(即,来自对照,来自未知混合物)的单个或多个微流体纳米孔装置(例如,消耗品)产生。
[0244]
一种或多种方法因此可以包括以下一者或多者:在一个或多个纳米孔装置中跨一组纳米孔施加电压以对于包含目标分析物和参照分析物的单元的样品的部分产生可检测的电子特征并诱导带电分析物通过该组纳米孔的移位;由目标分析物和参照分析物的单元通过该组纳米孔的移位产生一组事件特征;从该组事件特征生成对应于该组纳米孔并且与目标分析物的分数丰度相关联的一组参数;在根据对应的阈值条件评估该组参数中的每一个时生成一组验证的参数,其中对应的阈值条件中的每一个是基于在该组参数的值上确定的可变性的度量的函数,并且其中生成验证的该组参数包括保留满足对应的阈值条件的参数值;将(验证的)该组参数的值与参数组合操作相结合;以及基于参数组合操作的输出返回目标分析物的分数丰度的估计值,如下文更详细描述的。
[0245]
图15a描绘了使用来自任意数目的纳米孔孔隙的一致调用来确定样品中目标分析物的分数丰度的方法的流程图。如图15a所示,与纳米孔装置(例如,如下所述的纳米孔装置的实施方案)相关的计算系统接收与纳米孔装置的一组孔对应的一组孔参数1510。该组孔参数可以源自与该组孔连通的电极的电信号(例如,电流测量值)输出,其中电信号可用于如上所述确定[t]和[r],以确定相对和分数丰度估计值;然而,在可选的实施方案中,该组孔参数可以另外地或可选地源自其它信号。
[0246]
计算系统然后根据一种或多种阈值条件评估该组孔参数中的每一个1520。阈值条件可以包括基于源自多个孔的输出的阈值条件。例如,可以使用该组孔中的两个或更多个孔上可变性的统计学度量来设计用于评估每个孔的输出是否应当与其它孔输出组合处理以确定分数丰度的估计值的阈值条件。可变性的统计学度量可以包括以下一种或多种或由其得到:多个孔上的参数值的范围(例如,四分位距)、多个孔上的参数值的方差、多个孔上的参数值的标准差以及任何其他合适的统计学或非统计学度量。在其他实施方案中,阈值条件可以以使得每个孔独立于其他孔的输出来评估的方式配置。
[0247]
如图15a所示,计算系统然后基于该组孔参数的评估将满足它们各自的阈值条件的孔参数的子集与参数组合操作相结合1530。参数组合操作可输出从满足其各自阈值条件的孔参数的子集确定的平均参数值(例如,平均值、中值、众数)。在一些实施方案中,平均参数值可以是加权平均,其中给予用于计算加权平均的每个参数的权重可以基于步骤1520的基于阈值的比较(例如,对应阈值条件的满足程度)来确定。在一个实施方案中,参数值和它们各自的阈值条件之间的距离可用于确定权重。例如,较小程度地满足阈值条件的参数值
可以被给予较小的权重,而较高程度地满足阈值条件的参数值可以被给予较大的权重。
[0248]
如图15a所示,计算系统然后基于步骤1530的参数组合操作的输出返回分数丰度估计值1540,其中分数丰度估计值描述样品中的目标分析物与目标分析物和参照分析物的总群体相比的百分比,如上所述。与图15a中描述的那些类似的方法也可用于确定目标样品组分的浓度,如以下与图15d相关的实例中更详细描述的。
[0249]
图15b描述了使用来自纳米孔装置的四个孔的一致调用来确定样品中目标分析物的丰度分数的实施方案,其中图15b是图15a所示方法的更具体的实施方案。如图15b所示,源自四个纳米孔的输出(例如,电信号或其它测量值)用于产生参数值p1、p2、p3和p4,并通过计算系统的逻辑按从最小到最大的顺序排列。然后,计算系统的逻辑将四分位距(iqr)定义为p3-p2,且实施一系列阈值条件以确定哪些(如果p1、p2、p3和p4值中的任何一个)应通过用于进一步分析。
[0250]
在第一评估1501中,计算系统将iqr除以参数值p2和p3的平均值与第一阈值进行比较,并且如果iqr/均值(p2,p3)大于第一阈值,则确定实验失败(并且因此,应当丢弃p1、p2、p3和p4)。然而,如果iqr/均值(p2,p3)小于或等于第一阈值,则p2和p3通过用于进一步分析,并且计算系统根据它们各自的阈值条件来评估p1和p4。
[0251]
在第二评估1502中,计算系统将p1与定义为p2、iqr和x的函数的第二阈值进行比较,其中x是常数。如图15b所示,第二阈值被定义为p2-x*iqr,其中在特定实例中,x的值被设置为1.5。如果p1小于第二阈值,则应丢弃p1;然而,如果p1大于或等于第二阈值,则p1应通过用于进一步分析。
[0252]
在第三评估1503中,计算系统将p4与定义为p3、iqr和y的函数的第三阈值进行比较,其中y是常数。如图15b所示,第三阈值被定义为p3+y*iqr,其中在特定实例中,y的值被设置为1.5。然而,在其他实施方案中,x和y不必彼此相同,并且第二和第三阈值可以以另一合适的方式定义。如果p4大于第三阈值,则p4应当丢弃;然而,如果p4小于或等于第二阈值,则p4应通过用于进一步分析。
[0253]
如图15b所示,通过它们各自的阈值的p1、p2、p3和p4的值被组合1504(例如,通过确定平均值,通过确定加权平均值)。在其中确定加权平均的实施方案中,分别对应于p1、p2、p3和p4的加权值w1、w2、w3和w4用于产生加权平均值。
[0254]
图15c描绘了由图15b的系统的实施方案实施的方法的流程图。更详细地,图15c表示用于评估来自多个纳米孔的参数值作为输入的调用,并在有或没有置信值的情况下返回输出(例如,平均参数值)的逻辑的架构。该架构可以处理形式[p1,p2,
…
,pn]的输入阵列和返回形式(状态,结果)的输出,其中状态指示置信度的量度(例如,状态0指示没有返回的输出,状态1指示没有置信度的返回的输出,并且状态2指示具有置信度的返回的输出),并且结果是从多个纳米孔确定的组合参数值(例如,平均参数值、加权平均参数值)。在结果是平均值参数的实施方案中,该平均值可以是算术平均值、几何平均值、加权平均值和/或任何其他合适的平均值或组合函数。
[0255]
更详细地,对于长度为零的输入阵列1511,逻辑提供返回的输出(0,0)。对于长度为1的输入阵列1512,逻辑提供返回的输出(1,x),其中x是输入阵列中的参数的值。对于长度为2的输入阵列1513,逻辑将两个参数值之间的差与阈值条件进行比较,并且如果满足阈值条件,则提供返回的输出(2,均值(x)),其中均值(x)是输入阵列中的两个参数的平均值。
然而,如果不满足阈值条件,则逻辑提供返回的输出(1,均值(x))。
[0256]
对于长度大于2的输入阵列,逻辑确定阵列的iqr,并基于iqr处理落在所需范围内的阵列的子集1514,其中图15c中的所需范围基于阵列中的第25和第75四分位参数值确定。如果子集的长度小于原始阵列的长度的一半,则逻辑提供返回的输出(1,均值(x_good)),其中x_good是落在所需范围内的阵列的子集。如果子集的长度小于原始阵列的长度的一半,则逻辑进入模式1516,其中如果阵列子集的最大值和最小值之间的差大于阈值(th),并且阵列的iqr值的最大值和最小值之间的差大于th,则逻辑提供返回的输出(1,均值(x_in_iqr)),其中x_in_iqr表示落入iqr内的输入阵列的值。如果阵列子集的最大值和最小值之间的差大于th,但是阵列的iqr值的最大值和最小值之间的差不大于th,则逻辑确定阵列的iqr值的值长度是否大于1,并且如果是,则提供返回的输出(2,均值(x_in_iqr))。然而,如果阵列的iqr值的值长度不大于1,则逻辑提供返回的输出(1,均值(x_in_iqr))。
[0257]
最后,如果阵列子集的最大值和最小值之间的差不大于阈值(th),则逻辑确定子集的长度是否大于1,并且如果大于1,则提供返回的输出(2,均值(x_good))。如果子集的长度不大于1,则逻辑提供返回的输出(1,均值(x))。
[0258]
在一个实例中,对于[]的输入阵列,逻辑输出(0,0)的(状态,结果),其中因为没有输入纳米孔数据,没有返回的输出。在另一实例中,对于[0]的输入阵列,逻辑输出(1,0)的(状态,结果),其中返回的输出具有结果0和状态1(非置信的,假定有来自仅一个纳米孔的数据)。在另一实例中,对于[0,0]的输入阵列,逻辑输出(2,0)的(状态,结果),其中返回的输出具有结果0和状态2(置信的,假定两个纳米孔返回相同的值0)。在另一实例中,对于[30]的输入阵列,逻辑输出(1,30)的(状态,结果),其中返回的输出具有结果30和状态1(非置信的,假定有来自仅一个纳米孔的数据)。在另一实例中,对于[30,31]的输入阵列,逻辑输出(2,30.5)的(状态,结果),其中返回的输出具有30.5的结果和2的状态(置信的,假定来自两个纳米孔的数据值相对于阈值条件是接近的)。在另一实例中,对于[30,100]的输入阵列,逻辑输出(1,65.0)的(状态,结果),其中返回的输出具有65.0的结果和1的状态(非置信的,假定来自两个纳米孔的数据值相对于阈值条件广泛地分离)。在另一实例中,对于[30,31,100]的输入阵列,逻辑输出(2,30.5)的(状态,结果),其中返回的输出具有30.5的结果和2的状态(置信的,假定来自两个纳米孔的数据值相对于阈值条件是接近的,且来自第三纳米孔的数据值被处理为离群值)。在另一实例中,对于[30,31,32,33,34,35,36]的输入阵列,逻辑输出(2,33.0)的(状态,结果),其中返回的输出具有33.0的结果和2的状态(置信的,假定来自所有纳米孔的数据值相对于阈值条件是接近的)。在另一实例中,对于[30,31,32,33,34,100,98]的输入阵列,逻辑输出(2,32.0)的(状态,结果),其中返回的输出具有32.0的结果和2的状态(置信的,假定来自许多纳米孔的数据值相对于阈值条件是接近的,并且来自两个纳米孔的数据值被处理为离群值)。
[0259]
因此,所描述方法的实施方案可以使用基于其它可变性度量的任何合适的阈值条件应用于源自任何合适数目的纳米孔的信息。
[0260]
此外,如上所述,关于图15a-15c描述的方法的方面可以适用于使用源自多个孔的信息来确定目标分子的浓度。图15d描述了使用源自多个纳米孔的信息确定目标分子浓度的方法的输出。更详细地,与图15d中所示的输出相关,系统的实施方案使用源自多个纳米孔的信息确定目标样品组分(例如,分子、其它分析物)相对于浓缩物浓度的特定校准物分
子的相对捕获速率,并且将相对捕获速率与目标样品组分的浓度相关联,以便使用源自多个纳米孔的信息确定目标样品组分的浓度。
[0261]
在具体实例中,其输出描绘于图15d中,74bp dna(目标分子)相对于浓度为0.5nm的217bp校准物分子的相对捕获速率用于确定用不同浓度的74bp dna(例如,0.5nm至15nm的浓度)制备的样品中74bp dna的浓度。通过使用具有(0,0)边界条件的1、2或7个对照数据点来拟合线性曲线,该具体的示例情况由事件数的比率导出目标分子的浓度。图15d中描述的输出显示了使用1、2或7个对照数据点,并使用来自单个纳米孔对多个纳米孔的预测的不同目标分子浓度的估计值中的百分比误差。如图15d(上图)所示,74bp dna目标分子的浓度与使用217bp校准物分子的捕获事件数量的比率之间存在线性相关性。如图15d(中间和下图)所示,与使用来自单个纳米孔的数据的目标分子实际浓度的估计值相比,使用来自多个纳米孔的数据通常在0.5nm、1nm、3nm、5nm、7nm、10nm和15nm的浓度下在目标分子的实际浓度的估计值中产生较低的百分比误差,尤其是随着对照数据点的数目增加。
[0262]
基于孔条件和数据质量预过滤来自纳米孔的数据
[0263]
与使用来自多个纳米孔的数据来确定估计值(例如,分数丰度的估计值、浓度的估计值)相关,系统和相关的计算逻辑的一些实施方案还可配置为省略纳米孔来源的信息的使用(例如,在使用多孔一致调用执行计算之前),因为取决于纳米孔本身的质量(例如,低频或高频噪声、包括均方根噪声的汇总噪声统计、孔直径、实验期间的生长速率等)的其它原因,其在算法上可以是自动的。因此,方法可以包括基于来自纳米孔组的纳米孔的数据的质量评估从考虑中省略来自该纳米孔的数据。
[0264]
特别地,系统可以评估时域中的选定时段(例如,每5秒)的低频噪声含量(例如,在0.1-10hz范围上的平均/中值噪声功率,其中《-50db/hz是可接受的),并且省略对与高于阈值水平的低频噪声含量相关的源自纳米孔的信息的使用。该系统可以另外地或可选地评估在时域中的选定时段(例如,每5秒)的高频噪声含量(例如,0.5-30khz范围上的平均/中值噪声功率),并且省略与高于阈值水平的高频噪声含量相关的源自纳米孔的信息的使用。系统可以另外地或可选地评估在时域中的选定时段(例如,每5秒)的汇总噪声含量(例如,时域信号的rms,在30khz下《20pa是可接受的),并且省略与高于阈值水平的汇总噪声含量相关的源自纳米孔的信息的使用。
[0265]
该系统还可以评估孔直径(或其他孔形态特征)和/或在时域中的选定时段(例如,每5秒)上孔特征的变化速率,其中《0.25nm/min是可接受的,并且省略源自与阈值范围之外的形态特征相关和/或与阈值范围之外的孔特征的变化速率相关的纳米孔的信息的使用。特别地,随时间测定纳米孔直径的方法可以包括使用电流i和电压v作为g=i/v测量的开放通道电导模型的实施。具体地,g在每对事件之间被计算为平均电流除以电压。用于g的第一模型忽略任何接入电阻对总电阻的贡献(总电阻是总电导的倒数),并且如下取决于纳米孔直径d和膜厚度l:g1(d)=σ(πd2)/(4l),其中σ是本体电解质电导率。当d/l《3/4时,第一模型匹配电导vs纳米孔直径数据。第二模型结合了接入电阻的影响并匹配所有报告的d/l值(即,小于和大于1)的数据,条件是膜厚度l被有效厚度l=l/α,α≥1代替,启发式地作为适应纳米孔处的膜变薄的方式。该模型为:g2(d,l)=σ(πd2)/(4l)[1/(1+(πd)/(4l)]。
[0266]
对于在实验的时间过程中记录的g的给定范围,可以通过将该范围与建模的值进行比较来确定哪个模型更合适;然而,对于α的选择(尽管是启发式的)对估计的d2值具有显
著影响。在实验过程中g=i/v的值通常随时间缓慢增加。如果观察到增加,则有两个潜在来源。第一,纳米孔可以随时间扩大,从而允许流动电流量增加;这对于较不“稳定”的孔(即,由于一个原因或另一个原因而易碎,或由于膜非常薄和/或由于施加可蚀刻掉膜材料的较高电压而可生长的膜中的孔)以较高速率发生。第二,这种增加可能是由于水的蒸发和在添加试剂的纳米孔上方的“开放”腔室中离子浓度的补偿性相对增加。可以通过更换暴露的腔室中的缓冲液和重新测量电导来测试这些来源中的哪一个在发挥作用-如果该值返回到原始值,孔尺寸和形状可能保持完整;如果该值较高,孔可能扩大。总之,使用已知的l,如果d/l《3/4,则可以使用第一模型g1(d)来估计直径。否则,第二模型可用于估计直径。
[0267]
该系统还可以评估样品质量含量(quality content),且省略源自纳米孔的信息和省略源自与不良样品质量含量相关的纳米孔的信息的使用(例如,在实施图15a和15b中所示的方法之前)。系统可以通过每单位时间的捕获率或事件率(高于下阈值,例如每分钟1个事件,并且高于上阈值,例如每分钟10000个事件)以通量来评估样品质量内容。
[0268]
该系统可以根据存在多于一个物质(包括可能存在的一种或多种未知物以及存在的一种或多种对照)的样品的群体分离的量来评估样品质量含量。在一个实例中,样品包括一种对照或参考组分,和一种以高于最小分数(例如2%)存在的未知/目标样品组分。在处理这样的样品时,系统从分割样品内的群体的模型估计(例如,基于svm的模型)来确定分离度量的值。模型的分离度量输出的值可以包括距离值(例如,一个事件群体的质心到参考分离边界/超平面的最短距离)或任何其他合适的分离度量。
[0269]
在评估样品质量含量的一个实例中,根据图16a中描绘的以下步骤用通用模型评估s2样品的50:50混合物(0%,100%,如上所述)。如图16a所示,由系统实现的通用模型的方法1600首先确定样品群体(例如,50:50混合物的群体)是否在目标区域内1610,以便从考虑中过滤或去除来自产生差质量数据(例如,就纳米孔尺寸而言,就异常纳米孔形态而言,就与样品处理测定的异常相互作用而言,与样品和/或样品处理材料的检测污染相关,等等)的纳米孔的信息。图16b描绘了步骤1620的输出,其中与用于处理样品的不同试剂(即,0%s-腺苷甲硫氨酸,100%s-腺苷甲硫氨酸)相关,来自纳米孔的事件数据按照电信号幅度对停留时间作图。在生成图16b的图时,系统从所有群体收集事件数据,并定义目标区域,在该目标区域之外事件被分类为噪声。然后,该系统基于实际事件对由目标区域定义的噪声事件的数量来确定每个纳米孔的噪声百分比的量度,并且如果特定纳米孔的噪声百分比大于阈值,则从考虑中去除来自该特定纳米孔的数据。因此,该系统定义了将纳米孔数据中的噪声事件子集与实际事件子集分离的目标区域边界,并基于噪声事件子集和实际事件子集确定噪声百分比。然而,与评估纳米孔噪声百分比相关,步骤1610的其它实施方案可以以另一种方式实施。
[0270]
如图16a所示,系统然后评估样品群体的组分的分离1620,以便提供用于从考虑中过滤或去除来自产生差质量数据(例如,就与样品处理测定的异常相互作用而言,与样品和/或样品处理材料的检测污染相关等)的纳米孔的信息的另一步骤。在实施步骤1620时,系统可以对以下的一个或多个执行主成分分析(pca)操作:停留时间(例如,样品组分相对于纳米孔的停留时间)、纳米孔的电信号输出的中值幅度、纳米孔的电信号输出的最大幅度、纳米孔面积和任何其它合适的纳米孔相关因素。特别地,pca操作实现将数据从第一坐标系变换到第二坐标系的变换(即,正交线性变换),使得数据的某些投影的最大方差位于
第二坐标系的第一坐标上(即,第一分量)。第二最大方差位于第二坐标上,和第三最大方差位于第三坐标上。因此,pca操作将数据映射到与数据中的不同方差水平相关的新坐标上。在使用pca分量而不是单一参数的值(例如,停留时间、纳米孔的电信号输出的中值幅度、纳米孔的电信号输出的最大幅度、纳米孔面积等)时,系统可以有效地评价数据中的分离,而不管单一参数的值的重叠。
[0271]
因此,系统使用pca操作的第一分量来检查样品群体的分离(例如,与表示每个样品群体的高斯分布相关)。在检查样品群体的分离时,系统可以将分离评分定义为:ss=(u1-u2)/(s1+s2),其中u1和u2是高斯分布的相应平均值(u2》u1),并且s1和s2是高斯分布的相应标准偏差。然后相对于阈值评估分离评分ss以确定分离水平是否合适。图16c描绘步骤1620的输出(使用图16b的相同样品和样品群体),其中系统使用pca运算的分量(pc1和pc2)来产生每一样品群体的计数对pc1的高斯分布。如图16d所示,系统确定样品群体的分离评分ss=(u1-u2)/(s1+s2)为2.4,并且假设阈值分离大于预定阈值,系统继续评价从纳米孔产生的数据。然而,步骤1620的其他实施方案可以以另一种方式来实施,与评估样品的群体分离相关。
[0272]
如图16a所示,系统然后通过实施通用模型(例如,包括可独立地和/或协作地工作的预构建模型和聚类方法的通用模型)以生成样品的校准比的预测来确定样品群体的校准比是否在目标范围内1630。如图16e所示,为了检查样品的50:50校准比是否在目标范围内,系统使用通用模型针对以秒计的停留时间的对数底数-10产生以纳安培计的来自纳米孔的电流的最大幅度(max_amp(na))的输出。在图16e中,类标记s20%和100%代表不同的样品群体,并且通用模型输出%(s2_100%)为68.91%,其用于检查50:50校准比。然而,步骤1630的其他实施方案可以以另一种方式来实施,与样品校准比的检查相关。
[0273]
纳米孔装置
[0274]
所提供的纳米孔装置包括在将装置的内部空间分为两个容积的结构中形成开口的至少一个孔,以及至少一个配置为识别通过孔的物体(例如通过检测指示物体的参数的变化)的传感器。用于本文所描述的方法的纳米孔装置也在pct公开wo/2013/012881中公开,其通过引用整体并入。
[0275]
纳米孔装置中的孔是纳米级或微米级的。在一个方面,每个孔的大小允许小或大分子或者微生物通过。在一个方面,每个孔直径至少约1纳米。可选地,每个孔直径至少约2nm、3nm、4nm、5nm、6nm、7nm、8nm、9nm、10nm、11nm、12nm、13nm、14nm、15nm、16nm、17nm、18nm、19nm、20nm、25nm、30nm、35nm、40nm、45nm、50nm、60nm、70nm、80nm、90nm或100nm。
[0276]
在一个方面,孔直径不超过约100nm。可选地,孔直径不超过约95nm、90nm、85nm、80nm、75nm、70nm、65nm、60nm、55nm、50nm、45nm、40nm、35nm、30nm、25nm、20nm、15nm或10nm。
[0277]
在一个方面,孔的直径在约1nm至约100nm之间,或者在约2nm至约80nm之间,或约3nm至约70nm之间,或约4nm至约60nm之间,或约5nm至约50nm之间,或约10nm至约40nm之间,或约15nm至约30nm之间。
[0278]
在一些方面,纳米孔装置进一步包括用于将聚合物骨架移动跨过孔的手段和/或用来识别通过孔的物体的手段。进一步的细节在下面提供,以双孔装置为背景描述。
[0279]
与单孔纳米孔装置相比,双孔装置可以更容易配置以提供聚合物骨架跨孔运动的速度和方向的良好控制。
[0280]
在一个实施方案中,纳米孔装置包括多个腔室,各腔室通过至少一个孔与相邻的腔室连通。在这些孔中,两个孔,即第一孔和第二孔,被布置为使得允许至少一部分靶多核苷酸移出第一孔并进入第二孔。此外,所述装置在每个孔处包括能够在运动过程中识别目标多核苷酸的传感器。在一个方面,该识别需要确定目标多核苷酸的单个成分。在另一个方面,该识别需要确定与目标多核苷酸结合的有效负载分子。当采用单一传感器时,该单一传感器可包含两个放置在孔两端以测量跨孔的离子电流的电极。在另一个实施方案中,单一传感器包含电极以外的部件。
[0281]
在一个方面,所述装置包括通过两个孔连接的三个腔室。具有三个以上腔室的装置可以很容易地设计以在三腔室装置任一侧或在三个腔室中任何两个腔室之间包括一个或多个额外的腔室。同样地,装置中可以包括连接腔室的超过两个孔。
[0282]
在一个方面,两个相邻腔室之间可以有两个或更多个孔,以允许多个聚合物骨架同时从一个腔室移动到下一个腔室。这样的多孔设计可以提高装置中目标多核苷酸分析的通量。对于多路复用,一个腔室可以具有一种类型的目标多核苷酸,且另一个腔室可以具有另一种目标多核苷酸类型。
[0283]
在一些方面,所述装置进一步包括用于将目标多核苷酸从一个腔室移动到另一个腔室的手段。在一个方面,该移动导致同时跨第一孔和第二孔两者加载目标多核苷酸(例如,包含靶序列的扩增产物或扩增子)。在另一个方面,所述手段进一步使目标多核苷酸能够在相同方向上通过两个孔移动。
[0284]
例如,在三腔室两孔装置(“两孔”装置)中,每个腔室可以包含用于连接到电源的电极,从而可以跨腔室之间的各个孔施加单独的电压。
[0285]
根据本发明的一个实施方案,提供了包括上腔室、中腔室和下腔室的装置,其中上腔室通过第一孔与中腔室连通,且中腔室通过第二孔与下腔室连通。这种装置可以具有此前在名称为双重孔装置(dual-pore device)的美国公开no.2013-0233709中公开的任何尺寸或其他特征,该文献在此通过引用整体并入本文。
[0286]
在一个方面,每个孔的直径为至少约1nm。或者,每个孔的直径为至少约2nm、3nm、4nm、5nm、6nm、7nm、8nm、9nm、10nm、11nm、12nm、13nm、14nm、15nm、16nm、17nm、18nm、19nm、20nm、25nm、30nm、35nm、40nm、45nm、50nm、60nm、70nm、80nm、90nm或者100nm。
[0287]
在一个方面,每个孔的直径不超过约100nm。或者,孔的直径不超过约95nm、90nm、85nm、80nm、75nm、70nm、65nm、60nm、55nm、50nm、45nm、40nm、35nm、30nm、25nm、20nm、15nm或10nm。
[0288]
在一个方面,孔的直径在约1nm至约100nm之间,或者约2nm至约80nm之间,或约3nm至约70nm之间,或约4nm至约60nm之间,或约5nm至约50nm之间,或约10nm至约40nm之间,或约15nm至约30nm之间。
[0289]
在一些方面,孔基本上呈圆形。本文所用的“基本上圆形”是指至少约80或90%为圆柱体形式的形状。在一些实施方案中,孔形状为方形、矩形、三角形、椭圆形或六角形。
[0290]
在一个方面,孔的深度介于约1nm至约10,000nm之间,或者在约2nm至约9,000nm之间,或在约3nm至约8,000nm之间,等。
[0291]
在一些方面,纳米孔穿过膜延伸。例如,孔可以是插入脂质双层膜中的蛋白质通道,或者其也可以通过钻孔、刻蚀或以其他方式通过固态基质(如,二氧化硅、氮化硅、石墨
烯或由这些或其他材料的组合形成的层)形成孔来工程化。纳米孔的大小设计为允许骨架:融合体:有效负载,或该分子在酶活性之后的产物通过孔。在其它实施方案中,孔的临时阻塞对于区分分子类型可能是有利的。
[0292]
在一些方面,纳米孔的长度或深度足够大,从而形成连接两个在其它方面分隔的容积的通道。在一些此类方面,每个孔的深度大于100nm、200nm、300nm、400nm、500nm、600nm、700nm、800nm或900nm。在一些方面,每个孔的深度不超过2000nm或1000nm。
[0293]
在一个方面,孔以约10nm至约1000nm之间的距离分隔开。在一些方面,孔之间的距离大于1000nm、2000nm、3000nm、4000nm、5000nm、6000nm、7000nm、8000nm或9000nm。在一些方面,孔间隔不超过30000nm、20000nm或10000nm。在一个方面,该距离为至少约10nm,或者至少约20nm、30nm、40nm、50nm、60nm、70nm、80nm、90nm、100nm、150nm、200nm、250nm或300nm。另一方面,该距离不超过约1000nm、900nm、800nm、700nm、600nm、500nm、400nm、300nm、250nm、200nm、150nm或100nm。
[0294]
而在另一方面,孔之间的距离在约20nm至约800nm之间,约30nm至约700nm之间,约40nm至约500nm之间,或约50nm至约300nm之间。
[0295]
两个孔可以以任何位置排列,只要它们允许腔室之间的流体连通并具有规定的大小和间距。在一个方面,孔布置为使得它们之间没有直接阻碍。仍然在一个方面,孔基本上是同轴的。
[0296]
在一个方面,该装置在腔室中具有连接到一个或多个电源的电极。在一些方面,电源包含电压钳或膜片钳,其可以提供跨各孔的电压并独立地测量通过各孔的电流。在这个方面,电源和电极配置可以将中腔室设置成两个电源的共同地线。在一个方面,一个或多个电源配置为在上腔室(腔室a)和中腔室(腔室b)之间施加第一电压v1,和在中腔室和下腔室(腔室c)之间施加第二电压v2。
[0297]
在一些方面,第一电压v1和第二电压v2是可独立调节的。在一个方面,中腔室被调节为相对于两个电压的地电压。在一个方面,中腔室包含用于在各个孔和中腔室中的电极之间提供电导的介质。在一个方面,中腔室包含用于在各个孔和中腔室中的电极之间提供电阻的介质。保持相对于纳米孔电阻足够小的这种电阻可用于对跨孔的两个电压和电流解耦,这有助于电压的独立调节。
[0298]
电压的调节可用于控制腔室内带电颗粒的运动。例如,当两个电压设置为极性相同时,适当带电的颗粒可以从上腔室顺序地移动到中腔室和到下腔室,或者反过来。在一些方面,当两个电压被设置成相反极性时,带电颗粒可以从上腔室或下腔室移动到中腔室并保持在那里。
[0299]
装置中电压的调节可以特别地用于大分子如带电聚合物骨架的运动的控制,该大分子足够长以同时跨两个孔。在这个方面,分子移动的方向和速度可以通过电压的相对幅度和极性来控制,如下所述。
[0300]
所述装置可以包含适合容纳液体样品(特别是生物样品)的材料和/或适合于纳米加工的材料。在一个方面,此类材料包括介电材料,例如但不限于硅、氮化硅、二氧化硅、石墨烯、碳纳米管、tio2、hfo2、al2o3或其它金属层,或这些材料的任何组合。在一些方面,例如,约0.3纳米厚的单片石墨烯膜可用作孔承载膜。
[0301]
作为微流体装置且容纳双孔微流体芯片实施方式的装置可以通过多种手段和方
法来制造。对于由两个平行的膜构成的微流体芯片,两个膜可以同时通过单波束钻孔以形成两个同心孔,尽管与任何适合的校准技术协同在膜的各侧使用不同的波束也是可能的。概括地说,外壳确保腔室a-c的密封分隔。
[0302]
在一个方面,所述装置包含微流体芯片(标记为“双孔芯片”),其由通过间隔体连接的两个平行的膜构成。每个膜包含通过膜中心用单波束钻孔形成的孔。进一步,所述装置优选具有用于芯片的外壳或聚碳酸酯外壳。外壳确保腔室a-c的密封分隔,并为电极提供最小接入电阻以确保每个电压主要跨各孔施加。
[0303]
更具体地,孔承载膜可以用具有5-100纳米厚的硅、氮化硅或二氧化硅窗口的透射电子显微(tem)格栅制造。间隔体可采用绝缘体(如su-8、光刻胶、pecvd氧化物、ald氧化物、ald氧化铝)或蒸镀的金属材料(如银、金或铂),且占据在膜之间的腔室b的其它为水性的部分中的小空间而用于分隔膜。支持器置于由腔室b的最大体积部分构成的水性浴中。腔室a和c可以通过较大直径的通道(对于低接入电阻)达到,这导致膜密封。
[0304]
聚焦的电子或离子束可以用来通过膜钻孔,从而使其自然对准。孔也可以通过施加聚焦于每个层的适当束来雕刻(收缩)达到较小尺寸。任何单一纳米孔钻孔方法也可以用来在两个膜中钻出孔对,考虑对于给定方法可能的钻孔深度和膜的厚度。预钻出微孔到规定的深度和然后通过膜的剩余部分钻出纳米孔对于进一步优化膜的厚度也是可能的。
[0305]
通过在装置的孔处存在的电压,带电分子可以通过腔室之间的孔移动。移动的速度和方向可以通过电压的大小和极性控制。此外,由于两个电压可以各自独立地调节,所以带电分子移动的方向和速度可以在各腔室中精细地控制。
[0306]
一个实例涉及目标多核苷酸,其长度大于包括两个孔的深度加两个孔之间的距离的综合距离。例如1000bp的dsdna长度约为340纳米,且显著大于间隔20纳米的两个10纳米深孔跨越的40纳米距离。第一步中,将多核苷酸加载到上腔室或下腔室中。通过其在ph约7.4的生理条件下的负电荷,多核苷酸可以跨被施加电压的孔移动。因此,第二步中,相同极性且大小相同或相近的两个电压施加于孔以顺序地跨两个孔移动多核苷酸。
[0307]
大致在多核苷酸到达第二孔的时候,可以改变一个或两个电压。由于两个孔之间的距离选择为比多核苷酸的长度短,当多核苷酸到达第二孔时,它也在第一孔中。因此,在第一孔处电压极性的迅速改变将产生将多核苷酸拉离第二孔的力。
[0308]
假设所述两个孔具有相同的电压-力影响,且|v1|=|v2|+δv,则值δv>0(或<0)可以进行调节以在|v1|(或v2)方向上获得可调节的运动。在实践中,虽然各个孔处电压诱导的力不会由于v1=v2而相同,校准实验可以确定对于给定的双孔芯片产生相等的拉力的适当偏置电压;且围绕该偏置电压的变化然后可以用于定向控制。
[0309]
如果,在此时,第一孔处电压诱导的力的大小小于第二孔处电压诱导的力的大小,则多核苷酸会继续跨越两个孔移向第二孔,但速度较低。在这个方面,容易理解,多核苷酸运动的速度和方向可以通过两个电压的极性和大小来控制。正如下面将进一步描述的,运动的这种精细控制有着广泛的应用。为了定量目标多核苷酸,双孔装置实施方式的效用是,在受控的递送和探测期间,可以重复地测量目标多核苷酸或有效负载结合的目标多核苷酸以增加检测结果的可信度。
[0310]
因此,在一个方面,提供了用于控制带电聚合物骨架通过纳米孔装置的运动的方法。所述方法包括(a)将包含目标多核苷酸(例如,目标多核苷酸扩增子)的样品加载到上述
任一实施方式的装置的上腔室、中腔室或下腔室之一中,其中该装置被连接到用于在上腔室与中腔室之间提供第一电压和在中腔室与下腔室之间提供第二电压的一个或多个电源;(b)设置初始第一电压和初始第二电压以使目标多核苷酸在腔室之间移动,从而使聚合物骨架跨第一和第二孔两者定位;且(c)调节第一电压和第二电压以使两个电压都产生将带电目标多核苷酸拉离中腔室的力(电压竞争模式),其中两个电压在受控条件下大小不同,以使得目标多核苷酸骨架沿任一方向且以受控的方式跨两个孔移动。
[0311]
在一个方面,将含目标多核苷酸的样品加载到上腔室中,且将初始第一电压设置为将目标多核苷酸从上腔室拉到中腔室,且将初始第二电压设置为将目标多核苷酸从中腔室拉到下腔室。同样地,样品可以被初始加载到下腔室中,且目标多核苷酸可以被拉到中腔室和上腔室。
[0312]
在另一方面,将含有目标多核苷酸的样品加载到中腔室中;将初始第一电压设置成将带电聚合物骨架从中腔室拉到上腔室;且将初始第二电压设置成将目标多核苷酸从中腔室拉到下腔室。
[0313]
在一个方面,在步骤(c)中第一电压和第二电压的实时或在线调节是采用专用的硬件和软件以高达数百兆赫的时钟频率通过主动控制或反馈控制进行的。第一电压或第二电压或两者的自动控制是基于第一或第二或两个离子电流测量值的反馈。
[0314]
传感器
[0315]
如上所述,在各个方面,纳米孔装置还包括一个或多个传感器用于完成目标多核苷酸的检测。
[0316]
所述装置中使用的传感器可以是任何适合用于识别与有效负载分子结合或未结合的目标多核苷酸扩增子的传感器。例如,传感器可以配置为通过测量与聚合物相关的电流、电压、ph值、光学特征或停留时间来识别目标多核苷酸。在其他方面,传感器可以被配置为识别目标多核苷酸的一个或多个单个组分或者与目标多核苷酸结合或连接的一个或多个组分。传感器可以由配置为检测可测量参数的变化的任何组件形成,其中此变化指示目标多核苷酸、目标多核苷酸的组分或优选与目标多核苷酸结合或连接的组分。在一个方面,传感器包括放置在孔两侧的一对电极以测量分子或其他实体(特别是目标多核苷酸)移动通过孔时的跨孔离子电流。在某些方面,在通过孔的目标多核苷酸片段结合于有效负载分子时,跨孔离子电流发生可测量的变化。此类电流变化可对应于,例如,存在的目标多核苷酸分子的存在、不存在和/或大小以可预测的、可测量的方式发生改变。
[0317]
在优选的实施方案中,传感器包括施加电压并用于测量跨纳米孔的电流的电极。分子转位通过纳米孔提供了电阻抗(z),其根据欧姆定律,v=iz,影响通过纳米孔的电流,其中v是施加的电压,i是通过纳米孔的电流,z是阻抗。相反,监测电导g=1/z以示意和定量纳米孔事件。在分子在电场中(例如,在施加的电压下)转位通过纳米孔时的结果是,当进一步分析电流信号时可能与通过纳米孔的分子相关的电流特征。
[0318]
当使用来自电流特征的停留时间测量时,可以基于通过探测装置所需的时间长度,将组分的大小与特定组分相关联。
[0319]
在一个实施方案中,在纳米孔装置中提供的传感器测量聚合物、聚合物的组分(或单元)或者结合或连接到聚合物的组分的光学特征。这种测量的一个实例包括通过红外(或紫外)光谱鉴定特定单元特有的吸收带。
[0320]
在一些实施方案中,传感器是电传感器。在一些实施方案中,传感器检测荧光特征。孔出口处的辐射源可用于检测该特征。
[0321]
等同和范围
[0322]
本领域技术人员将认识到或能够使用不超过常规的实验确定根据本文所述的本发明的具体实施方案的许多等同物。本发明的范围不意图限于以上描述,而是如所附权利要求中所示出。
[0323]
在权利要求中,诸如“一”、“一个”和“该”的冠词可以表示一个或多于一个,除非相反地指出或者从上下文中显而易见。如果组中的一个、多于一个或所有组成员存在于、用于或以其他方式与给定产品或过程相关,则认为包括组中一个或多个成员之间的“或”的权利要求或描述是满足的,除非另有相反说明或从上下文中显而易见。本发明包括其中该组的恰好一个成员存在于给定产品或过程中、在其中使用或以其他方式与给定产品或过程相关的实施方案。本发明包括其中多于一个或所有组成员存在于、用于或与给定产品或过程相关的实施方案。
[0324]
还应注意,术语“包含”旨在是开放的并且允许但不要求包括额外的元件或步骤。当在本文中使用术语“包含”时,因此也包括和公开了术语“由......组成”。
[0325]
在给出范围的情况下,包括端点。此外,应理解,除非另外指出或从本领域普通技术人员的上下文和理解中另外显而易见,否则表示为范围的值可以在所述范围内呈现任何特定值或子范围,达到范围下限的十分之一单位,除非上下文另有明确规定。
[0326]
所有引用的来源,例如,本文引用的参照文献、出版物、数据库、数据库条目和技术,通过引用并入本技术中,即使未在引文中明确说明。如果引用来源和本技术的陈述相互矛盾,则应以本技术中的陈述为准。
[0327]
章节和表格标题不旨在是限制性的。
[0328]
实施例
[0329]
以下是用于实施本发明的具体实施方案的实例。提供这些实施例仅用于说明目的,并不意图以任何方式限制本发明的范围。已经努力确保关于所使用的数字(例如,量、温度等)的准确性,但是当然应该允许一些实验误差和偏差。
[0330]
除非另有说明,否则本发明的实践将采用本领域技术范围内的蛋白质化学、生物化学、重组dna技术和药理学的常规方法。这些技术在文献中有充分说明。参见,例如t.e.creighton,proteins:structures and molecular properties(w.h.freeman and company,1993);a.l.lehninger,biochemistry(worth publishers,inc.,当前版本);sambrook等,molecular cloning:a laboratory manual(第2版,1989);methods in enzymology(s.colowick和n.kaplan编辑,academic press,inc.);remington's pharmaceutical sciences,18th edition(easton,pennsylvania:mack publishing company,1990);carey and sundberg advanced organic chemistry第3版(plenum press)vols a和b(1992)。
[0331]
实施例1
–
对于目标和参照使用不同长度dsdna的基于q-检验的fa
[0332]
该实施例提供了将分数丰度(fa)框架应用于其中转基因(gmo)目标序列在788bp目标dsdna(即,目标分析物)内和参照序列(凝集素管家基因)在466bp参照dsdna(即参照分析物)内的数据的结果。下面实现了样品中转基因目标的分数量的定量,首先通过应用具有
基于事件面积的单特征标准应用q-检验方法并且使用等式(1)和(2),及然后通过应用svm方法和使用等式(3)和(4)。
[0333]
使用序列特异性寡核苷酸引物通过pcr从常规和含转基因的基因组dna样品的混合物产生466bp参照dna和788bp目标转基因dna片段。使用标准的二氧化硅膜柱纯化和浓缩pcr产物。从大量单独产生的扩增子制备两种扩增子的精确分数混合物,并将等分的分数混合物和单一扩增子用作所有测定的标准参照材料。
[0334]
首先,在纳米孔装置中测量含有466bp参照dna的参照对照样品。接下来,制备含有788bp转基因dna的目标对照样品并在纳米孔装置中测量。目标分析物(788bp)和参照分析物(466bp)之间的长度差异在通过纳米孔移位时产生独特的事件特征,其可以基于事件特征的面积来区分。
[0335]
图4a显示了两个分离的对照运行的所有事件面积直方图,一个用于466bp参照dna,一个用于788bp目标转基因dna。还显示了来自3:10目标:参照对照混合物的面积直方图。图4b显示作为面积标准阈值q的函数的对照混合物(q
targ
,q
ref
)和已知混合物(q
mix
)趋势,其中q
mix
=q
3:10
。图4c示出了分数量参数ρ(q)如何在q值处以图形方式显现。q=5pa*ms阈值(垂直虚线)对应于0.05的假阳性(即,q
ref
=0.05)和0.1的假阴性(即,q
targ
=0.9)。
[0336]
使用对照混合物在这里应用等式(2)来生成作为预测的gmo(%),以测试使用仅参照和仅目标对照来生成已知混合物的分数丰度的估计值的方法的准确度和精确度。等式(2)首先应用于已知混合物。由于没有使用对照混合物样品来生成q
x:y
,因此在不使用目标分析物和参照分析物之间的捕获速率常数差异的补偿(即,设定α=1)的情况下生成估计值以验证模型。图5a示出了预测的gmo(%)vs.真实gmo(%)的曲线图,并且用于比较的零误差线(斜率=1)之上和之下10%误差容限。这些结果通过在单个纳米孔上连续运行100%目标和100%参照(分离的)对照,然后是五种已知混合物来建立。表1报告了图5a中绘制的预测值和误差棒,以及对于每种混合物检测的总事件数。
[0337]
表1.对于图5a数据的gmo预测结果
[0338]
真实gmo%预测gmo%百分误差(预测-真实)总事件10%12.0
±
1.07%2.0
±
1.0%5,22515%16.3
±
1.1%1.3
±
1.1%4,26720%20.8
±
1.1%0.75
±
1.1%6,60525%29.3
±
1.2%4.3
±
1.2%6,64730%34.5
±
1.4%4.4
±
1.4%5,605
[0339]
按照类似方案(两个分离的对照和六种已知混合物)进行单独的纳米孔实验,并产生图5b和表2中所示的结果。
[0340]
表2.对于图5b数据的gmo预测结果
[0341]
真实gmo%预测gmo%百分误差(预测-真实)总事件5%2.87
±
0.7%-2.1
±
0.7%4,78310%11.1
±
0.93%1.1
±
0.9%4,88415%16
±
1.1%1.0
±
1.1%4,326
20%20.4
±
1.1%0.35
±
1.1%5,89525%27.1
±
1.2%2.1
±
1.2%6,58733.33%36.2
±
1.3%2.8
±
1.3%7,862
[0342]
图5a和图5b以及表1和2的结果表明,对于使用单个纳米孔区分两个dna长度,5%内的gmo%预测准确度是可能的。这些结果在不使用目标分析物和参照分析物之间的捕获速率常数差异的补偿的情况下(在等式(2)中设定α=1)实现。预计捕获速率常数差异的补偿将进一步改善结果。
[0343]
图6中示出了当使用q阈值范围而不是单个值时的示例。具体地,q阈值范围选择为跨越q
ref
的75百分位数到99百分位数。在q范围内绘制得到的趋势,并且平均值平均与已知的15%gmo相比较。这表明,本文提供的分析框架可以在阈值范围内补偿假阳性和假阴性误差(即使在阈值未被优化时),以提供样品中目标分析物的相对丰度的改进估计值。
[0344]
在该实施例中对于定量群体中目标序列的丰度说明的工作流程不需要任何扩增、纯化、浓缩或缓冲液交换步骤。该工作流程与廉价的一次性样品制备盒相容,以允许在小型化(手持式或桌面式)装置中进行样品入-结果出(sample-in answer-out)的工作流程。
[0345]
在另一组实验中,将不同的gmo%样品作为未知物进行测试。在每个纳米孔上遵循的方案是:a)100%466bp参照,5分钟,然后冲洗;b)100%788bp目标,5分钟,然后冲洗;c)运行1到4个未知物,每个5分钟,中间冲洗;d)运行对照混合物。使用面积标准并且实施跨q
ref
的75百分位数到99百分位数的q-阈值范围,从而将平均报告为预测的gmo%。在等式(2)中,对照混合物用于补偿目标分析物和参照分析物之间的捕获速率常数差异。实验使用1:1、0.75:1或0.35:1的目标:参照对照混合物。
[0346]
表3报告了使用0.35:1(35%gmo)的对照混合物进行补偿的四个“未知”混合样品(s1-s4)的一个纳米孔测定的预测结果。在每个纳米孔测定中未知物是盲法的,因此表格中未报告百分误差。该表还报告了每5分钟时间内记录的事件总数。
[0347]
表3.对于盲法样品s1-s4的gmo预测结果
[0348][0349]
按照上述方案进行总共12个纳米孔实验,并且每个混合样品测试2-5次(总是在不同的纳米孔上,并且由不同的实验者或在不同的日期测试)。纳米孔尺寸范围为直径25-35nm。测定总共11个混合样品(s1-s11)。表4报告了从最小到最大的预测gmo%值排序的综
合估计值。报告的平均gmo%值通过对单纳米孔预测进行平均来计算。每个平均估计值的不确定性从单个估计值分布的重复随机抽样计算(蒙特卡罗方法)。报告的是数字生成的95百分位置信区间。还报告了每个样品的测试次数和每个样品的真实gmo%。
[0350]
表4.对于样品s1-s11的综合gmo%预测(平均值
±
2δ)
[0351][0352]
表4的结果显示我们的方法可以高精度预测目标分析物的分数丰度(例如gmo%)。在10-90%gmo的范围内,通过组合单纳米孔估计值,准确度在2%以内。在5-10%之间和100%的gmo下,其中预测误差可以预期通过接近饱和极限而提高,将两个纳米孔估计值组合导致《5%的误差。通常,与无捕获速率常数差异的补偿(表1-2)相比,使用目标分析物和参照分析物之间的捕获速率常数差异的补偿提高了准确度。对于整个gmo%预测范围,更多纳米孔估计值将更大地提高准确度和精确度。阵列纳米孔(各自从公共池测量)还可以通过消除作为本研究的部分存在的人与人之间以及日与日之间以及试剂组之间的变异来进一步降低不确定性。
[0353]
实施例2
–
对于目标和参照使用不同长度dsdna的基于svm的fa
[0354]
在此使用先前呈现的svm方法(等式(3)-(4))重新分析在实施例1中记录和分析的相同纳米孔数据。
[0355]
分离的对照集首先用于初始特性选择。初始选择旨在移除高度相关的特性,这可能对某些分类方法导致多重共线性问题。七种确定的特性是:(i)log
10
(停留),或者仅“停留”,事件持续时间的10为底的对数;(ii)maxamp:maxδg;(iii)sdampsub:事件信号的标准偏差,除去上升和下降时间;(iv)medamp:中位δg;(v)lfnmean:低于50赫兹的事件的噪声功率的平均值;(vi)lfnmedian:低于50赫兹事件的噪声功率的中位值;(vii)面积:实施例1中使用的相同事件面积。
[0356]
进行进一步的特性提取以减少数据维度。此步骤的目的是平衡计算时间和分类准确性。已经实施了两种算法:1)单变量特性选择方法。anova f-值在事件的每个特性和标记之间计算。阈值人工设置以选择具有最高f评分的一部分特性。2)递归特性消除(rfe)。估计器(例如svm)在初始特性集上训练,并且获得每个特性的重要性。最低重要性的特性从当前特性集排除。递归地重复该过程直到达到所需的特性集数量。
[0357]
对于实施例1数据,采用单变量特性选择方法。特性的百分比的阈值人工设置为
60%。算法选择的四种最佳特性是:(i)停留,(ii)sdampsub,(iii)medamp,(iv)面积。
[0358]
该方法的下一步是模型训练和测试。使用7:3分割将分离对照中的所有事件总体地随机分类到训练数据集和测试数据集中。svm使用超参数搜索算法基于训练数据集训练以找到执行分类的最佳参数。在网格算法中测试的超参数是:核类型(线性,rbf)、正则化参数(c)和核系数(γ)。roc曲线的曲线下面积(roc_auc)用于评估每个超参数组合的性能。具有最高roc_auc分数的模型用于下游数据处理。对于最佳参数组合,计算来自测试数据的每个类的平均精度和召回(recall)。然后具有最佳参数的模型通过训练数据集训练并在测试数据集上进行测试。生成测试数据集上的准确性预测,并如图7所示。整个集合的准确度保持在97.5%以上。
[0359]
该方法的下一步是数据校准。通过将步骤3中的模型应用于对照混合物数据可以实现校准,其产生校正比。然后将校正比乘以未知混合物的每个预测量。这相当于乘以等式(1)和(2)中的参数α。通过在svm方法中将模型应用于对照混合物来生成参数α的值,而(1)和(2)涉及从对照数据集q值直接计算α。
[0360]
表5显示了q-检验方法和基于svm的方法之间gmo%预测的比较。
[0361]
表5.比较单纳米孔gmo%预测,q-检验vs.svm
[0362]
[0363][0364]
样品分为:a)svm预测更准确(1,5,6,8,9,16,19,20,21),b)q-检验预测更准确(3,4,7,10,11,12,14,15,17),和c)这些方法的准确度相同(2,3,18,22)。对于这22个样品,两种方法的总体表现大致相当,各自在9/22的情况中表现优于另一种。
[0365]
svm方法的价值是可以自动地应用于数据集,其先验地可能没有可应用的明确标准,而这是q-检验方法的要求。另一方面,q-检验方法在计算上更简单,并且对于可以在q-检验形式中利用充分表征的标准的分数丰度应用可能是优选的。
[0366]
实施例3
–
使用具有独特有效负载的短dna(74bp参照,94bp目标转基因)的基于q-检验的fa
[0367]
在gmo%预测应用的情况中,该实施例显示两种相当的长度可用于目标和参照dsdna,其中通过使用两种不同的序列特异性有效负载实现纳米孔事件特征的区分。
[0368]
方法:使用经验证的qpcr引物组(可从european union reference laboratory for gm food and feed公开获得),我们从常规和含转基因的基因组dna样品的混合物扩增94bp转基因特异性和74bp分类群特异性片段。在纳米孔检测之前,将这些扩增子与序列特异性寡核苷酸探针杂交(data storage专利#5520281-v2-29517,2016年5月16日中描述的方法),该序列特异性寡核苷酸探针与peg聚合物探针共价连接(参见国际公开号wo/2016/187159,“methods and compositions for target detection in a nanopore using a labelled polymer scaffold”),其通过引用整体并入本文。具体地,转基因靶向的探针与4臂40kda peg连接和参照靶向的探针与8臂40kda peg连接。
[0369]
作为全事件散点图的代表性实例,图8显示了在相同孔上作为分离的对照顺序运行的两种分子类型的事件图。首先,制备含有96bp dna/探针-有效负载复合物的样品,并在纳米孔装置中测量。该复合物是包含目标序列并与探针-有效负载结合的片段的模型。探针-有效负载是具有4臂peg结构的pna-peg。接下来,设计包含参照序列的片段以在通过纳米孔移位时产生独特的事件特征,利用该特征可以实现分数丰度计算。参照分子是结合有pna-peg的74bp dna,其中peg具有8臂结构。关键是参照/探针-有效负载分子产生独特的事件亚群(其不同于目标/探针-有效负载分子),并且两者都不同于任何背景事件(存在时)。
[0370]
每个纳米孔遵循的方案是:a)100%74bp/有效负载-2参照,5分钟,然后冲洗;b)100%p4 bp/有效负载-1目标,5分钟,然后冲洗;c)运行1到4个未知物,每个5分钟,中间冲
洗;d)运行对照混合物。使用面积标准并且实施跨q
ref
的75百分位数到99百分位数的q-阈值范围,从而将平均报告为预测的gmo%。在等式(2)中,1:1对照混合物用于补偿目标分析物和参照分析物之间的捕获速率常数差异。
[0371]
按照上述方案进行一组纳米孔实验,并且每个混合的样品测试2-4次(总是在不同的纳米孔上,并且由不同的实验者或在不同的日期)。纳米孔尺寸范围直径为25-35nm。测定总共6个混合样品(sp1-sp6)。表6报告了从最小到最大预测gmo%值排序的综合估计值。报告的平均gmo%值通过对单纳米孔预测进行平均来计算。计算每个平均估计值的不确定性并报告为95百分位置信区间。还报告了每个样品的测试次数和每个样品的真实gmo%。
[0372]
表6.使用不同有效负载区分目标/参照的综合gmo%预测
[0373][0374]
具有两个有效负载的预测性能似乎不如使用dsdna长度区分时(实施例1,2)那么好。在任何情况下,准确度在所有情况中优于6%,并且可以通过使更多纳米孔平行测量分子池并且组合所得估计值来进一步改善。
[0375]
实施例4
–
使用短dna(89bp)和两个独特有效负载的用于kras g12d snp与野生型相比的fa的q-检测和svm方法
[0376]
我们设计引物以从高度片段化的、无细胞的循环dna扩增人kras基因的短(58bp,70bp或89bp)片段。(cfdna引物序列设计为在kras g12d snp序列(cosmicid 521)的任一侧上退火)。扩增子从获自血浆的无细胞循环dna部分产生,并经历与靶向野生型和突变体kras等位基因两者且与peg聚合物有效负载共价连接的寡核苷酸探针的杂交:靶向kras wt等位基因(c.35g)的探针与40kda 8臂或80kda 2分支peg聚合物连接,和靶向g12d(c.35g-》a)等位基因的探针与40kda 3分支peg聚合物连接。
[0377]
图9a显示了100%目标分析物对照样品(蓝色实心圆圈)和100%参照分子对照样品(黑色空心方块)重叠的平均δg对持续时间的代表性事件图。目标分析物是89bp dna,其中g12d结合的探针与3分支peg连接(表示为g12d-3bpeg)。参照分子是89bp dna,其中野生型(c.35g)-结合的探针与8臂peg连接(表示为wt-8armpeg)。使用35nm直径的纳米孔在215mv(1.0m licl 10mm tris 1mm edta)下依次运行两个对照。在视觉上,该图表明用于标记目标事件的基于三个不等式的标准:
[0378]
持续时间≥q1[0379]
平均
[0380]
平均
[0381]
阈值q1=1msec,q2=0.4ns和q3=0.65ns建立了也在图9a中示出的目标标记框(虚
线)。使用具有所述阈值的三个不等式的标准,分离的对照产生q
ref
=0.006和q
targ
=0.795。等摩尔浓度的目标-有效负载和参照-有效负载分子导致q
1:1
=0.274,其用作对照混合物。随后的两个未知样品a和b,登记qa=0.066和qb=0.041。在事件图中两个样品覆盖在两个分离的对照上,如图9b所示。在视觉上,样品a显示比样品b更高的g12d含量,尽管两者与100%wt对照的0.6%假阳性率相比都是阳性的。在应用等式(1)并使用对照混合物进行补偿后,对于样品a和b,g12d突变体相对野生型的预测分数分别为和
[0382]
表7在第1行和第2行中显示了样品a和b的结果。还显示了所有测试的患者样品的结果。测定总共5个不同的患者样品。样品c和c2是来自相同患者样品的子样品;对于样品d、d2和e、e2同样。在考虑的所有三种情况下,从相同患者样品取得的不同子样品在彼此的2%内。尽管不同的人在不同的纳米孔上运行每个纳米孔实验,并且在两种情况中在不同的日期运行。这表明可重复的工作流程和定量分数丰度方法。
[0383]
表7.使用q-检验方法在血液样品中预测的g12d突变体分数
[0384][0385][0386]
这些样品的g12d真实量未知。在癌症治疗(化疗)开始几周后从患者收集样品,并且在每个患者之后,dna测序并且发现g12d突变是阳性的。还测定了来自对照患者的非阳性对照样品,并且预测的g12d分数为2%或更低,表明2%的总工作流程假阳性。工作流程中的进一步优化可以进一步降低检测限。
[0387]
应用svm方法进行比较。使用一个代表性实验(表1中的纳米孔np4),数据使用针对应用svm方法描述的步骤处理。对于重叠的100%参照对照和100%目标对照在图10中显示了中位δg对log10(持续时间)的事件散点图。还绘制了svm鉴定的决策边界。对于q-检验和svm方法,样品c2中的预测g12d分数在表8中报告。这两种方法在彼此的5%以内。
[0388]
表8.使用q-检验和svm确定优化的阈值(q)的预测g12d分数
[0389][0390]
实施例5:使用短dna(89bp)和两个独特有效负载的用于kras g12d snp与野生型相比的fa的emgm
[0391]
描述了高斯混合的期望最大化算法(emgm)应用于代表性数据集。目标和参照是有效负载结合的dsdna片段内的突变体krasg12d snp和野生型序列,如实施例4中所述。在代表性工作流程中,仅测量1:1对照混合物并且仅测量一个100%参照对照,然后是未知混合物。
[0392]
步骤1:50%目标&50%参照混合物样品的停留时间对数(log(停留))和中值幅度(medamp)用作emgm算法的输入数据(图11)。使用先前确立的关于该测定的知识,将最初鉴定的预期目标区域(即突变体krasg12d snp)标记为图中的矩形区域。通过在单独的实验中在相当的条件(相同缓冲液)中测试100%目标对照来建立先前知识。该框不用于标记。相反,在将emgm应用于对照混合物之后,将与框内的高斯混合物相关的任何事件标记为目标事件。
[0393]
步骤2:基于群体,使用3-高斯混合模型来训练模型。该模型预测了一个簇(菱形)中的突变体(目标)区域。其他2个簇(星形和方形)对应于野生型(图12)。我们观察到初始目标域框(图11)内的一些事件通过emgm算法与参照模式相关联。这与q检验方法(其中框本身限定了标记为目标vs参照的事件群体)不同。
[0394]
步骤3:将模型应用于100%野生型(参照)样品。突变体(目标)区域中事件数量相对于事件总数的比率建立了假阳性分数(图13),其可用于改进分数丰度估计值。
[0395]
步骤4:该模型用于预测未知混合物。突变体区域中的事件数相对于事件总数的比率被用作未知混合物中突变体分子百分比的预测子(图14)。
[0396]
作为通过假阳性补偿的性能增强的测试,从步骤4中的计算分数中减去来自步骤3的假阳性分数作为校正。在一组纳米孔实验中将emgm应用于多种混合物的结果在表9中报告。混合物是盲法的直到组合emgm结果,然后将该结果与真实的g12d分数丰度值进行比较。
[0397]
表9.比较有或没有假阳性(fp)补偿的情况下的emgm的预测g12d分数
[0398][0399][0400]
在np-a的情况下,通过使用假阳性补偿仅在20%的情况中增强了性能。对于np-b,在所有情况中都增强了性能。没有对np-c进行假阳性补偿测试,尽管性能已经很好,特别是对于50%和20%估计值。
[0401]
总之,在将emgm模型应用于未知混合物以进行分数丰度估计之前,仅需要对照混合物来应用emgm方法。
[0402]
其它实施方案
[0403]
应当理解,已经使用的词语是描述性词语而不是限制性词语,并且可以在所附权利要求的范围内进行改变而不脱离本发明的更广泛方面的真实范围和精神。
[0404]
虽然已经相对于所描述的若干实施方案以一定长度和某些特定性描述了本发明,但是并不意图将本发明限制于任何这样的细节或实施方案或任何特定实施方案,而是应该是参照所附权利要求进行解释,以便鉴于现有技术提供对这些权利要求的尽可能广泛的解释,并因此有效地包含本发明的预期范围。
[0405]
本文提及的所有出版物、专利申请、专利和其他参照文献都通过引用整体并入。如果发生冲突,将以本说明书(包括定义)为准。另外,章节标题、材料、方法和实施例仅是说明性的而不是限制性的。