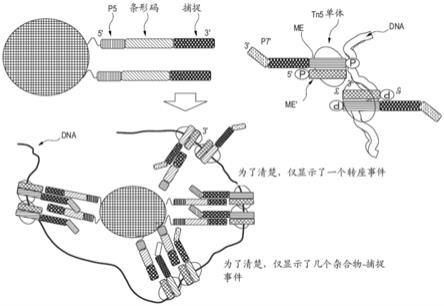
每个所述寡核苷酸包含互补捕捉序列和第一条形码序列,并且其中来自所述 多个固体支持物中的每个固体支持物的所述第一条形码序列不同于来自所 述多个固体支持物中的其它固体支持物的所述第一条形码序列。将所述条形 码序列信息转移至所述靶核酸片段,使得相同靶核酸的至少两个片段接受相 同条形码信息。测定所述靶核酸片段的序列和所述条形码序列。通过鉴定所 述条形码序列测定所述靶核酸的接近性信息。在一些实施方案中,在转座和 随后转座子的衔接头序列与互补捕捉序列杂交后除去转座体复合物的转座 酶。在一些实施方案中,通过sds处理除去转座酶。在一些实施方案中,通 过蛋白酶处理除去转座酶。
11.在一个方面,本文中描述了用于同时测定靶核酸序列的定相信息和甲基 化状态的方法。方法包括使所述靶核酸与多个转座体复合物接触,每个转座 体复合物包含:转座子和转座酶,其中所述转座子包含转移链和非转移链, 其中所述转座体复合物的至少一个转座子包含衔接头序列,所述衔接头序列 能够与互补捕捉序列杂交。将所述靶核酸片段化成多个片段,并且将多个转 移链插入靶核酸片段中,同时维持所述靶核酸的接近性。使所述靶核酸的所 述多个片段与多个固体支持物接触,所述多个中的每个固体支持物包含多个 固定化寡核苷酸,每个所述寡核苷酸包含互补捕捉序列和第一条形码序列, 并且其中来自所述多个固体支持物中的每个固体支持物的所述第一条形码 序列不同于来自所述多个固体支持物中的其它固体支持物的所述第一条形 码序列。将所述条形码序列信息转移至所述靶核酸片段,使得相同靶核酸的 至少两个片段接受相同条形码信息。对包含条形码的所述靶核酸片段进行亚 硫酸氢盐处理,从而生成经亚硫酸氢盐处理的包含条形码的靶核酸片段。测 定所述经亚硫酸氢盐处理的靶核酸片段的序列和所述条形码序列。通过鉴定 所述条形码序列测定所述靶核酸的接近性信息。
12.在一个方面,本文中描述了制备有标签的dna片段的固定化文库的方 法。方法包括提供多个固体支持物,所述固体支持物具有其上固定化的转座 体复合物,其中所述转座体复合物是多聚体的,并且相同转座体复合物的所 述转座体单体单元彼此连接,并且其中所述转座体单体单元包含与所述第一 多核苷酸结合的转座酶,所述第一多核苷酸包含(i)包含转座子端序列的3
’ꢀ
部分,和(ii)包含第一条形码的第一衔接头。在条件下将靶dna应用于所述 多个固体支持物,从而通过所述转座体复合物使所述靶dna片段化,并且将 所述第一多核苷酸的3’转座子端序列转移至所述片段的至少一条链的5’端; 由此生成双链片段的固定化文库,其中至少一条链是用所述第一条形码在5
’ꢀ
加标签的。
13.在一个方面,本文中描述了制备测序文库以测定靶核酸的甲基化状态的 方法。方法包括将所述靶核酸片段化成两个或更多个片段。将第一共同衔接 头序列掺入所述靶核酸的片段的5’端,其中所述衔接头序列包含第一引物结 合序列和亲和力模块(moiety),其中所述亲和力模块在结合对的一个成员中。 使所述靶核酸片段变性。在固体支持物上固定化所述靶核酸片段,其中所述 固体支持物包含所述结合对的另一个成员,并且通过所述结合对的结合固定 化所述靶核酸。对所述固定化靶核酸片段进行亚硫酸氢盐处理。将第二共同 衔接头序列掺入经亚硫酸氢盐处理的固定化靶核酸片段,其中所述第二共同 衔接头包含第二引物结合位点。扩增固体支持物上固定化的经亚硫酸氢盐处 理的靶核酸片段,从而生成测序文库以测定靶核酸的甲基化状态。
14.在一个方面,本文中描述了制备测序文库以测定靶核酸的甲基化状态的 方法。方
法包括提供多个固体支持物,所述固体支持物包含其上固定化的固 定化转座体复合物。所述转座体复合物包含转座子和转座酶,其中所述转座 子包含转移链和非转移链。所述转移链包含:(i)在3’端的第一部分,其包含 转座酶识别序列,和(ii)位于所述第一部分的5’的第二部分,其包含第一衔 接头序列和结合对的第一成员。所述结合对的所述第一成员结合所述固体支 持物上的所述结合对的第二成员,从而将所述转座子固定化至所述固体支持 物。所述第一衔接头还包含第一引物结合序列。所述非转移链包含:(i)5
’ꢀ
端的第一部分,其包含转座酶识别序列,和(ii)位于所述第一部分的3’的第 二部分,其包含第二衔接头序列,其中3’端的末端核苷酸被封闭。所述第二 衔接头还包含第二引物结合序列。使靶核酸与包含固定化转座体复合物的所 述多个固体支持物接触。将所述靶核酸片段化成多个片段,并且将多个转移 链插入所述片段的至少一条链的5’端,从而将所述靶核酸片段固定化至所述 固体支持物。用dna聚合酶延伸片段化的靶核酸的3’端。将所述非转移链与 所述片段化靶核酸的3’端连接。对所述固定化靶核酸片段进行亚硫酸氢盐处 理。通过使用dna聚合酶延伸所述亚硫酸氢盐处理期间损伤的固定化靶核酸 片段的3’端,使得所述固定化靶核酸片段的3’端包含同聚体尾 (homopolymeric tail)。将第二衔接头序列掺入所述亚硫酸氢盐处理期间损伤 的固定化靶核酸片段的3’端。使用第一和第二引物扩增固体支持物上固定化 的经亚硫酸氢盐处理的靶核酸片段,从而生成测序文库以测定靶核酸的甲基 化状态。
15.在一个方面,本文中公开了制备测序文库以测定靶核酸的甲基化状态的 方法。方法包括a.使所述靶核酸与转座体复合物接触,其中所述转座体复合 物包含转座子和转座酶。所述转座子包含转移链和非转移链。所述转移链包 含(i)在3’端的第一部分,其包含转座酶识别序列,和(ii)位于所述第一部分 的5’的第二部分,其包含第一衔接头序列和结合对的第一成员,其中所述结 合对的所述第一成员结合所述结合对的第二成员。所述非转移链包含:(i)5
’ꢀ
端的第一部分,其包含所述转座酶识别序列,(ii)位于所述第一部分的3’的 第二部分,其包含第二衔接头序列,其中3’端的末端核苷酸被封闭,并且其 中所述第二衔接头包含第二引物结合序列。将所述靶核酸片段化成多个片 段,并且将多个转移链插入所述片段的至少一条链的5’端,从而将所述靶核 酸片段固定化至所述固体支持物。使包含所述转座子末端的靶核酸片段与包 含所述结合对的第二成员的所述多个固体支持物接触,其中所述结合对的第 一成员与所述结合对的第二成员的结合将所述靶核酸固定化至所述固体支 持物。用dna聚合酶延伸所述片段化的靶核酸的3’端。将所述非转移链与所 述片段化的靶核酸的3’端连接。对所述固定化的靶核酸片段进行亚硫酸氢盐 处理。通过使用dna聚合酶延伸所述亚硫酸氢盐处理期间损伤的固定化靶核 酸片段的3’端,使得所述固定化靶核酸片段的3’端包含同聚体尾。将第二衔 接头序列引入所述亚硫酸氢盐处理期间损伤的固定化靶核酸片段的3’端。使 用第一和第二引物扩增固体支持物上固定化的经亚硫酸氢盐处理的靶核酸 片段,从而生成测序文库以测定靶核酸的甲基化状态。
16.在一些实施方案中,第二衔接头的3’端的末端核苷酸被选自下组的成员 封闭:二脱氧核苷酸、磷酸基团、硫代磷酸基团、和叠氮基基团。。
17.在一些实施方案中,亲和力模块可以是结合对的成员。在一些情况中, 经修饰的核酸可以包含结合对的第一成员,并且捕捉探针可以包含结合对的 第二成员。在一些情况下,可以将捕捉探针固定化到固体表面,并且经修饰 的核酸可以包含结合对的第一成员,
并且捕捉探针可以包含结合对的第二成 员。在此类情况下,结合所述结合对的第一和第二成员将经修饰的核酸固定 化至固体表面。结合对的实例包括但不限于生物素-亲合素、生物素-链霉亲 合素、生物素-neutravidin、配体-受体、激素-受体、凝集素-糖蛋白、寡核苷 酸-互补寡核苷酸、和抗原-抗体。
18.在一些实施方案中,通过一侧转座(one-sided transpotition)将所述第一 共同衔接头序列掺入所述靶核酸的5’端片段。在一些实施方案中,通过连接 将所述第一共同衔接头序列掺入所述靶核酸的所述5’端片段。在一些实施方 案中将所述第二共同衔接头序列掺入经亚硫酸氢盐处理的固定化靶核酸片 段包括:(i)使用末端转移酶延伸所述固定化靶核酸片段的3’端以包含同聚体 尾;(ii)杂交包含单链同聚体部分的寡核苷酸和包含第二共同衔接头序列的 双链部分,其中单链同聚体部分与同聚体尾互补;并且(iii)将所述第二共同 衔接头序列与所述固定化靶核酸片段连接,从而将所述第二共同衔接头序列 掺入经亚硫酸氢盐处理的固定化靶核酸片段。
19.在一些实施方案中,靶核酸来自单一细胞。在一些实施方案中,靶核酸 来自单一细胞器。在一些实施方案中,靶核酸是基因组dna。在一些实施方 案中,靶核酸与其它核酸交联。在一些实施方案中,靶核酸来自福尔马林固 定的石蜡包埋的(ffpe)样品。在一些实施方案中,靶核酸与蛋白质交联。在 一些实施方案中,靶核酸与dna交联。在一些实施方案中,靶核酸是组蛋白 保护的dna(histone protected dna)。在一些实施方案中,从靶核酸除去组 蛋白。在一些实施方案中,靶核酸是无细胞的肿瘤dna。在一些实施方案中, 从胎盘流体(placental fluid)获得所述无细胞的肿瘤dna。在一些实施方案中, 从血浆获得所述无细胞的肿瘤dna。在一些实施方案中,使用包含所述血浆 的收集区的膜分离器从全血收集所述血浆。在一些实施方案中,所述血浆的 收集区包含固体支持物上固定化的转座体复合物。在一些实施方案中,靶核 酸是cdna。在一些实施方案中,固体支持物是珠。在一些实施方案中,多 个固体支持物是多个珠,并且其中所述多个珠是不同大小的。
20.在一些实施方案中,单一条形码序列存在于每个单独的固体支持物上的 所述多个固定化寡核苷酸中。在一些实施方案中,不同条形码序列存在于每 个单独的固体支持物上的所述多个固定化寡核苷酸中。在一些实施方案中, 通过连接将所述条形码序列信息转移至所述靶核酸片段。在一些实施方案 中,通过聚合酶延伸将所述条形码序列信息转移至所述靶核酸片段。在一些 实施方案中,通过连接和聚合酶延伸两者将所述条形码序列信息转移至所述 靶核酸片段。在一些实施方案中,所述聚合酶延伸是通过使用连接的固定化 寡核苷酸作为模板用dna聚合酶延伸非连接转座子链的3’端。在一些实施方 案中,所述衔接头序列的至少部分进一步包含第二条形码序列。
21.在一些实施方案中,所述转座体复合物是多聚体的,并且其中每个单体 单元的转座子的所述衔接头序列不同于相同转座体复合物中的其它单体单 元。在一些实施方案中,所述衔接头序列还包含第一引物结合序列。在一些 实施方案中,第一引物结合序列与捕捉序列或与捕捉序列的互补物没有序列 同源性。在一些实施方案中,固体支持物上的固定化寡核苷酸进一步包含第 二引物结合序列。
22.在一些实施方案中,转座体复合物是多聚体的,并且相同转座体复合物 中的转座体单体单元彼此连接。在一些实施方案中,转座体单体单元的转座 酶与相同转座体复合物的另一个转座体单体单元的转座酶连接。在一些实施 方案中,转座体单体单元的所述转座
子与相同转座体复合物的另一个转座体 单体单元的转座子连接。在一些实施方案中,转座体单体单元的转座酶通过 共价键与相同转座体复合物的另一个转座体单体单元的转座酶连接。在一些 实施方案中,一个单体单元的转座酶通过二硫键与相同转座体复合物的另一 个转座体单体单元的转座酶连接。在一些实施方案中,转座体单体单元的转 座子通过共价键与相同转座体复合物的另一个转座体单体单元的转座子连 接。
23.在一些实施方案中,靶核酸序列的接近性信息指示单元型信息。在一些 实施方案中,靶核酸序列的所述接近性信息指示基因组变体。在一些实施方 案中,所述基因组变体选自下组:缺失、易位、染色体间基因融合、重复 (duplication)、和旁系同系物(paralog)。在一些实施方案中,固体支持物上固 定化的所述寡核苷酸包含部分双链区和部分单链区。在一些实施方案中,寡 核苷酸的所述部分单链区包含第二条形码序列和第二引物结合序列。在一些 实施方案中,在测定所述靶核酸片段的序列前扩增包含所述条形码的靶核酸 片段。在一些实施方案中,在测定所述靶核酸片段的序列前在单一反应区室 中实施后续扩增。在一些实施方案中,在所述扩增期间将第三条形码序列引 入所述靶核酸片段。
24.在一些实施方案中,方法可以进一步包括将来自多个第一组反应区室的 包含所述条形码的所述靶核酸片段组合成包含所述条形码的靶核酸片段的 合并物;将包含所述条形码的靶核酸片段的所述合并物再分配到多个第二组 反应区室;并且通过在测序前在所述第二组反应区室中扩增所述靶核酸片段 将第三条形码引入所述靶核酸片段中。
25.在一些实施方案中,方法可以进一步包括在使所述靶核酸与转座体复合 物接触前将所述靶核酸预先片段化。在一些实施方案中,通过选自下组的方 法将所述靶核酸预先片段化:超声处理和限制性消化。
26.附图简述
27.图1显示了将转座体与珠表面结合的方法的实例的流程图。
28.图2示意性地显示了图1的方法的步骤。
29.图3显示了珠表面上的标签片段化(tagmentation)过程的实例的示意图。
30.图4是就来自图3的基于珠的标签片段化过程的簇数目而言的dna产率 的实例的数据表。
31.图5显示了就一致大小而言图3的基于珠的标签片段化过程的再现性的 另一实例的数据表。
32.图6a和6b分别显示了图5的索引化样品(indexed sample)的合并物1的插 入物大小的图和合并物2的插入物大小的图。
33.图7显示了图5中描述的实验的读段总数和比对读段的百分比的再现性 的柱状图。
34.图8a,8b和8c分别显示了外显子富集测定法中对照文库中插入物大小 的图、基于珠的标签片段化文库中的插入物大小的图、和汇总数据表。
35.图9a,9b和9c分别显示了外显子富集测定中dups pf分数的柱状图、所 选碱基的分数的柱状图和靶物上的pct可用碱基的柱状图。
36.图10显示了在珠表面上形成转座体复合物的方法的实例的流程图。
37.图11,12和13图示显示了图10的方法的步骤。
38.图14显示了使用图13所示的转座体包被珠(transposome coated bead)的标 签
片段化过程的示意图。
39.图15显示了在固体支持物上形成转座体的示例性方案。
40.图16显示了制备具有独特索引的连续连接的文库(contiguously-linkedlibraries)的示例性方案。
41.图17显示了制备具有独特索引的连续连接的文库的示例性方案。
42.图18和19描绘了在单一克隆索引化珠上捕获单个cpt-dna,其中 cpt-dna缠绕珠。
43.图20显示了通过连接和缺口填充将固体表面上固定化的y-衔接头与经 标签片段化的dna连接的示例性方案。
44.图21显示了在将cpt-dna连接到固体支持物上的固定化寡核苷酸期间 制备此类y-衔接头的示例性方案。
45.图22描绘了琼脂糖凝胶电泳,其显示了通过大小排阻层析从连续连接的 文库除去游离转座体。
46.图23显示了产生特定dna片段的鸟枪序列文库的示例性方案。
47.图24显示了装配来自克隆索引化测序文库的序列信息的示例性方案。
48.图25显示了珠上捕捉探针密度的优化结果。
49.图26显示了测试通过分子内杂交在珠上制备cpt-dna的索引化测序文 库的可行性的结果。
50.图27显示了测试克隆索引化的可行性的结果。
51.图28描绘的图显示了在标签片段化后模板核酸的读段的邻近比对岛之 内(内部)以及还有之间(内)的特定距离的测序读段的频率。
52.图29a和29b显示了在固体支持物上导出接近性信息的示例性方法。
53.图30和31显示了单个反应容器(一罐)中索引化克隆珠转座的示意图和转 座的结果。
54.图32显示了使用5
’‑
或3
’‑
生物素化寡核苷酸在珠上产生克隆转座体的示 意图。
55.图33显示了珠上转座体的文库大小。
56.图34显示了转座体表面密度对插入大小的影响。
57.图35显示了输入dna对大小分布的影响。
58.图36显示了使用基于珠的和基于溶液的标签片段化反应的岛大小和分 布。
59.图37显示了几个单独的dna分子的克隆索引化,每个接收独特的索引。
60.图38显示了用于从全血分离血浆的装置的图。
61.图39和40显示了用于分离血浆和随后使用分离的血浆的装置的图。
62.图41显示通过富集基因组的特定区域的靶向定相的示例性方案。
63.图42显示了使用外显子之间的snp的外显子组定相的示例性方案。
64.图43显示了同时定相和甲基化检测的示例性方案。
65.图44显示了同时定相和甲基化检测的替代示例性方案。
66.图45显示了在单个测定中使用各种大小的克隆索引化珠产生各种大小 的文库的示例性方案。
67.图46显示了用不同长度尺度文库确定遗传变体的示例性方案。
68.图47a和b显示了检测染色体1中60kb杂合缺失的结果。
69.图48显示使用本技术的方法检测基因融合的结果。
70.图49显示使用本技术的方法检测遗传缺陷的结果。
71.图50显示亚硫酸氢盐转化之前和之后的me序列。
72.图51显示了亚硫酸氢盐转化效率优化的结果。
73.图52显示ivc图中亚硫酸氢盐转化后的结果(每个单独碱基的强度对循 环)。
74.图53显示bsc后pcr后的索引化-连接文库的琼脂糖凝胶电泳图像。
75.图54显示了在没有大小选择情况下富集之前,全基因组索引化连接的 cpt-seq文库的生物分析仪迹线。
76.图55显示了富集后文库的琼脂糖凝胶分析。
77.图56显示了靶向单元型分型对染色体中hla区域的应用的结果。
78.图57显示了me交换(swapping)的一些可能的机制。
79.图58显示了me交换的一些可能的机制。
80.图59显示具有可以被cys取代的示例性氨基酸残基asp468,tyr407, asp461,lys459,ser458,gly462,ala466,met470的tn5转座酶的部分。
81.图60显示了具有s458c,k459c和a466c的氨基酸取代,使得半胱氨酸 残基可以在两个单体单元之间形成二硫键的tn5转座酶的部分。
82.图61显示了使用胺包被纳米颗粒制备和使用二聚体转座酶(dtnp)-纳米 颗粒(np)生物缀合物(dtnp-np)的示例性方案。
83.图62显示了转座体二聚体与胺包被固体支持物的缀合的示例性方案。
84.图63显示了转座子末端连接的mu转座体复合物。
85.图64显示了假基因的装配/定相的索引化连接读段的图和使用较短片段 在假基因中鉴定变体的优点。
86.图65显示了来自4个单独实验的索引交换图,并显示为交换的索引的%。
87.图66显示了ts-tn5滴定的片段大小的agilent bioanalyzer分析。
88.图67显示了改善epi-cptseq方案的dna产率的示例性方案,其使用酶促 法以在亚硫酸氢盐处理后回收破碎的文库元件。
89.图68a-c显示了改善epi-cptseq方案的dna产率的几个示例性方案,其 使用酶促法以在亚硫酸氢盐处理后回收破碎的文库元件。
90.图69显示了使用随机引物延伸的模板拯救的示例性方案。
91.图70显示了在硫酸氢钠转化过程中dna文库的片段化。左图显示了在磁 珠上标签片段化的dna的部分的硫酸氢盐转化期间的片段化。右图显示了 cptseq和epi-cptseq(me-cptseq)文库的bioanalyzer迹线。
92.图71显示了tdt介导的ssdna连接反应的示例性方案和结果。
93.图72显示了tdt介导的硫酸氢钠转化珠结合文库的回收的方案和结果。 左图显示使用tdt介导的连接反应对损伤的亚硫酸氢盐转化dna文库的拯 救工作流程。右图中显示了dna文库拯救实验结果。
94.图73显示甲基-cptseq测定的结果。
95.图74显示了dna的基于珠的亚硫酸氢盐转化的示例性方案。
96.图75a-b显示了亚硫酸氢盐转化效率优化的结果。
97.发明详述
98.本发明的实施方案涉及对核酸进行测序。特别地,本文提供的方法和组 合物的实施方案涉及制备核酸模板并从其获得序列数据。
99.在一方面,本发明涉及在固体支持物上标签片段化(片段化和标签化)靶 核酸的方法,用于构建标签片段化的靶核酸文库。在一个实施方案中,固体 支持物是珠。在一个实施方案中,靶核酸是dna。
100.在一方面,本发明涉及可导出靶核酸的接近性信息的固相支持物、基于 转座酶的方法的方法和组合物。在一些实施方案中,组合物和方法可导出装 配/定相信息。
101.在一方面,本发明涉及依靠将连续连接的、转座的靶核酸捕获到固体支 持物上导出接近性信息的方法和组合物。
102.在一方面,本文公开的组合物和方法涉及基因组变体的分析。示例性的 基因组变体包括但不限于缺失、染色体间易位、重复、旁系同系物、染色体 间基因融合。在一些实施方案中,本文公开的组合物和方法涉及确定基因组 变体的定相信息。
103.在一方面,本文公开的组合物和方法涉及定相靶核酸的特定区域。在一 个实施方案中,靶核酸是dna。在一个实施方案中,靶核酸是基因组dna。 在一些实施方案中,靶核酸是rna。在一些实施方案中,rna是mrna。在 一些实施方案中,靶核酸是互补dna(cdna)。在一些实施方案中,靶核酸 来自单一细胞。在一些实施方案中,靶核酸来自循环肿瘤细胞。在一些实施 方案中,靶核酸是无细胞dna。在一些实施方案中,靶核酸是无细胞的肿瘤 dna。在一些实施方案中,靶核酸来自福尔马林固定的石蜡包埋的组织样品。 在一些实施方案中,靶核酸是交联的靶核酸。在一些实施方案中,靶核酸与 蛋白质交联。在一些实施方案中,靶核酸与核酸交联。在一些实施方案中, 靶核酸是组蛋白保护的dna。在一些实施方案中,使用针对组蛋白的抗体将 组蛋白保护的dna从细胞裂解物中沉淀出来,并且除去组蛋白。
104.在一些方面,使用克隆索引化珠从靶核酸创建索引化文库。在一些实施 方案中,虽然转座酶仍然结合靶dna,但可以使用克隆索引化珠捕获标签片 段化的靶核酸。在一些实施方案中,特异性捕捉探针用于捕获靶核酸中的特 定感兴趣区域。靶核酸的捕获区域可以以各种严格性清洗并任选地扩增,随 后进行测序。在一些实施方案中,捕捉探针可以是生物素化的。可以通过使 用链霉亲合素珠分离与索引化靶核酸的特定区域杂交的生物素化捕捉探针 的复合物。图41中显示了靶向定相的实例方案。
105.在一些方面,本文公开的组合物和方法可以用于定相外显子组。在一些 实施方案中,可以富集外显子,启动子。标志物,例如外显子区域之间的杂 合snp可以帮助定相外显子,特别是当外显子之间的距离较大时。图42中显 示了示例性外显子组定相。在一些实施方案中,索引化连接读段不能同时跨 越(覆盖)相邻外显子的杂合snp。因此,对两个或更多个外显子进行定相是 挑战性的。本文公开的组合物和方法还富集外显子之间的杂合snp,例如, 定相外显子1至snp1和snp2至外显子2。因此,通过使用snp 1,可以定相外 显子1和外显子2,如图42中所示。
106.在一个方面,本文公开的组合物和方法可用于定相和同时甲基化检测。 通过亚硫酸氢盐转化(bsc)的甲基化检测是挑战性的,因为bsc反应在dna、 将dna片段化上苛刻、并因此消除接近性/定相信息。此外,本技术中公开 的方法具有另外的优点,因为不需要另外的纯化步骤,与传统bsc方法中所 需的步骤形成对比,从而提高收率。
107.在一个方面,本文公开的组合物和方法可用于在单次测定中制备不同大 小的文库。在一些实施方案中,可以使用克隆索引化珠的不同大小来制备不 同大小的文库。图1显示了将转座体结合到珠表面的方法100的实例的流程 图。可以使用可以在转座子寡核苷酸、转座酶和固相上添加的任何化学物质 将转座体结合到珠表面。在一个实例中,通过生物素-链霉亲合素结合复合 物将转座体结合到珠表面。方法100包括但不限于以下步骤。
108.在一个实施方案中,转座子可以包括测序引物结合位点。序列结合位点 的示例性序列包括但不限于aatgatacggcgaccaccgagatctacac (p5序列)和caagcagaagacggcatacgagat(p7序列)。在一些实施方案 中,转座子可以是生物素化的。
109.在图1的步骤110,产生p5和p7生物素化的转座子。转座子也可以包括一 个或多个索引序列(独特标识符(identifier))。示例性索引序列包括但不限于 tagatcgc,ctctctat,tatcctct,agagtaga,gtaaggag, actgcata,aaggagta,ctaagcct。在另一个实例中,仅p5或仅p7转座 子是生物素化的。在另一个实例中,转座子仅包括嵌合末端(mosaic end,me) 序列或me序列加上不为p5和p7序列的另外序列。在该实例中,在随后的pcr 扩增步骤中添加p5和p7序列。
110.在图1的步骤115中,装配转座体。装配的转座体是p5和p7转座体的混合 物。参考图11和图12更详细地描述了p5和p7转座体的混合物。
111.在图1的步骤120中,p5/p7转座体混合物与珠表面结合。在该实例中, 珠是链霉亲合素包被的珠,并且通过生物素-链霉亲合素结合复合物将转座 体结合到珠表面。珠可以是各种大小的。在一个实例中,珠可以是2.8μm珠。 在另一个实例中,珠可以是1μm珠。1μm珠的悬浮液(例如1μl)为转座体结合 提供了每个体积的较大的表面积。由于转座体结合的可用表面积,每个反应 的标签片段化产物的数目增加。
112.图2图示显示了图1的方法100的步骤110、115和120。在此实例中,转座 子显示为双链体。在另一个实例(未显示)中,可以使用另一种结构,如发夹, 即具有能够形成双链体的自身互补性区域的单个寡核苷酸。
113.在方法100的步骤110,生成多个生物素化的p5转座子210a和多个p7转座 子210b。p5转座子210a和p7转座子210b是生物素化的。
114.在方法100的步骤115,将p5转座子210a和p7转座子210b与转座酶tn5 215混合以形成多个装配的转座体220。
115.在方法100的步骤120,转座体220与珠225结合。珠225是链霉亲合素包 被的珠。转座体220通过生物素-链霉亲合素结合复合物结合珠225。
116.在一个实施方案中,可以在固体支持物,如图10、11、12和13中所示的 珠表面上形成转座体的混合物。在该实例中,在装配转座体复合物之前首先 将p5和p7寡核苷酸与珠表面结合。
117.图3显示了珠表面上的标签片段化过程300的实例的示意图。在过程300 中显示的是图2的珠225,其上结合有转座体220。将dna 310的溶液添加到 珠225的悬浮液。当dna 310接触转座体220时,dna被标签片段化(片段化 和标签化),并通过转座体220与珠225结合。可以pcr扩增结合且标签片段化 的dna 310以产生溶液(无珠)中的扩增子315合并物。可以将扩增子315转移 到流动池320的表面。可以使用簇生成方案(例如,桥接扩增方案或可用于簇 生成的任何其它扩增方案)来在流动池320表面上生成多个簇325。簇325是标 签
片段化的dna 310的克隆扩增产物。现在,簇325准备用于测序方案中的 下一步骤。
118.在另一个实施方案中,可以将转座体结合到任何固体表面,如微量离心 管的壁。
119.在珠表面上形成转座体复合物的混合物的另一个实施方案中,在转座体 装配之前首先将寡核苷酸与珠表面结合。图10显示了在珠表面上形成转座体 复合物的方法1000的实例的流程图。方法1000包括但不限于以下步骤。
120.在步骤1010,p5和p7寡核苷酸与珠表面结合。在一个实例中,p5和p7 寡核苷酸是生物素化的,并且珠是链霉亲合素包被的珠。图11中的示意图 1100中也图示显示了该步骤。现在参考图11,将p5寡核苷酸1110和p7寡核苷 酸1115结合到珠1120的表面。在该实例中,单个p5寡核苷酸1110和单个p7寡 核苷酸1115结合到珠1120的表面,但是任何数目的p5寡核苷酸1110和/或p7 寡核苷酸1115可以结合到多个珠1120的表面。在一个实例中,p5寡核苷酸 1110包含p5引物序列,索引序列(独特标识符),读段1测序引物序列和嵌合末 端(me)序列。在该实例中,p7寡核苷酸1115包含p7引物序列,索引序列(独 特标识符),读段2测序引物序列和me序列。在另一个实例(未显示)中,仅在 p5寡核苷酸1110中存在索引序列。在另一个实施例(未显示)中,仅在p7寡核 苷酸1115中存在索引序列。在另一个实例(未显示)中,p5寡核苷酸1110和p7 寡核苷酸1115两者中不存在索引序列。
121.在步骤1015,互补嵌合末端(me’)寡核苷酸与珠结合的p5和p7寡核苷酸 杂交。图12中的示意图1200还图示显示了该步骤。现在参考图12,互补me 序列(me’)1125与p5寡核苷酸1110和p7寡核苷酸1115杂交。互补me序列 (me’)1125(例如,互补me序列(me’)1125a和互补me序列(me’)1125b)分别 与p5寡核苷酸1110和p7寡核苷酸1115中的me序列杂交。互补me序列(me’) 1125的长度通常约为15个碱基并在其5’末端磷酸化。
122.在步骤1020,将转座酶添加到珠结合的寡核苷酸,以形成珠结合的转座 体复合物的混合物。图13中的示意图1300也图示显示了该步骤。现在参考图 13,添加转座酶以形成多个转座体复合物1310。在这个实例中,转座体复合 物1310是包含转座酶、两个表面结合的寡核苷酸序列和其杂交的互补me序 列(me’)1125的双链体结构。例如,转座体复合物1310a包含与互补me序列 (me')1125杂交的p5寡核苷酸1110和与互补me序列(me')1125杂交的p7寡核 苷酸1115(即p5:p7);转座体复合物1310b包含与互补me序列(me')1125杂交 的两个p5寡核苷酸1110(即p5:p5);和转座体复合物1310c包含与互补me序列 (me')1125杂交的两个p7寡核苷酸1115(即p7:p7)。p5:p5,p7:p7和p5:p7转座 体复合物的比率可以分别为例如25:25:50。
123.图14显示了使用图13的转座体包被珠1120的标签片段化过程的示例性 示意图1400。在该实例中,当将上面有转座体复合物1310的珠1120添加到标 签片段化缓冲液中的dna1410溶液时,发生标签片段化,并通过转座体1310 将dna连接到珠1120的表面。dna1410的连续标签片段化导致转座体1310 之间的多个桥接分子1415。桥接分子1415的长度可以取决于珠1120的表面上 的转座体复合物1310的密度。在一个实例中,可以通过改变在图10的方法100 的步骤1010中与珠1120的表面结合的p5和p7寡核苷酸的量来调节珠1120的 表面上转座体复合物1310的密度。在另一个实例中,可以通过改变在图10的 方法1000的步骤1015中与p5和p7寡核苷酸杂交的互补me序列(me')的量来 调节珠1120表面上的转座体复合物1310的密度。在又一实例中,可以通过改 变在图1的方法1000的步骤1020中添加的转座酶的量来调节珠1120表面上的 转座体复合物1310的密度。
124.桥接分子1415的长度不依赖于用于标签片段化反应的上面结合有转座 体复合物1310的珠1120的量。类似地,在标签片段化反应中添加或多或少的 dna1410不改变最终标签片段化产物的大小,但可影响反应的产率。
125.在一个实例中,珠1120是顺磁珠。在该实例中,通过用磁体固定化珠1120 并进行清洗,容易实现标签片段化反应的纯化。因此,可以在单个反应区室 (“一罐(one-pot)”)反应中实施标签片段化和随后的pcr扩增。
126.在一方面,本发明涉及可以在固体支持物上导出靶核酸的接近性信息的 基于转座酶的方法的方法和组合物。在一些实施方案中,组合物和方法可以 导出组装/定相信息。在一个实施方案中,固体支持物是珠。在一个实施方案 中,靶核酸是dna。在一个实施方案中,靶核酸是基因组dna。在一些实 施方案中,靶核酸是rna。在一些实施方案中,rna是mrna。在一些实施 方案中,靶核酸是互补dna(cdna)。
127.在一些实施方案中,可以将转座子以二聚体固定化到固体支持物,如珠, 然后将转座酶与转座子结合形成转座体。
128.在一些实施方案中,特别涉及通过固相固定化的转座子和添加转座酶在 固相上形成转座体,两个转座子可以彼此极其接近(优选地固定距离)固定化 在固体支持物中。这种方法有几个优点。首先,两个转座子将总是同时固定 化,优选地两个转座子的最佳接头长度和取向以有效形成转座体。第二,转 座体形成效率不会是转座子密度的函数。两个转座子将总是可用,它们之间 有正确的方向和距离以形成转座体。第三,凭借在表面上随机固定化的转座 子,在转座子之间产生各种距离,因此只一定分数具有有效形成转座体的最 佳取向和距离。因此,不是所有的转座子都被转化成转座体,并且将存在固 相固定化的非复合转座子。这些转座子作为转座的靶物是易感的,因为me
‑ꢀ
部分是双链dna。这可导致转座效率降低或产生不希望的副产品。因此,转 座体可以在固体支持物上制备,所述固体支持物随后可以通过标签片段化和 测序来导出接近性信息。图15中显示了示例性方案。在一些实施方案中,转 座子可以通过化学偶联以外的方式固定化到固体支持物。在固体支持物上固 定化转座子的示例性方法可以包括但不限于亲和力结合如链霉亲合素-生物 素,麦芽糖-麦芽糖结合蛋白,抗原-抗体,dna-dna或dna-rna杂交。
129.在一些实施方案中,可以预装配转座体,然后固定化在固体支持物上。 在一些实施方案中,转座子包括独特的索引,条形码和扩增引物结合序列。 可以在包含转座子的溶液中添加转座酶以形成可以固定化在固体支持物上 的转座体二聚体。在一个实施方案中,可以生成多个珠组,其中每组具有从 固定化的转座子衍生的相同的索引,从而产生索引化珠。靶核酸可以添加到 每组索引化珠,如图29a中所示。
130.在一些实施方案中,可以将靶核酸添加到每组索引化珠中,标签片段化 并且随后的pcr扩增可以分别进行。
131.在一些实施方案中,靶核酸、索引化珠和转座体可以在液滴中组合,使 得许多液滴含有具有一个或多个dna分子和足够的转座体的单个珠。
132.在一些实施方案中,可以合并索引化珠,将靶核酸添加到合并物,标签 片段化,并且随后的pcr扩增可以在单个反应区室(“一罐”)中进行。
133.在一方面,本发明涉及通过将连续连接的、转座的靶核酸捕获到固体支 持物上而导出接近性信息的方法和组合物。在一些实施方案中,在dna上进 行接近性保留转座
(cpt),但是dna保持完整(cpt-dna),从而制备连续相 连的文库。接近性信息可以通过使用转座酶保留,以维持靶核酸中相邻的模 板核酸片段的关联。cpt-dna可以通过具有独特索引或条形码的互补寡核苷 酸的杂交捕获,并固定化在固体支持物,例如珠上(图29b)。在一些实施方 案中,除了条形码之外,固定化在固体支持物上的寡核苷酸还可以包括引物 结合序列,独特的分子索引(umi)。
134.有利地,转座体维持片段化核酸的物理邻近(proximity)的此类用途增加 了来自相同原始分子(例如染色体)的片段化核酸将从固定化在固体支持物上 的寡核苷酸接受相同的独特条形码和索引信息的可能性。这将导致具有独特 的条形码的连续连接的测序文库。可以对连续连接的测序文库测序以得出连 续序列信息。
135.图16和17显示了制备具有独特的条形码或索引的连续连接的文库的本 发明的上述方面的示例性实施方案的示意图。该示例性方法利用cpt-dna 与包括独特索引和条形码的固体支持物上固定化的寡核苷酸的连接和链置 换pcr以产生测序文库。在一个实施方案中,可以用固定化的dna序列如随 机或特异性引物和索引产生克隆索引化珠。通过与固定化寡核苷酸杂交,然 后连接,可将连续连接的文库捕获到克隆索引化珠上。由于分子内杂交捕获 比分子间杂交快得多,连续转座的文库“缠绕”珠。图18和19描绘了克隆索 引化珠上的cpt-dna的捕获和接近性信息的保留。链置换pcr可以将克隆珠 索引信息转移到单个分子。因此,每个连续连接的文库将是独特索引化的。
136.在一些实施方案中,固定化在固体支持物上的寡核苷酸可以包含部分双 链结构,使得一条链固定化在固体支持物上,而另一条链与固定化链部分互 补,导致y-衔接头。在一些实施方案中,固定化在固体表面上的y-衔接头通 过连接和缺口填充连接到连续连接的标签片段化的dna,并且在图20中显 示。
137.在一些实施方案中,通过cpt-dna与固体支持物(如珠)上的探针/索引杂 交捕获形成y-衔接头。图21显示了制备此类y衔接头的示例性方案。使用这 些y衔接头确保潜在地,每个片段可以成为测序文库。这增加了每次测序的 覆盖。
138.在一些实施方案中,可以与cpt-dna分离游离转座体。在一些实施方案 中,游离转座子的分离是通过大小排阻层析法。在一个实施方案中,分离可 以由microspin s-400hr柱(ge healthcare life sciences,pittsburgh,pa)实现。 图22显示了与游离转座体分离的cpt-dna的琼脂糖凝胶电泳。
139.通过杂交将连续的、转座的靶核酸捕获到固体支持物质具有几个独特的 优点。首先,该方法是基于杂交而不是转座。分子内杂交率》》分子间杂交率。 因此,在单个靶dna分子上连续转座的文库缠绕独特索引化珠的机会远远高 于使两个或更多个不同的单个靶dna分子缠绕独特索引化珠的机会。第二, dna转座和转座dna的条形码化(barcoding)发生在两个不同的步骤中。第 三,可以避免与珠上的活性转座体装配和固体表面上转座子的表面密度优化 相关的挑战。第四,通过柱纯化可以除去自转座产物。第五,由于连续连接 的、转座的dna含有缺口,因此与在珠上固定化转座体的方法相比,dna 更具柔性,因此对转座密度(插入物大小)的负担较小。第六,该方法可以与 组合条形码化方案一起使用。第七,容易将索引化的寡聚物共价连接到珠。 因此,索引交换的机会较少。第八,可以将标签片段化和随后的pcr扩增多 路复用(multiplexed)并且可以在单个反应区室(“一罐”)反应中进行,消除了 对每个索引序列进行单独反应的需要。
140.在一些实施方案中,可以在转座期间插入整个靶核酸中的多个独特条形 码。在一些实施方案中,每个条形码包括第一条形码序列和第二条形码序列, 其间具有片段化位点。可以将第一条形码序列和第二条形码序列鉴定或指定 为彼此配对。配对可以是信息性的,使得第一条形码与第二条形码相关联。 有利的是,配对条形码序列可用于从模板核酸文库中装配测序数据。例如, 鉴定包含第一条形码序列的第一模板核酸和包含与第一配对的第二条形码 序列的第二模板核酸指示第一和第二模板核酸表示靶核酸的序列表示中彼 此接近的序列。此类方法可用于从头装配靶核酸的序列表示,而不需要参考 基因组。
141.在一方面,本发明涉及产生特定dna片段的鸟枪序列文库的方法和组合 物。
142.在一个实施方案中,用固定化寡核苷酸序列产生克隆索引化珠:随机或 特异性引物和独特索引。将靶核酸添加到克隆索引化珠。在一些实施方案中, 靶核酸是dna。在一个实施方案中,将靶dna变性。靶dna与固定化在固 体表面(例如珠)上的包含独特索引的引物杂交,随后与具有相同索引的其它 引物杂交。珠上的引物扩增dna。可以进行一个或多个进一步的扩增轮次。 在一个实施方案中,可以使用具有3'随机n-聚体(n-mer)序列的珠固定化引物 通过全基因组扩增进行扩增。在优选的实施方案中,随机n-聚体含有假互补 碱基(2-硫代胸腺嘧啶,2-氨基da,n4-乙基胞嘧啶等)以防止扩增期间的引物
ꢀ‑
引物相互作用(hoshika,s;chen,f;leal,na;benner,sa,angew.chem.int. ed.49(32)5554-5557(2010)。图23显示了产生特定dna片段的鸟枪序列文库 的示例性方案。克隆索引化测序文库可以是可以生成的扩增产物文库,在一 个实施方案中,可以通过转座产生此类文库。克隆索引化文库的序列信息可 以用于使用索引信息作为指导来装配连续信息。图24显示了自克隆索引化测 序文库装配序列信息的示例性方案。
143.上述实施方案的方法具有若干优点。珠上的分子内扩增比珠间扩增快得 多。因此,珠上的产物将具有相同的索引。可以创建特定dna片段的鸟枪文 库。随机引物在随机位置处扩增模板,因此可以从特定分子产生具有相同索 引的鸟枪文库,并且可以使用索引化序列装配序列信息。上述实施方案的方 法的重大优点是反应可以在单次反应(一罐反应)中多路复用,并且不需要使 用许多单独的孔。可以制备许多索引克隆珠,因此可以独特地标记许多不同 的片段,并且可以对相同基因组区域的亲本等位基因进行区分。凭借大量的 索引,父本的dna拷贝和母本的拷贝将接受相同基因组区域的相同索引的机 会较低。该方法利用了内反应比间反应快得多的事实,珠基本上在较大的物 理区室中生成虚拟分割(virtual partition)。
144.在本发明的所有上述方面的一些实施方案中,该方法可用于cfdna测定 中的无细胞dna(cfdna)。在一些实施方案中,从血浆,胎盘流体获得cfdna。
145.在一个实施方案中,可以使用基于膜的沉淀辅助血浆分离器从未稀释的 全血获得血浆(liu et al.anal chem.2013nov 5;85(21):10463-70)。在一个实 施方案中,血浆分离器的血浆的收集区可以包括包含转座体的固体支持物。 包含转座体的固体支持物可以从分离的血浆中捕获cfdna,因为它与全血分 离,并且可以浓缩cfdna和/或将dna进行标签片段化。在一些实施方案中, 标签片段化将进一步引入独特的条形码,以便在对文库合并物进行测序后进 行后续的解多路复用(demultiplexing)。
146.在一些实施方案中,分离器的收集区可以包含pcr主混合物(引物、核苷 酸、缓冲液、金属)和聚合酶。在一个实施方案中,主混合物可以是干燥形 式,使得当血浆从分离器
出来时,其将被重构。在一些实施方案中,引物是 随机引物。在一些实施方案中,引物可以是特定基因的特异性引物。cfdna 的pcr扩增将导致直接从分离的血浆中产生文库。
147.在一些实施方案中,分离器的收集区可以包含rt-pcr主混合物(引物、 核苷酸、缓冲液、金属)、逆转录酶和聚合酶。在一些实施方案中,引物是 随机引物或寡聚物dt引物。在一些实施方案中,引物可以是特定基因的特异 性引物。所得cdna可用于测序。或者,可以用固定化在固体支持物上的转 座体处理cdna以进行序列文库制备。
148.在一些实施方案中,血浆分离器可以包括条形码(1d或2d条形码)。在一 些实施方案中,分离装置可以包括血液收集装置。这将导致血液直接递送到 血浆分离器和文库制备装置。在一些实施方案中,该装置可以包括下游序列 分析仪。在一些实施方案中,序列分析仪是一次性测序仪。在一些实施方案 中,测序仪能够在批次中测序前排列样品。或者,测序仪可以具有随机访问 能力,其中将样品递送到其测序区域。
149.在一些实施方案中,用于血浆的收集区可以包含二氧化硅基底,使得浓 缩无细胞dna。
150.同时定相和甲基化检测
151.也称为表修饰(epi modification)的5-甲基胞嘧啶(5-me-c)和5-羟甲基胞嘧 啶(5-羟基-c)在细胞代谢、分化和癌症发展中起重要作用。本技术的发明人 令人惊讶并意外地发现使用本技术的方法和组合物可以进行定相和同时甲 基化检测。本方法将允许组合珠上的cpt-seq(索引化接近性连接的文库)与 dna甲基化检测。例如,可以使用亚硫酸氢盐处理珠上产生的单个文库,将 非甲基化的c,而不是甲基化的c转化为u,从而允许检测5-me-c。通过使用 杂合snp的附加定相分析,表-药物-定位相位块(epi-medication-phasing block) 可以是建立的多兆碱基范围。
152.在一些实施方案中,分析的dna的大小可以是约百碱基至约多兆碱基。 在一些实施方案中,分析的dna的大小可以是约100,200,300,400,500,600, 700,800,900,1000,1200,1300,1500,2000,3000,3500,4000,4500,5000, 5500,6000,6500,7000,7,500,8000,8500,9000,9500,10,000,10,500,11,000, 11,500,12,000,12500,13000,14000,14500,15000,15500,16000,16500, 17000,17,500,18,000,18,500,19,000,19,500,20,000,20,500,21,000,21,500, 22,000,22,500,23,000,23,500,24,000,24,500,25,000,25,500,26,000,26,500, 27,000,27,500,28,000,28,500,29,500,30,000,30,500,31,000,31,500,32,000, 33,000,34,000,35,000,36,000,37,000,38,000,39,000,40,000,42,000,45,000, 50,000,55,000,60,000,65,000,70,000,75,000,80,000,85,000,90,000,95,000, 100,000,110,000,120,000,130,000,140,000,150,000,160,000,170,000, 180,000,200,000,225,000,250,000,300,000,350,000,400,000,450,000, 500,000,550,000,600,000,650,000,700,000,750,000,800,000,850,000, 900,000,1,000,000,1,250,000,1,500,000,2,000,000,2,500,000,3,000,000, 4,000,000,5,000,000,6,000,000,7,000,000,8,000,000,9,000,000,10,000,000, 15,000,000,20,000,000,30,000,000,40,000,000,50,000,000,75,000,000, 100,000,000或更多个碱基。
153.其它表修饰如5-羟基-c、dna氧化产物、dna烷基化产物、组蛋白-足 迹法也可以使用本技术公开的方法和组合在定相的上下文中进行分析。
154.在一些实施方案中,首先在固体支持物上将dna转化成索引化-连接的 文库。由于
各个文库都较小,单独的索引化文库(比原始dna小得多)不太容 易片段化。即使一小部分索引化文库丢失,定相信息在索引化dna分子的长 跨度间得到维持。例如,如果将传统的亚硫酸氢盐转化(bsc)中的100kb分子 片段化一半,则接近性现在限于50kb。在本文公开的方法中,首先将100kb 文库索引化,并且即使一部分单独的文库丢失,接近性仍然在约100kb(除了 在丢失的所有文库来自dna分子的一端的不太可能的情况外)。此外,本申 请中公开的方法具有额外的优点,因为与传统的亚硫酸氢盐转化方法中所需 的步骤相比,不需要额外的纯化步骤,从而提高了收率。在本技术的方法中, 在亚硫酸氢盐转化后简单清洗珠。此外,虽然dna与固相结合,但可以在最 小的dna损失(索引化文库)和缩短的动手时间情况下容易地进行缓冲液交 换。
155.图43中显示了同时定相和甲基化检测的示例性方案。工作流由以下组 成:珠上的dna的标签片段化、缺口填充连接9-bp重复区域、用sds除去tn5、 以及珠上各个文库的亚硫酸氢盐转化。在变性条件下进行亚硫酸氢盐转化, 以确保相邻的互补文库不再退火,从而降低亚硫酸氢盐的转化效率。bcs将 非甲基化c转化为u,并且不转化甲基化c。
156.图44显示了同时定相和甲基化检测的替代示例性方案。在转座后制备测 序文库后,降解一部分缺口填充-连接的文库以制备单链模板。单链模板对 于亚硫酸氢盐转化需要更温和的条件,因为模板已经是单链的,这可以减少 文库损失或改善亚硫酸氢盐转化效率。在一个实施方案中,在相同的珠上使 用3'硫代保护的转座子(exo抗性)和非保护的转座子的混合物。酶,例如exo i 可用于消化非硫代保护的文库,将其转化为单链文库。使用50:50的硫保护转 座子:非保护转座子的的混合物,50%的文库将转化为单链文库(50%使文库 的一个转座子受到保护而一个互补链不受保护),25%不会被转化(两个转座 子都是硫代保护的),并且25%都被转化,除去整个文库。(两个转座子都不 受保护)。
157.实施与固相(如链霉亲合素磁珠)结合的dna的亚硫酸氢盐转化的一个 挑战是在高温下用亚硫酸氢钠延长处理珠结合的dna损伤dna和珠。为了 帮助改善dna损伤,在亚硫酸氢盐处理之前,将载体dna(即λdna)添加到 反应混合物。即使在载体dna的存在下,估计约80%的起始dna丢失。因此, cptseq接近性块比传统cptseq方案中的成员具有更少的成员。
158.因此,本文提出了几种策略来改善epi-cptseq方案的dna产率。第一个 策略依赖于通过更密集地将转座体复合物定于链霉亲合素珠来降低文库插 入物大小。通过减少文库大小,通过亚硫酸氢盐处理降解较小比例的文库元 件。
159.改善epi-cptseq方案的dna产率的第二个策略是断裂的文库元件的酶 回收。回收策略的目的是将文库扩增必需的3’共同序列添加回到珠结合文库 元件,其在亚硫酸氢盐处理期间被消化并失去其3'部分。在添加3'共同序列 之后,这些元件现在可以进行pcr扩增和测序。图67和68显示了该策略的示 例性方案。已经将双链cptseq文库元件变性和亚硫酸氢盐转化(上图)。在亚 硫酸氢盐转化过程中,dna链之一已被破坏(中间图),导致3'末端的pcr共 同序列丢失。模板拯救策略恢复pcr扩增必需的3'共同序列(绿色)(下图)。在 一个实例中,使用在3'磷酸化弱化子寡聚物存在下的末端转移酶,即含有测 序衔接头及后面的寡聚物dt区段的序列(图68a)。简言之,tdt向断裂的文库 元件的3'末端添加10到15个da的区段,其退火到弱化子寡聚物的寡聚物dt部 分。该dna杂交体的形成停止了tdt反应,并提供了后续通过dna聚合酶延 伸断裂的文库元件的3'末端的模板。
160.在替代工作流(图68b)中,tdt加尾反应在部分双链弱化子寡聚物(其含 有单链寡聚物dt部分和5'磷酸化双链测序衔接头部分)的存在下进行。在tdt 反应终止时,最后添加的da和5'磷酸化弱化子寡聚物之间的切口通过dna连 接酶密封。
161.所描述的两个工作流都依赖于最近在美国专利申请公开20150087027中 开发和描述的可控的tdt加尾反应。也可以通过mmlv rt的最近引入的 ssdna模板转换活性将共同测序衔接头添加到断裂的文库元件的3'末端。简 言之,将mmlv rt和模板转换寡聚物(ts_oligo)添加到损伤的dna(图68c)。 在该反应的第一步中,逆转录酶对单链dna片段的3'末端添加几个额外的核 苷酸,并且这些碱基与在ts_oligos之一的3'末端呈现的寡聚物(n)序列配对。 然后,逆转录酶模板转换活性将退火的共同引物的序列添加到bsc断裂文库 元件的3'末端,恢复其使用共同测序引物在pcr中扩增的能力。
162.作为第三种策略的一部分,epicenter的epigenome试剂盒“亚硫酸氢盐 后转化(post-bisulfite conversion)”文库构建方法可用于挽救文库元件,所述 文库元件在亚硫酸氢盐转化期间失去其在3'末端的共同序列。如图69所示, 本文库拯救方法利用3'磷酸化寡核苷酸,其具有共同序列,随后是随机序列 的短区段。这些短随机序列与亚硫酸氢盐处理的单链dna杂交,随后通过 dna聚合酶将共同序列复制到断裂的文库链中。
163.图74显示了改善珠上的亚硫酸氢盐测序方法的第四种策略。包含捕获标 签的第一共同序列共价附着到dna的5'末端。第一共同序列可以使用各种方 法附着于dna,包括单侧转座(如绘图),衔接头连接或末端转移酶(tdt)衔接 头连接,如美国专利申请公开20150087027中所述的。
164.接下来,将dna变性(例如在高加热下温育)并结合到固体支持物。例如, 如果使用生物素作为cs1上的捕获标签,则可以使用链霉亲合素磁珠(如绘图) 结合dna。一旦结合到固体支持物,可以容易进行缓冲液交换。
165.在下一步中,进行ssdna的亚硫酸氢盐转化。在单链形式中,dna应易 于接近以进行亚硫酸氢盐转化;已经使用promega的methyl edge bsc试剂盒 的修改版本观察到高达95%的转化效率(图75)。
166.在亚硫酸氢盐转化后,将第二共同序列共价附着到与固体支持物附着的 ssdna的3'末端。上面已经描述了几种方法以将寡聚物共价附着到ssdna。 使用tdt弱化子/衔接头连接方法,实现了》95%的连接效率。因此,使用所 提出的methylseq工作流的最终文库产率应该大于现有方法。
167.在最后一步中,进行pcr扩增文库,并将其从固体支持物中除去。pcr 引物可以被设计成向methylseq文库的末端添加额外的共同序列,如测序衔 接头。
168.在单一测定中制备不同大小的文库
169.基因组装配的准确性取决于不同长度尺度技术的使用。例如,鸟枪(数 百bp(100’s of bp))
–
配对(matepair)(约3kb)至-hi-c(mb-尺度)是序贯改善装 配和重叠群长度的所有方法。挑战在于,需要多种测定法实现这点,从而使 多层次的方法变得繁琐且昂贵。本文公开的组合物和方法可以在单个测定中 解决多个长度尺度。
170.在一些实施方案中,可以在使用差异大小的固体支持物,例如珠的单个 测定中实现文库制备。每个珠大小将产生特定的文库大小或大小范围,珠的 物理大小确定文库大小。各种大小的珠都具有转移到文库的独特克隆索引。 因此,生成不同大小的文库,每个不
同的文库尺度长度都是独特索引化的。 各种长度尺度的文库在同一物理区室中同时制备,降低成本并改善总体工作 流。在一些实施方案中,每个特定固体支持物体大小(例如,珠大小)接收独 特的索引。在一些其他实施方案中,还制备了相同固体支持物大小,例如珠 大小的多个不同索引,使得可以针对该大小范围对多个dna分子进行索引分 割。图45显示了在单个测定中使用各种大小的克隆索引化珠产生各种大小的 文库的示例性方案。
171.在一些实施方案中,生成的文库的大小约为50,75,100,150,200,250, 300,350,400,500,600,700,800,900,1000,1200,1300,1500,2000,3000, 3500,4000,4500,5000,5500,6000,6500,7000,7,500,8000,8500,9000,9500, 10,000,10,500,11,000,11,500,12,000,12500,13000,14000,14500,15000, 15500,16000,16500,17000,17,500,18,000,18,500,19,000,19,500,20,000, 20,500,21,000,21,500,22,000,22,500,23,000,23,500,24,000,24,500,25,000, 25,500,26,000,26,500,27,000,27,500,28,000,28,500,29,500,30,000,30,500, 31,000,31,500,32,000,33,000,34,000,35,000,36,000,37,000,38,000,39,000, 40,000,42,000,45,000,50,000,55,000,60,000,65,000,70,000,75,000,80,000, 85,000,90,000,95,000,100,000,110,000,120,000,130,000,140,000,150,000, 160,000,170,000,180,000,200,000,225,000,250,000,300,000,350,000, 400,000,450,000,500,000,550,000,600,000,650,000,700,000,750,000, 800,000,850,000,900,000,1,000,000,1,250,000,1,500,000,2,000,000, 2,500,000,3,000,000,4,000,000,5,000,000,6,000,000,7,000,000,8,000,000, 9,000,000,10,000,000,15,000,000,20,000,000,30,000,000,40,000,000, 50,000,000,75,000,000,100,000,000或更多个碱基。
172.在一些实施方案中,上面讨论的多个长度尺度的文库可用于伪基因,旁 系同系物等的装配,代替具有一个较大的长度尺度。在一些实施方案中,在 单个测定中同时制备多个长度尺度文库。优点是至少一个长度尺度将独特的 区域与仅假基因和或基因连接,而非两者。因此,用该长度尺度检测的变体 可以将变体独特地分配给基因或假基因。对于拷贝数变体,旁系同系物等也 是如此。装配的强度是使用不同的长度尺度。使用本文公开的方法,可以在 单个测定中产生不同长度尺度索引化的连接的文库,而不是用于不同长度尺 度的单独的不同的文库制备物。图46显示了用不同长度尺度文库测定遗传变 体的示例性方案。
173.基因组变体分析
174.本文公开的组合物和方法涉及基因组变体的分析。示例性的基因组变体 包括但不限于缺失,染色体间易位,重复,旁系同系物,染色体间基因融合。 在一些实施方案中,本文公开的组合物和方法涉及测定基因组变体的定相信 息。下表显示了例示性的染色体间基因融合。
175.表1:染色体间基因融合
[0176][0177]
表2显示了染色体1中的示例性缺失,
[0178]
表2:染色体1中的示例性缺失
[0179]
[0180]
在一些实施方案中,可以对靶核酸片段化,之后将其暴露于转座体。示 例性的片段化方法包括但不限于超声处理、机械剪切和限制性消化。在标签 片段化(片段化和标签化)前靶核酸的片段化对于假基因(例如,cyp2d6)的装 配/定相是有利的。索引化连接读段的长岛(》30kb)将跨越假基因a和a',如图 64中所示。由于高序列同源性,确定哪个变体属于基因a和基因a'将是具有 挑战性的。较短的变体将连接假基因的一个变体与独特的周围序列。此类较 短的岛可以通过在标签片段化前将靶核酸片段化来实现。
[0181]
连接的转座体
[0182]
在一些实施方案中,转座酶在转座体复合物中是多聚体的,例如,它们 在转座体复合物中形成二聚体,四聚体等。本技术的发明人令人惊讶且出人 意料地发现,连接多聚体转座体复合物中单体转座酶或者连接多聚体转座体 复合物中的转座体单体的转座子末端具有几个优点。第一,转座酶或转座子 的连接导致更稳定的复合物,并且大部分处于活性状态。第二,较低浓度的 转座体可以潜在地用于通过转座反应的片段化。第三,连接导致转座体复合 物的嵌合末端(me)的较低交换,因此条形码或衔接头分子的混合较少。如果 复合物分解并且再形成,或者在转座体通过链霉亲合素/生物素固定化在固体 支持物上的情况下,链霉亲合素/生物素相互作用可以破坏并且再形成,或当 有可能的污染时,则me末端的此类交换是可能的。本技术的发明人指出, 在各种反应条件下存在me末端的显著交换或更换。在一些实施方案中,交 换可以高达15%。交换在高盐缓冲液中是明显的,并且交换在谷氨酸缓冲液 中降低。图57和58显示了me交换的一些可能的机制。
[0183]
在一些实施方案中,转座体复合物中的转座酶亚基可以通过共价和非共 价方式彼此连接。在一些实施方案中,转座酶单体可以在制成转座体复合物 之前(在添加转座子之前)连接。在一些实施方案中,转座酶单体可以在转座 体形成之后连接。
[0184]
在一些实施方案中,多聚体界面处的天然氨基酸残基可以被半胱氨酸 (cys)氨基酸取代,以促进形成二硫键。例如,在tn5转座酶中,asp468,tyr407, asp461,lys459,ser458,gly462,ala466,met470可被cys取代,以促进单体亚 单位之间的二硫键,并且在图59和60中显示。对于mos-1转座酶,可以用半 胱氨酸取代的示例性氨基酸包括但不限于leu21,leu32,ala35,his20,phe17, phe36,ile16,thr13,arg12,gln10,glu9,并且在图61中所示。在一些实施方 案中,具有用半胱氨酸取代的氨基酸残基的经修饰的转座酶可以使用马来酰 亚胺或吡啶基二硫醇反应性基团的化学交联剂彼此化学交联。示例性的化学 交联剂可从pierce protein biology/thermofisher scientific(grand island,ny, usa)商购。
[0185]
在一些实施方案中,转座体多聚体复合物可以共价连接到固体支持物。 示例性固体支持物包括但不限于纳米颗粒、珠、流动池表面、柱基质。在一 些实施方案中,固体表面可以用胺基团包被。使用胺与巯基交联剂(即琥珀 酰亚胺基-4-(n-马来酰亚胺基甲基)环己烷-1-羧酸酯(smcc)),具有用半胱氨 酸取代的氨基酸残基的经修饰的转座酶可以与此类胺基团化学交联。图62中 显示了示例性方案。在一些实施方案中,马来酰亚胺-peg-生物素交联剂可 用于将dtnp与链霉亲合素包被的固体表面偶联。
[0186]
在一些实施方案中,可以修饰转座酶基因以在单个多肽中表达多聚体的 蛋白质。例如,可以修饰tn5或mos-1基因以在单个多肽中表达两个tn5或 mos-1蛋白。类似地,mu转座酶基因可以修饰成在单个多肽中编码4个mu转 座酶单位。
[0187]
在一些实施方案中,可以连接转座体单体单元的转座子末端以形成连接的转座体多聚体复合物。连接转座子末端允许插入引物位点、测序引物、扩增引物或dna可以在gdna中发挥的任何作用而不将靶dna片段化。此类功能性的插入是单元型分型测定或结合标签化测定中的优点,其中信息需要从完整分子提取或其中二次取样是重要的。在一些实施方案中,mu转座体的转座子末端可以连接到“环状”mu转座酶/转座子构象。由于mu是四聚体,各种构象是可能的,但不限于通过将r2uj和/或r1uj与r2j和/或r1j连接。在这些构造中,r2uj和r1uj不能/不是分别与r2j和r1j连接的,图63显示了转座子端部连接的mu转座体复合物。在一些实施方案中,可以连接tn5的转座子末端或mos-1转座体的转座子末端。
[0188]
如本文中所用,术语“转座子”是指仅表现出与在体外转座反应中有功能的转座酶或整合酶形成复合物所必需的核苷酸序列(“转座子末端序列”)的双链dna。转座子与识别和结合转座子的转座酶或整合酶形成“复合物”或“突触复合体(synapticcomplex)”或“转座体复合物”或“转座体组合物”,并且所述复合物能够将转座子插入或转座到在体外转座反应中与其一起温育的靶dna中。转座子表现出两个互补序列,其由“转移转座子序列”或“转移链”和“非转移转座子序列”、或“非转移链”构成。例如,与在体外转座反应中有活性的超活性tn5转座酶(例如ez-tn5
tm
转座酶,epicentrebiotechnologies,madison,wis.,usa)形成复合物的一种转座子包含表现出如下的“转移转座子序列”的转移链:
[0189]
5'agatgtgtataagagacag3'
[0190]
和表现出如下的“非转移的转座子序列”的非转移链:
[0191]
5'ctgtctcttatacacatct3'。
[0192]
转移链的3'末端在体外转座反应中连接或转移到靶dna。表现出与转移的转座子末端序列互补的转座序列的未转移的链在体外转座反应中不连接或转移到靶dna。在一些实施方案中,转座子序列可以包括以下中的一个或多个:条形码,衔接头序列,标签序列,引物结合序列,捕捉序列,独特分子标识符(umi)序列。
[0193]
如本文中所用,术语“衔接头”是指可以包括条形码,引物结合序列,捕捉序列,与捕捉序列互补的序列,独特分子标识符(umi)序列,亲和力模块,限制性位点的核酸序列。
[0194]
如本文中所用,术语“接近性信息”是指基于共享信息的两个或更多个dna片段之间的空间关系。信息的共享方面可以就相邻的、分隔的和距离的空间关系而言。关于这些关系的信息继而有利于从dna片段衍生的序列读段的分层装配或定位(mapping)。此接近性信息改善了此类装配或定位的效率和准确性,因为与常规鸟枪测序相关联使用的传统装配或定位方法没有考虑到个别序列读段的相对基因组起点或坐标,这是由于它们涉及衍生个别序列读段的两个或更多个dna片段之间的空间关系。因此,根据本文描述的实施方案,捕获接近性信息的方法可以通过测定相邻的空间关系的短距离接近性方法,测定区室空间关系的中距离接近性方法或者测定距离空间关系的长距离接近性方法来实现。这些方法有助于dna序列装配或定位的准确性和质量,并可以与任何测序方法,如上述方法一起使用。
[0195]
接近性信息包括单个序列读段的相关基因组起点或坐标,因为它们涉及衍生所述单个序列读段的两个或更多个dna片段之间的空间关系。在一些实施方案中,接近性信息包括来自非重叠序列读段的序列信息。
[0196]
在一些实施方案中,靶核酸序列的接近性信息指示单元型信息。在一些 实施方案中,靶核酸序列的接近性信息指示基因组变体。
[0197]
如本文中所用,术语“维持靶核酸的接近性”在将核酸片段化的背景下 意味着维持来自相同靶核酸的片段的核酸序列的顺序。
[0198]
如本文中所用,术语“至少部分”和/或其语法等同物可以指整个量的任 何分数。例如,“至少部分”可以指整个量的至少约1%,2%,3%,4%,5%,6%, 7%,8%,9%,10%,15%,20%,25%,30%,35%,40%,45%,50%,55%,60%, 65%,70%,75%,80%,85%,90%,95%,99%,99.9%或100%。
[0199]
如本文中所用,术语“约”表示+/-10%。
[0200]
如本文中所用,术语“测序读段”和/或其语法等同物可以指为了获得指 示聚合物中单体顺序的信号而进行物理或化学步骤的重复过程。信号可以指 示以单一单体分辨率或更低分辨率的单体的顺序。在具体实施方案中,可以 在核酸靶物上启动步骤并进行以获得指示核酸靶物中碱基顺序的信号。该过 程可以进行到其典型的完成,其通常由来自过程的信号不能以合理的确定性 水平区分靶物碱基的点限定。若期望的话,可以更早地发生完成,例如,一 旦获得了期望量的序列信息。可以在单个靶核酸分子上或同时在具有相同序 列的靶核酸分子的群体上或同时在具有不同序列的靶核酸的群体上进行测 序读段。在一些实施方案中,当不再从其中启动信号获取的一个或多个靶核 酸分子获得信号时,终止测序读段。例如,可以对存在于固相基底上的一种 或多种靶核酸分子启动测序读段,并在从基底中除去一种或多种靶核酸分子 后终止。可以通过以其它方式停止检测当启动测序运行时存在于基底上的靶 核酸来终止测序。在美国专利no.9,029,103中描述了测序的示例性方法,其 全部内容通过引用并入本文。
[0201]
如本文所用,术语“测序表示”和/或其语法等同物可以指代表聚合物中 单体单元的顺序和类型的信息。例如,信息可以指示核酸中核苷酸的顺序和 类型。该信息可以是多种格式中的任一种,包括例如描绘、图像、电子媒体、 一系列符号、一系列数字、一系列字母、一系列颜色等。信息可以为单个单 体分辨率或较低的分辨率。示例性聚合物是具有核苷酸单元的核酸,如dna 或rna。一系列“a”,“t”,“g”和“c”字母是dna的公知序列表示,其 可以以单核苷酸分辨率与dna分子的实际序列相关。其它示例性聚合物是具 有氨基酸单元的蛋白质和具有糖单元的多糖。
[0202]
固体支持物
[0203]
贯穿本技术,固体支持物和固体表面可互换使用。在一些实施方案中, 固体支持物或其表面是非平面的,如管或容器的内表面或外表面。在一些实 施方案中,固体支持物包括微球或珠。本文中的“微球”或“珠”或“颗粒
”ꢀ
或语法等同物是指小的离散颗粒。合适的珠组成包括但不限于塑料,陶瓷, 玻璃,聚苯乙烯,甲基苯乙烯,丙烯酸聚合物,顺磁材料,氧化钍溶胶,碳 石墨,二氧化钛,胶乳或交联葡聚糖如sepharose,纤维素,尼龙,交联胶束 和特氟隆(teflon),以及都可以使用的本文中对固体支持物概述的任何其它材 料。来自bangs laboratories,fishers ind.的“microsphere detection guide”是 有用的指南。在某些实施方案中,微球是磁性微球或珠。在一些实施方案中, 珠可以是颜色编码的。例如,可以使用来自luminex,austin,tx的微球。
[0204]
珠不需要是球形的;可以使用不规则的颗粒。或者或另外,珠可以是多 孔的。珠的
大小范围从纳米,即约10nm到毫米直径,即1mm,优选约0.2微 米至约200微米的珠,特别优选约0.5至约5微米,尽管在一些实施方案中可以 使用更小或更大的珠。在一些实施方案中,珠可以是约0.1,0.2,0.3,0.4,0.5. 0.6,0.7,0.8,0.9,1,1.5,2,2.5,2.8,3,3.5,4,4.5,5,5.5,6,6.5,7,7.5,8,8.5,9, 9.5,10,10.5,15,20,25,30,35,40,45,50,55,60,65,70,75,80,85,90,95,100, 150或200μm的直径。
[0205]
转座体
[0206]“转座体”包含整合酶,如整合酶或转座酶,以及包含整合识别位点, 例如转座酶识别位点的核酸。在本文提供的实施方案中,转座酶可以与转座 酶识别位点形成功能性复合物,其能够催化转做反应。转座酶可以结合转座 酶识别位点,并且在有时称为“标签片段化”的过程中将转座酶识别位点插 入靶核酸中。在一些此类插入事件中,转座酶识别位点的一条链可以转移到 靶核酸中。在一个实例中,转座体包含含有两个亚基的二聚体转座酶和两个 不连续的转座子序列。在另一个实例中,转座体包含转座酶和连续的转座子 序列,所述转座酶包含含有两个亚基的二聚体转座酶。
[0207]
一些实施方案可以包括使用超活性tn5转座酶和tn5型转座酶识别位点 (goryshin and reznikoff,j.biol.chem.,273:7367(1998))或mua转座酶和mu 包含r1和r2末端序列的转座酶识别位点(mizuuchi,k.,cell,35:785,1983; savilahti,h,etal.,embo j.,14:4893,1995)。与超活性tn5转座酶(例如, ez-tn5
tm
转座酶,epicentre biotechnologies,madison,wisconsin)形成复合物 的示例性转座酶识别位点包含以下19b转移的链(有时为“m”或“me”)和非 转移链:5
′
agatgtgtataagagacag 3
′
,5
′
ctgtct cttatacacatct3
′
。也可以使用me序列,如由熟练技术人员优化。
[0208]
可以与本文提供的组合物和方法的某些实施方案一起使用的转座系统 的更多实例包括金黄色葡萄球菌(staphylococcus aureus)tn552(colegio et al., j.bacteriol.,183:2384-8,2001;kirby c et al.,mol.microbiol.,43:173-86, 2002),ty1(devine&boeke,nucleic acids res.,22:3765-72,1994和国际公开 wo 95/23875),转座子tn7(craig,n l,science.271:1512,1996;craig,n l, review in:curr top microbiol immunol.,204:27-48,1996),tn/o和is10 (kleckner n,et al.,curr top microbiol immunol.,204:49-82,1996),mariner转 座酶(lampe d j,et al.,embo j.,15:5470-9,1996),tc1(plasterkr h,curr. topics microbiol.immunol.,204:125-43,1996),p元件(gloor,g b,methodsmol.biol.,260:97-114,2004),tn3(ichikawa&ohtsubo,j biol. chem.265:18829-32,1990),细菌插入序列(ohtsubo&sekine,curr. top.microbiol.immunol.204:1-26,1996),逆转录病毒(brown,et al.,proc natlacad sciusa,86:2525-9,1989),和酵母的反转录转座子(boeke&corces, annu revmicrobiol.43:403-34,1989)。更多实例包括is5、tn10、tn903、is911、 sleeping beauty、spin、hat、piggybac、hermes、tcbuster、aebuster1、 tol2、和转座酶家族酶的工程化形式(zhang et al.,(2009)plosgenet.5:e1000689.epub 2009oct 16;wilson c.et al(2007)j.microbiol. methods 71:332-5)。
[0209]
可以与本文提供的方法和组合物一起使用的整合酶的更多实例包括用 于逆转录病毒整合酶和用于此类逆转录病毒整合酶的整合酶识别序列,如来 自hiv-1,hiv-2,siv,pfv-1,rsv的整合酶。
[0210]
条形码
[0211]
通常,条形码可以包含可用于鉴定一种或多种特定核酸的一种或多种核 苷酸序列。条形码可以是人工序列,或者可以是在转座期间产生的天然存在 的序列,如在以前并置的dna片段末端的相同的侧翼基因组dna序列(g
‑ꢀ
码)。在一些实施方案中,条形码是在靶核酸序列中不存在并可用于鉴定一 种或多种靶核酸序列的人工序列。
[0212]
条形码可以包括至少约1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17, 18,19,20或更多个连续核苷酸。在一些实施方案中,条形码包含至少约10,20, 30,40,50,60,70 80,90,100或更多个连续核苷酸。在一些实施方案中,包含 条形码的核酸群体中条形码的至少部分是不同的。在一些实施方案中,条形 码的至少约10%,20%,30%,40%,50%,60%,70%,80%,90%,95%,99%是不 同的。在更多此类实施方案中,所有条形码都是不同的。包含条形码的核酸 群体中不同条形码的多样性可以随机生成或非随机生成。
[0213]
在一些实施方案中,转座子序列包括至少一个条形码。在一些实施方案 中,诸如包含两个不连续的转座子序列的转座体,第一转座子序列包括第一 条形码,并且第二转座子序列包括第二条形码。在一些实施方案中,转座子 序列包含含有第一条形码序列和第二条形码序列的条形码。在前述一些实施 方案中,可以将第一条形码序列鉴定或指定为与第二条形码序列配对。例如, 使用包括已知彼此配对的多个第一和第二条形码序列的参考表,可以知道已 知的第一条形码序列与已知的第二条形码序列配对。
[0214]
在另一实例中,第一条形码序列可以包括与第二条形码序列相同的序 列。在另一实例中,第一条形码序列可以包括第二条形码序列的反向互补物。 在一些实施方案中,第一条形码序列和第二条形码序列是不同的。第一和第 二条形码序列可以包括双码(bi-code)。
[0215]
在本文所述的组合物和方法的一些实施方案中,条形码用于制备模板核 酸。如将理解的,大量的可用条形码允许每个模板核酸分子包含独特的鉴定。 模板核酸混合物中每个分子的独特鉴定可用于几种应用。例如,可以应用独 特鉴定的分子来鉴定在具有多个染色体的样品中,在基因组中,细胞中,细 胞类型中,细胞疾病状态中和物种中的单个核酸分子,例如在单元型测序中, 在亲本等位基因区分中,在宏基因组测序中和在基因组样品测序中。
[0216]
示例性条形码包括但不限于tatagcct,atagaggc,cctatcct, ggctctga,aggcgaag,taatctta,caggacgt和gtactgac。
[0217]
引物位点
[0218]
在一些实施方案中,转座子序列可以包括“测序衔接头”或“测序衔接 头位点”,也就是说,包含可以与引物杂交的一个或多个位点的区域。在一 些实施方案中,转座子序列可以包括至少可用于扩增,测序等的第一引物位 点。序列结合位点的示例性序列包括但不限于 aatgatacggcgaccaccgagatctacac(p5序列)和 caagcagaagacggcatacgagat(p7序列)。
[0219]
靶核酸
[0220]
靶核酸可以包括任何感兴趣的核酸。靶核酸可以包括dna,rna,肽核 酸,吗啉代核酸,锁定核酸,二醇核酸,苏糖核酸,核酸的混合样品,多倍 性dna(即植物dna),其混合物及其杂种。在优选的实施方案中,使用基因 组dna或其扩增拷贝作为靶核酸。在另一个优选的
实施方案中,使用cdna, 线粒体dna或叶绿体dna。在一些实施方案中,靶核酸是mrna。
[0221]
在一些实施方案中,靶核酸来自单一细胞或来自单一细胞的部分。在一 些实施方案中,靶核酸来自单一细胞器。示例性单细胞器包括但不限于单一 核,单一线粒体和单一核糖体。在一些实施方案中,靶核酸来自福尔马林固 定石蜡包埋(ffpe)样品。在一些实施方案中,靶核酸是交联核酸。在一些实 施方案中,靶核酸与蛋白质交联。在一些实施方案中,靶核酸是交联dna。 在一些实施方案中,靶核酸是组蛋白保护的dna。在一些实施方案中,从靶 核酸中除去组蛋白。在一些实施方案中,靶核酸来自核小体。在一些实施方 案中,靶核酸来自除去核蛋白的核小体。
[0222]
靶核酸可以包含任何核苷酸序列。在一些实施方案中,靶核酸包含均聚 物(homopolymer)序列。靶核酸还可以包括重复序列。重复序列可以是多 种长度中的任何一种,包括例如2,5,10,20,30,40,50,100,250,500或1000个 核苷酸或更多个。重复序列可以连续地或非连续地重复多种次数之任一种, 包括例如2,3,4,5,6,7,8,9,10,15或20次或更多次。
[0223]
本文描述的一些实施方案可以利用单一靶核酸。其他实施方案可以利用 多个靶核酸。在此类实施方案中,多个靶核酸可以包含多个相同的靶核酸, 多个不同的核核酸(其中一些靶核酸是相同的),或多个靶核酸(其中所有靶 核酸是不同的)。利用多个靶核酸的实施方案可以多重形式进行,使得试剂 同时递送至靶核酸,例如在一个或多个室中或在阵列表面上。在一些实施方 案中,多个靶核酸可以包括基本上整个的特定生物体的基因组。多个靶核酸 可以包括特定生物体基因组的至少一部分,包括例如基因组的至少约1%,5%, 10%,25%,50%,75%,80%,85%,90%,95%或99%。在具体实施方案中,部分 可以具有基因组的至多约1%,5%,10%,25%,50%,75%,80%,85%,90%, 95%或99%的上限
[0224]
靶核酸可以从任何来源获得。例如,靶核酸可以由从单一生物体获得的 核酸分子或从包含一种或多种生物体的天然来源获得的核酸分子的群体制 备。核酸分子的来源包括但不限于细胞器,细胞,组织,器官或生物体。可 用作靶核酸分子来源的细胞可以是原核生物(细菌细胞,例如埃希氏菌属 (escherichia),芽孢杆菌属(bacillus),沙雷氏菌属(serratia),沙门氏菌属 (salmonella),葡萄球菌属(staphylococcus),链球菌属(streptococcus),梭菌属 (clostridium),衣原体属(chlamydia),奈瑟球菌属(neisseria),密螺旋体属 (treponema),支原体属(mycoplasma),疏螺旋体属(borrelia),军团菌属 (legionella),假单胞菌属(pseudomonas),分枝杆菌属(mycobacterium),幽门 螺杆菌属(helicobacter),欧文氏菌属(erwinia),土壤杆菌属(agrobacterium), 根瘤菌属(rhizobium)和链霉菌属(streptomyces);诸如古菌(archeaon),如泉古 菌门(crenarchaeota),纳古菌门(nanoarchaeota)或广古生菌界(euryarchaeotia); 或真核生物如真菌(例如酵母),植物,原生动物和其他寄生物以及动物(包括 昆虫(例如果蝇属种(drosophila spp.)),线虫(例如秀丽隐杆线虫 (caenorhabditis elegans)))和哺乳动物(例如大鼠,小鼠,猴,非人类灵长类动 物和人)。可以使用本领域熟知的各种方法对靶核酸和模板核酸富集某些感 兴趣的序列。在int.pub.no.wo/2012/108864中提供了此类方法的实例,其 通过引用完整并入本文。在一些实施方案中,核酸可以在制备模板文库的方 法中进一步富集,例如,可以在插入转座体之前、在插入转座体后和/或在扩 增核酸后对核酸富
集某些序列。
[0225]
此外,在一些实施方案中,靶核酸和/或模板核酸可以是高度纯化的,例 如,在与本文中提供的方法一起使用前,核酸可以是至少约70%,80%,90%, 95%,96%,97%,98%,99%或100%不含污染物的。在一些实施方案中, 使用本领域已知的维持靶核酸的质量和大小的方法是有益的,例如可以使用 琼脂糖塞进行靶dna的分离和/或直接转座。也可以在细胞,细胞群,裂解 物和非纯化的dna中直接进行转座。
[0226]
在一些实施方案中,靶核酸可以从生物样品或患者样品获得。如本文中 所用,术语“生物样品”或“患者样品”包括诸如组织和体液的样品。“体 液”可以包括但不限于血液,血清,血浆,唾液,脑脊液,胸膜液,泪液, 乳腺导管液,淋巴,痰液,尿液,羊水和精液。样品可以包括“无细胞”的 体液。“无细胞体液”包括小于约1%(w/w)的全细胞材料。血浆或血清是无 细胞体液的实例。样品可以包括天然或合成来源的样品(即,制成无细胞的 细胞样品)。
[0227]
在上文公开的方法的一些实施方案中,在将靶核酸暴露于转座体之前, 可以将靶核酸片段化(例如,通过超声处理,通过限制性消化,其它机械手 段)。
[0228]
如本文中使用,术语“血浆”是指在血液中发现的无细胞液。可以通过 本领域已知的方法(例如,离心,过滤等)从血液中除去全细胞物质从血液获 得“血浆”。
[0229]
除非另有说明,本技术中的术语“一个”或“一种”表示“一个/种或多 个/种”。
[0230]
当在本文中使用术语“例如”,“如”,“包括”,“包含”或其变体时,这 些术语将不被认为是限制,并且将解释为意味着“但不限于”或“不限于”。
[0231]
以下实施例提供说明性的实施方案,而不以任何方式限制本文提供的发 明。
实施例
[0232]
实施例1:来自基于珠的标签片段化过程的dna簇产率
[0233]
对图3的基于珠的标签片段化过程的dna簇产率进行了评估,并且在图4 的表中显示。在该实施例中,使用相同批次的标签片段化珠(2.8μm珠)对50、 250和1000ng人na12878dna进行标签片段化。使用第二批标签片段化珠(全 重复;2.8μm珠)对na12878dna的第二50ng等份试样进行标签片段化。将珠 结合的标签片段化dna样品进行pcr扩增和纯化。将每个纯化的pcr产物(未 量化)的等分试样(5.4μl)稀释270倍以制备约50pm的储备样品溶液。对于每个 样品,将50pm储备溶液稀释至15、19、21和24pm。将稀释的样品加载到流 动池上以进行簇生成和测序。数据显示,从相同稀释度(约50pm)开始,使 用相同组的珠,三个不同输入水平(即50、250和1000ng)的簇数目在100
‑ꢀ
114%之间。50ng全重复(用不同批次的珠)的簇数目为81%。不同稀释度(15、 19、21和24pm)在约10%内产生相同数目的簇。数据指示,珠在很大程度上 控制了产率,并且产率对于不同的dna输入和不同的重复是可再现的。
[0234]
实施例2:基于珠的标签片段化过程的可再现性
[0235]
图5中显示了图3的基于珠的标签片段化过程的可再现性。在该实施例 中,使用以“相同”转座体密度制成的索引化珠(索引1到6;2.8μm珠)的6种不 同制备物,使用50和500ng的输入na12878 dna制备标签片段化的dna。标 签片段化的dna进行pcr扩增和纯化。将12个纯化的pcr产物合并成两个6 个的合并物(合并物1和合并物2)用于两个hiseq道。每
个合并物包含3-50ng 和3-500ng样品每道。数据表500显示了每个索引化样品的中值插入物大小和 均值插入物大小。
[0236]
实施例3:合并物1的插入物大小和合并物2的插入物大小
[0237]
图6a(图600)和图6b(图650)中分别显示了图5的索引化样品的合并物1 的插入物大小和合并物2的插入物大小。数据还显示,插入物大小在索引化 珠的六种不同制备物之间是一致的。基于珠的标签索引化提供了一种控制插 入物大小和dna产率的机制。
[0238]
实施例4:读段总数的可再现性
[0239]
图7(柱状图700)中显示了图5中所述的实验的读段总数和比对的读段百 分比的可再现性。在两个输入(50ng和500ng)下,对于相同的索引化珠制备物, 读段的总数是相似的。六个索引化珠制备物中的四个(索引1、2、3和6)具有 非常相似的收率;索引化珠制备物4和5显示可由于索引序列的一些变异性。
[0240]
在一个应用中,基于珠的标签片段化过程可以用于外显子组富集测定, 其包括标签片段化步骤,例如illumina的快速捕获富集方案。在目 前的外显子组富集测定(即illumina的快速捕获富集方案)中,基于溶 液的标签片段化(nextera)用于将基因组dna片段化。然后,使用基因特异性 引物来下拉感兴趣的特定基因片段。进行两个富集循环,然后通过pcr富集 下拉的片段,并进行测序。
[0241]
为了评估在外显子组富集测定中使用基于珠的标签片段化过程,使用 25、50、100、150、200和500ng输入dna对人na12878dna进行标签片段 化。根据标准方案从50ng输入dna制备对照文库(na00536)。每个dna输入 都有不同的索引(独特标识符)。使用增强型聚合酶主混合物(epm)进行的10 个pcr循环用于匹配标准方法并确保存在足够量的片段用于下拉。扩增方案 为72℃3分钟,98℃30秒,接着是98℃10秒,65℃30秒,和72℃的1分钟 的10个循环。然后将样品保持在10℃。然后,通过外显子组富集下拉法处理 样品并进行测序。
[0242]
实施例5:在外显子组富集测定中对照和基于珠的标签片段化文库的插入物 大小
[0243]
图8a,8b和8c分别显示了在外显子组富集测定中在对照文库中的插入 物大小的图800,基于珠的标签片段化文库中的插入物大小的图820和汇总数 据表840。数据显示与对照文库相比,基于珠的标签片段化文库具有更宽的 插入物大小展开,但与样品的dna输入无关,插入物大小是非常相似的。
[0244]
实施例6:读段序列的质量
[0245]
图9a,9b和9c分别显示了在图8a,8b和8c的外显子组富集测定中通过 滤器的百分比重复(dups pf)的柱状图900、pct选择碱基的柱状图920、和靶 物上的pct可用碱基的柱状图940。参考图9a,百分比dup pf是在流动池上 的其它地方复制多少个读段的测量。此数字在理想上较低(如本文)以确保所 有簇对结果带来有用的数据。
[0246]
图9b显示了pct选择的碱基,其是在富集过程期间应该已经富集的感兴 趣位点处或附近排序的读段的比率的测量。理想地,此数字将接近1,以反 映富集过程的成功,并且显示了不应该富集的读段不进入所述过程。
[0247]
图9c显示了靶物上的pct可用碱基,其是在富集区域内特定感兴趣碱基 里实际排序的读段比率的测量。理想地,所有富集的读段将在富集读段内的 感兴趣碱基里排序,但是由于标签片段化的随机性质和插入物的可变长度, 可以富集不在感兴趣区域里排序结束的读段。
[0248]
可以使用两种技术来优化插入物大小分布。在一个实例中,spri清洁可 用于除去太小或太大的片段。spri清洁是通过基于大小的选择性dna沉淀和 根据需要保留沉淀的或非沉淀的dna(即,第一步是仅沉淀比期望大小大的 dna并且保留可溶性的较小的片段),除去大于或小于期望大小的片段的过 程。然后,将较小的片段进一步沉淀,此时除去不需要的非常小的片段(仍 然在溶液中),并且保留沉淀的dna,清洗,然后再溶解,给出期望大小的 dna范围。在另一个实例中,可以使用珠表面上的活性转座体的间隔来控制 插入物大小分布。例如,珠表面上的缺口可以用无活性转座体(例如,具有 无活性转座子的转座体)填充。
[0249]
评估了基于珠的标签片段化过程的接近性。表3显示了共享索引的1000 bp窗内发生0、1、2或3个读段的次数。产生具有9种不同的索引化转座体的 珠,并且用于对少量的人dna进行标签片段化。产生读段,比对,并且分析 共享相同索引的1000bp或10kb窗内的读段数目。共享索引的小窗内的一些 读段可以偶然地生成,并且在表3和表4的“随机”行中给出这可能发生多少 次的预测。“珠”行中的数字显示共享索引的1000bp(表3)或10kb(表4)窗的 实际数目。如表3和表4中所示,在1000bp或10kb窗内发现相同索引的实际 次数显著大于随机情况下的预期值。“0”窗显示特定的1000bp窗没有对其定 位的索引化读段的所有次数。该数目在本文是最大的,因为仅非常少量的人 基因组是序列,并且大多数窗没有与它们比对的读段。“1”是仅一个读段定 位到1000bp(或10kb)窗的次数;“2”是2个读段共享1000bp(或10kb)窗内的 索引的次数,等等。这个数据表明,在超过1400个情况中,相同段的dna(超 过10kb)被相同珠标签片段化至少两次且直至5次(在约15000个标签片段化 事件中)。由于片段共享索引,它们不太可能偶然出现,而是来自相同的珠。
[0250][0251]
表4显示了共享索引的10kb窗中的读段数目(多至5)
[0252][0253]
实施例7:从cpt-dna分离游离转座体
[0254]
转座后,使用sephacryl s-400和sephacryl s-200大小排阻层析法将包含 cpt-dna和游离转座体的反应混合物进行柱层析,并且在图22中显示。 cpt-dna标示为ncp dna。
[0255]
实施例8:珠上捕捉探针密度的优化
[0256]
在1μm珠上优化捕捉探针a7和b7的密度,并且在图25中显示了结果。第 1(a7)道和第3(b7)道具有较高的探针密度,并且第2(a7)道和第4(b7)道具有 估算10,000-100,000/1um珠的探针密度。在琼脂糖凝胶中评估捕捉探针与靶 分子的连接产物。约10,000-100,
000/珠的探针密度比具有较高探针密度的那 些具有更好的连接效率。
[0257]
实施例9:测试通过分子内杂交在珠上制备cpt-dna的索引化测序文库的可 行性
[0258]
通过混合具有a7’和b7’捕捉序列(与珠上的a7和b7捕捉序列互补)的转 座子与超活性tn5转座酶制备转座体。将高分子量基因组dna与转座酶混合 以产生cpt-dna。分别地,制备具有固定化寡核苷酸的珠:p5-a7,p7-b7 或p5-a7+p7-b7,其中p5和p7是引物结合序列,并且a7和b7是分别与a7
’ꢀ
和b7’序列互补的捕捉序列。用cpt-dna处理包含单独的p5-a7,单独的 p7-b7,p5-a7+p7-b7的珠或p5-a7和p7-b7珠的混合物,并将连接酶添加到 反应混合物以测定固定化的寡聚物与转座的dna的杂交效率。图26中显示了 结果。仅当将p5-a7和p7-b7在珠上固定化在一起时生成测序文库(第4道), 如琼脂糖凝胶上的高分子量带所示。结果指示分子内杂交的高效率,并证明 了通过分子内杂交在珠上制备cpt-dna索引化测序文库的可行性。
[0259]
实施例10:测试克隆索引化的可行性。
[0260]
制备了几组转座体。在一组中,超活性tn5转座酶与具有5'生物素的转座 子序列tnp1混合以制备转座体1。在另一组中,tnp2具有独特的索引2,具有 5’生物素以制备转座体2。在另一组中,将超活性tn5转座酶与具有5’生物素 的转座子序列tnp3混合,用于转座体3。在另一个中,tnp4具有独特的索引4 和5'-生物素以制备转座体4。将转座体1&2和转座体3&4之每个分别与链霉亲 合素珠混合以产生珠组1和珠组2。然后将两组珠混合在一起,并且与基因组 dna和标签片段化缓冲液一起温育以促进基因组dna的标签片段化。然后, 这继之以标签片段化的序列的pcr扩增。对扩增的dna进行测序以分析索引 序列的插入。如果标签片段化限于珠,则大部分片段将用tnp1/tnp2和 tnp3/tnp4索引进行编码。如果存在分子内杂交,则可以用tnp1/tnp4, tnp2/tnp3,tnp1/tnp3和tnp2/tnp4索引编码片段。图27中显示了5和10个 pcr循环后的测序结果。对照具有混合在一起并固定化在珠上的所有四个转 座子。结果指示大多数序列具有tnp1/tnp2或tnp3/tnp4索引,指示克隆索引 化是可行的。对照显示了索引之间无区别。
[0261]
实施例11:单次反应中的索引化克隆珠转座
[0262]
制备了96个索引化转座体珠组。通过混合含有包含在5'末端的tn5嵌合末 端序列(me)的寡核苷酸的转座子和索引序列来制备个别的索引化转座体。通 过链霉亲合素-生物素相互作用将个别索引化的转座体固定化在珠上。将珠 上的转座体清洗,并且合并珠上的所有96个个别索引化转座体。将与me序 列互补并包含索引序列的寡核苷酸与固定化寡核苷酸退火,创建具有独特索 引的转座子。将96个克隆索引化转座体珠组组合在一起,并且在单个管中在 nextera标签片段化缓冲液存在下与高分子量(hmw)基因组dna一起温育。
[0263]
清洗珠,并且通过用0.1%sds处理反应混合物除去转座酶。用索引化引 物扩增标签片段化的dna,并使用trueseq v3簇试剂盒用pe hiseq流动池v2 进行测序,并分析测序数据。
[0264]
观察读段的簇或岛。每个序列的读段之间的最近邻近距离的图基本上显 示到主峰,一个从簇内(近端)起而另一个从簇之间(远端)起。图30和31中显 示了方法的示意图和结果。岛大小范围约为3-10kb。覆盖碱基的百分比为约 5%至10%。基因组dna的插入物大小为约200-300个碱基。
[0265]
实施例12:珠上转座体的文库大小
[0266]
首先通过混合具有me'序列的第一寡核苷酸,具有me-条形码-p5/p7序列 的第二寡核苷酸和tn5转座酶在溶液中装配转座体。在第一组中,对具有me' 序列的第一寡核苷酸在3'末端进行生物素化。在第二种情况中,对具有me
‑ꢀ
条形码-p5/p7序列的寡核苷酸在5'端进行生物素化。对各种浓度(10nm,50nm 和200mn)的每个所得转座体组,添加链霉亲合素珠,使得转座体固定化在 链亲合素珠上。清洗珠并添加hmw基因组dna并进行标签片段化。在某些 情况下,用0.1%sds处理标签片段化的dna,而在其它情况下,标签片段 化的dna是未处理的。将标签片段化的dna进行pcr扩增5-8个循环并进行 测序。图32中显示了示意图。
[0267]
如图33中所示,sds的处理改善了扩增效率和测序质量。对于转座体具 有3'-生物素的寡核苷酸具有更好的文库大小。
[0268]
图34显示了转座体表面密度对插入物大小的影响。具有5'-生物素的转座 体显示较小大小的文库和更多的自插入副产物。
[0269]
实施例13:输入dna的滴定
[0270]
将各种量的靶hmw dna添加到具有50mm tn5:转座子密度的克隆索引 化珠,并在37℃下温育15或60分钟或在室温下温育60分钟。转座体包含具有 3'-生物素的寡核苷酸。进行标签片段化,用0.1%sds处理反应混合物,并且pcr扩增。对扩增的dna进行测序。图35显示了输入dna对大小分布的影响。 具有10pg输入dna的反应显示最少的信号。对于范围为20,40和200pg的 dna输入,大小分布模式是相似的。
[0271]
实施例14:使用基于溶液和基于珠的方法的岛大小和分布
[0272]
比较使用基于溶液的方法和基于珠的方法的岛大小和分布。在基于溶液 的方法中,在96孔板中装配96个各具有转座子中的独特索引的转座体。添加 hmw基因组dna,进行标签片段化反应。用0.1%sds处理反应产物,并且 进行pcr扩增。对扩增产物进行测序。
[0273]
在基于珠的方法中,在96孔板中装配96个各具有转座子中的独特索引的 转座体。寡核苷酸包含3'-末端生物素。将链霉亲合素珠添加到96孔板中的每 个中并温育,使得转座体固定化在链霉亲合素珠上。将珠分别清洗并合并, 添加hmw基因组dna,在单个反应容器(一罐)中进行标签片段化反应。用 0.1%sds处理反应产物,并且进行pcr扩增。对扩增产物进行测序。
[0274]
在阴性对照中,首先将所有96个转座子序列(每个具有独特的索引)混合 在一起。寡核苷酸包含3'-末端生物素。从个别混合的索引化转座子制备转座 体。将链霉亲合素珠添加到混合物中。添加hmw基因组dna,并且进行标 签片段化反应。用0.1%sds处理反应产物,并且进行pcr扩增。对扩增产物 进行测序。
[0275]
岛内读段的数目相对岛大小作图。如图36中所示的结果指示,类似于基 于溶液的方法,用一罐克隆索引化珠观察到岛(接近读段)。在转座体形成前 混合索引化转座子时,没有观察到岛(接近读段)。在转座体形成前混合转座 子可以给出每珠具有不同索引/转座体的珠,即不是克隆的。
[0276]
实施例15:用cpt-seq的结构变体分析
[0277]
检测60kb杂合缺失
[0278]
测序数据作为fastq文件提取,并且通过解多路复用过程以为每个条形码 生成单个fastq文件。来自cpt测序的fastq文件根据其索引进行解多路复用, 并且与除去重复的参考基因组比对。染色体通过5kb/1kb窗扫描,其中记录显 示扫描窗内任何读段的索引数
目。统计学上对于杂合缺失区域而言,与其相 邻区域相比,仅一半量的dna可用于文库生成,因此索引数目也应当是其近 邻的大致一半。通过从9216个索引化cpt测序数据在5kb窗中扫描在图47a和 47b中显示na12878chr1 60kb杂合缺失。
[0279]
基因融合检测
[0280]
来自cpt测序的fastq文件根据其索引进行解复用,并与参考基因组对齐, 并重新移除。以2kb窗口扫描染色体。每个2kb窗口是一个36864向量,其中 每个元件记录在这个2kb窗口中找到了来自独特索引的多少个读段数目。对 于基因组中的每个2kb窗口对(x,y),计算加权jaccard索引。该索引表示样 品中(x,y)之间的实际距离。这些索引显示为图48所示的热图,每个数据点 表示一对2kb扫描窗口;左上角为均来自区域1的x,y,右下方为均来自区域2 的x,y,右上方为来自区域1交叉区域2的x,y。在这种情况下,基因融合 信号显示为中间的水平线。
[0281]
缺失检测
[0282]
来自cpt测序的fastq文件根据其索引进行解复用,并且与除去重复的参 考基因组比对。在1kb窗中扫描染色体。图49显示遗传缺失的检测结果。
[0283]
实施例16:定相和甲基化检测
[0284]
亚硫酸氢盐转化效率优化
[0285]
在me(嵌合元件区域)和gdna区域对珠上的索引连接的cpt-seq文库评 估转化。优化promega的methyledge亚硫酸氢盐转化系统,以改善效率。
[0286][0287]
分析me序列以测定亚硫酸氢盐转化处理的效率,并且在图50中显示。 附着到珠的索引化连接文库的95%亚硫酸氢盐转化(bsc)。在亚硫酸氢盐条 件之间观察到类似的pcr产率》更苛刻的亚硫酸氢盐处理似乎不降解文库, 并且在图51中所示。观察到珠上索引化的连接文库的约95%bsc。研究改善bsc(c》u)的变量是温度和naoh浓度(变性)。60℃和1m naoh或℃和0.3mnaoh表现良好。
[0288]
对珠文库上测序bsc转化的cpt-seq后观察到预期的测序读段结构。图52 中用ivc图显示了百分比碱基度量。
[0289]
图53显示亚硫酸氢盐转化后pcr后的索引化连接的文库的琼脂糖凝胶 电泳图像。观察到200-500bp文库的预期大小范围。没有dna的反应不产生 索引化连接的文库。
[0290]
实施例17:靶向定相
[0291]
富集全基因组索引化连接的cpt-seq文库。图54是在没有大小选择的富 集前的全基因组索引化的连接的cpt-seq文库的生物分析仪迹线。图55显示 了富集后文库的琼脂糖凝胶分析。
[0292]
下文显示了hla区域的富集统计量:
[0293][0294]
图56显示了对染色体中hla区域应用靶向单元型分型的结果。在左边显 示了全基因组索引化连接的读段文库的富集。每个小柱形代表索引化的短文 库。索引化文库的簇是“岛”,在具有相同索引的单个珠上克隆索引化的区 域,因此在基因组尺度上读段(“岛”特性)的接近度。右边显示了靶向区域 中的文库富集(参见核酸选择性富集wo 2012108864a1)。对hla区域富集读 段。另外,当读段按索引分选并与基因组比对时,它们再次显示“岛”结构, 指示从索引化的连接读段维持接近性信息。
[0295]
实例18:索引交换
[0296]
为了评估转座体复合物的嵌合末端(me)的交换,制备了具有不同索引的 珠。混合后,通过对文库进行测序并报告每个文库的索引来确定索引交换。%
ꢀ“
交换”计算为(d4+d5+e3+e5+f4)/(全部96的总和),并且在图65中显 示。
[0297]
实施例19:通过将转座体复合物更密集布局到链霉亲合素珠降低文库插入物 大小
[0298]
对链霉亲合素磁珠加载1x,6x和12x浓度的tstn5转座体复合物。对每种 珠类型进行epi-cpt seq方案。在agilent bioanalyzer上加载最终的pcr产物 以进行分析,并且在图中显示。当在珠上加载更多的tstn5时,epi-cpt seq 文库片段较小并且具有更大的产率。
[0299]
实施例20:硫酸氢钠转化期间dna文库的片段化。
[0300]
亚硫酸氢盐转化后,dna损伤,导致pcr扩增所需的共同序列(cs2)的 损失。通过bioanalyzer分析dna片段cptseq和epi-cptseq(me-cptseq)文 库。由于亚硫酸氢盐转化过程中的dna损伤,epi-cptseq文库与cptseq文 库相比具有低5倍的产率和更小的文库大小分布,如图70所示。
[0301]
实施例21:tdt介导的ssdna连接反应
[0302]
测试通过末端转移酶(tdt)介导的连接进行的dna末端回收的可行性。 简言之,将5pmole的ssdna模板与tdt(10/50u)一起温育。将弱化子/衔接子 双链体(0/15/25pmoles)和dna连接酶(0/10u)在37℃下温育15m。在tbe-尿素 凝胶上分析延伸/连接的dna产物,并且图71中显示结果。添加所有反应组 分导致衔接头分子几乎完全连接(第5-8道)。
[0303]
对硫酸氢钠转化珠结合文库测试通过末端转移酶(tdt)介导的连接进行 的dna末端回收的可行性,并显示于图72中。简言之,将dna在珠上标签 片段化(前二道),用promega的methyledge硫酸氢盐转化试剂盒处理(第3和4 道),并进行dna拯救方案(第5和6道)。拯救反应后dna文库的产率和大小 明显增加。自插入转座子(si)的丰度也有增加,指示衔接头分子的有效连接。
[0304]
图73中呈现了甲基-cptseq测定的结果。
[0305]
本发明提供了
[0306]
1.制备靶核酸的条形码化dna片段的文库的方法,其包括:
[0307]
a.使靶核酸与多个转座体复合物接触,每个转座体复合物包含:
[0308]
转座子和转座酶,其中所述转座子包含转移链和非转移链,其中所述转 座体复合物的至少一个转座子包含衔接头序列,所述衔接头序列能够与互补 捕捉序列杂交;
[0309]
b.将所述靶核酸片段化成多个片段,并且将多个转移链插入所述片段的 至少一条链的5’端,同时维持所述靶核酸的接近性;
[0310]
c.使所述靶核酸的所述多个片段与多个固体支持物接触,所述多个中的 每个固体支持物包含多个固定化寡核苷酸,每个所述寡核苷酸包含互补捕捉 序列和第一条形码序列,并且其中来自所述多个固体支持物中的每个固体支 持物的所述第一条形码序列不同于来自所述多个固体支持物中的其它固体 支持物的所述第一条形码序列;
[0311]
d.将所述条形码序列信息转移至所述靶核酸片段,从而生成双链片段的 文库,其中至少一条链是用所述第一条形码在5’加标签的,其中相同靶核酸 的至少两个片段接受相同条形码信息。
[0312]
2.用于测定靶核酸序列的接近性信息的方法,所述方法包括:
[0313]
a.使所述靶核酸与多个转座体复合物接触,每个转座体复合物包含:
[0314]
转座子和转座酶,其中所述转座子包含转移链和非转移链,其中所述转 座体复合物的至少一个转座子包含衔接头序列,所述衔接头序列能够与互补 捕捉序列杂交;
[0315]
b.将所述靶核酸片段化成多个片段,并且插入多个转移链,同时维持所 述靶核酸的接近性;
[0316]
c.使所述靶核酸的所述多个片段与多个固体支持物接触,所述多个中的 每个固体支持物包含多个固定化寡核苷酸,每个所述寡核苷酸包含互补捕捉 序列和第一条形码序列,并且其中来自所述多个固体支持物中的每个固体支 持物的所述第一条形码序列不同于来自所述多个固体支持物中的其它固体 支持物的所述第一条形码序列;
[0317]
d.将所述条形码序列信息转移至所述靶核酸片段,其中相同靶核酸的至 少两个片段接受相同条形码信息;
[0318]
e.测定所述靶核酸片段的序列和所述条形码序列;
[0319]
f.通过鉴定所述条形码序列测定所述靶核酸的所述接近性信息。
[0320]
3.用于同时测定靶核酸序列的定相信息和甲基化状态的方法,所述方法 包括:
[0321]
a.使所述靶核酸与多个转座体复合物接触,每个转座体复合物包含:
[0322]
转座子和转座酶,其中所述转座子包含转移链和非转移链,其中所述转 座体复合物的至少一个转座子包含衔接头序列,所述衔接头序列能够与互补 捕捉序列杂交;
[0323]
b.将所述靶核酸片段化成多个片段,并且插入多个转移链,同时维持所 述靶核酸的接近性;
[0324]
c.使所述靶核酸的所述多个片段与多个固体支持物接触,所述多个中的 每个固体支持物包含多个固定化寡核苷酸,每个所述寡核苷酸包含互补捕捉 序列和第一条形码序列,并且其中来自所述多个固体支持物中的每个固体支 持物的所述第一条形码序列不同于来自所述多个固体支持物中的其它固体 支持物的所述第一条形码序列;
[0325]
d.将所述条形码序列信息转移至所述靶核酸片段,其中相同靶核酸的至 少两个片段接受相同条形码信息;
[0326]
e.对包含条形码的所述靶核酸片段进行亚硫酸氢盐处理,从而生成经亚 硫酸氢盐处理的包含条形码的靶核酸片段;
[0327]
f.测定所述经亚硫酸氢盐处理的靶核酸片段的序列和所述条形码序列;
[0328]
g.通过鉴定所述条形码序列测定所述靶核酸的接近性信息,
[0329]
其中所述序列信息指示所述靶核酸的甲基化状态,并且所述接近性信息 指示单元型信息。
[0330]
4.项1-3中任一项的方法,其中单一条形码序列存在于每个单独的固体 支持物上的所述多个固定化寡核苷酸中。
[0331]
5.项1-3中任一项的方法,其中不同条形码序列存在于每个单独的固体 支持物上的所述多个固定化寡核苷酸中。
[0332]
6.项1-5中任一项的方法,其中通过连接将所述条形码序列信息转移至 所述靶核酸片段。
[0333]
7项1-5中任一项的方法,其中通过聚合酶延伸将所述条形码序列信息 转移至所述靶核酸片段。
[0334]
8.项1-5中任一项的方法,其中通过连接和聚合酶延伸两者将所述条形 码序列信息转移至所述靶核酸片段。
[0335]
9.项7-8中任一项的方法,其中所述聚合酶延伸是通过使用连接的固定 化寡核苷酸作为模板用dna聚合酶延伸非连接转座子链的3’端。
[0336]
10.项1-9中任一项的方法,其中所述衔接头序列的至少部分进一步包含 第二条形码序列。
[0337]
11.项1-10中任一项的方法,其中所述转座体复合物是多聚体的,并且 其中每个单体单元的转座子的所述衔接头序列不同于相同转座体复合物中 的其它单体单元。
[0338]
12.项1-11中任一项的方法,其中所述衔接头序列还包含第一引物结合 序列。
[0339]
13.项12的方法,其中所述第一引物结合序列与所述捕捉序列或与所述 捕捉序列的互补物没有序列同源性。
[0340]
14.项1-13中任一项的方法,其中所述固体支持物上的所述固定化寡核 苷酸进一步包含第二引物结合序列。
[0341]
15.项1-14的方法,其中所述转座体复合物是多聚体的,并且其中所述 转座体单体单元在相同转座体复合物中彼此连接。
[0342]
16.项15的方法,其中转座体单体单元的所述转座酶与相同转座体复合 物的另一个转座体单体单元的另一个转座酶连接。
[0343]
17.项15的方法,其中转座体单体单元的所述转座子与相同转座体复合 物的另一个转座体单体单元的转座子连接。
[0344]
18.项1-17中任一项的方法,其中靶核酸序列的所述接近性信息指示单 元型信息。
[0345]
19.项1-17中任一项的方法,其中靶核酸序列的所述接近性信息指示基 因组变体。
[0346]
20.项19的方法,其中所述基因组变体选自下组:缺失、易位、染色体 间基因融合、重复(duplication)、和旁系同系物(paralog)。
[0347]
21.项1-20中任一项的方法,其中所述固体支持物上固定化的所述寡核 苷酸包含部分双链区和部分单链区。
[0348]
22.项21的方法,其中所述寡核苷酸的所述部分单链区包含所述第二条 形码序列和所述第二引物结合序列。
[0349]
23.项1-22中任一项的方法,其中在测定所述靶核酸片段的序列前扩增 包含所述条形码的靶核酸片段。
[0350]
24.项23的方法,其中在测定所述靶核酸片段的序列前在单一反应区室 中实施步骤(a)-(d)和后续扩增。
[0351]
25.项23的方法,其中在所述扩增期间将第三条形码序列引入所述靶核 酸片段。
[0352]
26.项1-24中任一项的方法,其进一步包括:
[0353]
将来自多个第一组反应区室的步骤(d)的包含所述条形码的所述靶核酸 片段组合成包含所述条形码的靶核酸片段的合并物;
[0354]
将包含所述条形码的靶核酸片段的所述合并物再分配到多个第二组反 应区室;
[0355]
通过在测序前在所述第二组反应区室中扩增所述靶核酸片段将第三条 形码引入所述靶核酸片段中。
[0356]
27.项1-26中任一项的方法,其进一步包括在使所述靶核酸与转座体复 合物接触前将所述靶核酸预先片段化。
[0357]
28.项27的方法,其中通过选自下组的方法将所述靶核酸预先片段化: 超声处理和限制性消化。
[0358]
29.制备有标签的dna片段的固定化文库的方法,其包括:
[0359]
(a)提供多个固体支持物,所述固体支持物具有其上固定化的转座体复 合物,其中所述转座体复合物是多聚体的,并且相同转座体复合物的转座体 单体单元彼此连接,并且其中所述转座体单体单元包含与第一多核苷酸结合 的转座酶,所述第一多核苷酸包含
[0360]
(i)包含转座子端序列的3’部分,和
[0361]
(ii)包含第一条形码的第一衔接头,
[0362]
(b)在条件下将靶dna应用于所述多个固体支持物,从而通过所述转座 体复合物使所述靶dna片段化,并且将所述第一多核苷酸的所述3’转座子端 序列转移至所述片段的至少一条链的5’端;由此生成双链片段的固定化文 库,其中至少一条链是用所述第一条形码在5’加标签的。
[0363]
30.项29的方法,其中转座体单体单元的所述转座酶与相同转座体复合 物的另一个转座体单体单元的另一个转座酶连接。
[0364]
31.项29的方法,其中转座体单体单元的所述转座子与相同转座体复合 物的另一个转座体单体单元的转座子连接。
[0365]
32.制备测序文库以测定靶核酸的甲基化状态的方法,其包括:
[0366]
a.将所述靶核酸片段化成两个或更多个片段;
[0367]
b.将第一共同衔接头序列掺入所述靶核酸的片段的5’端,其中所述衔接 头序列包含第一引物结合序列和亲和力模块(moiety),其中所述亲和力模块 在结合对的一个成员中;
[0368]
c.使所述靶核酸片段变性;
[0369]
d.在固体支持物上固定化所述靶核酸片段,其中所述固体支持物包含所 述结合对的另一个成员,并且通过所述结合对的结合固定化所述靶核酸;
[0370]
e.对所述固定化靶核酸片段进行亚硫酸氢盐处理;
[0371]
f.将第二共同衔接头序列掺入经亚硫酸氢盐处理的固定化靶核酸片段, 其中所述第二共同衔接头包含第二引物结合位点;
[0372]
g.使用第一和第二引物扩增固体支持物上固定化的经亚硫酸氢盐处理 的靶核酸片段,从而生成测序文库以测定靶核酸的甲基化状态。
[0373]
33.项32的方法,其中通过一侧转座将所述第一共同衔接头序列掺入所 述靶核酸的5’端片段。
[0374]
34.项32的方法,其中通过连接将所述第一共同衔接头序列掺入所述靶 核酸的所述5’端片段。
[0375]
35.项32-34中任一项的方法,其中将所述第二共同衔接头序列掺入经亚 硫酸氢盐处理的固定化靶核酸片段包括:
[0376]
(i)使用末端转移酶延伸所述固定化靶核酸片段的3’端,使得所述固定化 靶核酸片段的3’端包含同聚体尾;
[0377]
(ii)杂交包含第一部分和第二部分的寡核苷酸,其中所述第一部分包含 单链同聚体部分,其与所述固定化的靶核酸片段的同聚体尾互补,并且其中 所述第二部分包含双链部分,其包含所述第二共同衔接头序列;
[0378]
(iii)将所述第二共同衔接头序列与所述固定化靶核酸片段连接,从而将 所述第二共同衔接头序列掺入经亚硫酸氢盐处理的固定化靶核酸片段。
[0379]
36.项1-35中任一项的方法,其中所述靶核酸来自单一细胞。
[0380]
37.项1-36中任一项的方法,其中所述靶核酸来自单一细胞器。
[0381]
38.项1-37中任一项的方法,其中所述靶核酸是基因组dna。
[0382]
39.项1-38中任一项的方法,其中所述靶核酸与其它核酸交联。
[0383]
40.项1-39中任一项的方法,其中所述靶核酸是无细胞的肿瘤dna。
[0384]
41.项40的方法,其中从胎盘流体获得所述无细胞的肿瘤dna。
[0385]
42.项40的方法,其中从血浆获得所述无细胞的肿瘤dna。
[0386]
43.项42的方法,其中使用包含所述血浆的收集区的膜分离器从全血收 集所述血浆。
[0387]
44.项43的方法,其中所述血浆的收集区包含固体支持物上固定化的转 座体复合物。
[0388]
45.项1-37中任一项的方法,其中所述靶核酸是cdna。
[0389]
46.项1-37中任一项的方法,其中所述靶核酸来自福尔马林固定的石蜡 包埋的组织样品。
[0390]
47.项1-37中任一项的方法,其中所述靶核酸是组蛋白保护的dna。
[0391]
48.项1-47中任一项的方法,其中所述固体支持物是珠。
[0392]
49.项1-31的方法,其中所述多个固体支持物是多个珠,并且其中所述 多个珠是不同大小的。
[0393]
50.制备测序文库以测定靶核酸的甲基化状态的方法,其包括:
[0394]
a.提供多个固体支持物,所述固体支持物包含其上固定化的固定化转座 体复合物,其中所述转座体复合物包含转座子和转座酶,其中所述转座子包 含转移链和非转移链,所述转移链包含:
[0395]
(i)在3’端的第一部分,其包含转座酶识别序列,和
[0396]
(ii)位于所述第一部分的5’的第二部分,其包含第一衔接头序列和结合 对的第一成员,其中所述结合对的所述第一成员结合所述固体支持物上的所 述结合对的第二成员,从而将所述转座子固定化至所述固体支持物,并且其 中所述第一衔接头包含第一引物结合序列;
[0397]
所述非转移链包含:
[0398]
(i)5’端的第一部分,其包含所述转座酶识别序列,
[0399]
(ii)位于所述第一部分的3’的第二部分,其包含第二衔接头序列,其中3
’ꢀ
端的末端核苷酸被封闭,并且其中所述第二衔接头包含第二引物结合序列;
[0400]
b.使靶核酸与包含固定化转座体复合物的所述多个固体支持物接触;
[0401]
c.将所述靶核酸片段化成多个片段,并且将多个转移链插入所述片段的 至少一条链的5’端,从而将所述靶核酸片段固定化至所述固体支持物;
[0402]
d.用dna聚合酶延伸片段化的靶核酸的3’端;
[0403]
e.将所述非转移链与所述片段化靶核酸的3’端连接;
[0404]
f.对所述固定化靶核酸片段进行亚硫酸氢盐处理;
[0405]
g.通过使用dna聚合酶延伸所述亚硫酸氢盐处理期间损伤的固定化靶 核酸片段的3’端,使得所述固定化靶核酸片段的3’端包含同聚体尾;
[0406]
h.将第二衔接头序列掺入所述亚硫酸氢盐处理期间损伤的固定化靶核 酸片段的3’端;
[0407]
i.使用第一和第二引物扩增固体支持物上固定化的经亚硫酸氢盐处理 的靶核酸
片段,从而生成测序文库以测定靶核酸的甲基化状态。
[0408]
51.制备测序文库以测定靶核酸的甲基化状态的方法,其包括:
[0409]
a.使所述靶核酸与转座体复合物接触,其中所述转座体复合物包含转座 子和转座酶,其中所述转座子包含转移链和非转移链,所述转移链包含:
[0410]
(i)在3’端的第一部分,其包含转座酶识别序列,和
[0411]
(ii)位于所述第一部分的5’的第二部分,其包含第一衔接头序列和结合 对的第一成员,其中所述结合对的所述第一成员结合所述结合对的第二成 员;
[0412]
所述非转移链包含:
[0413]
(i)5’端的第一部分,其包含所述转座酶识别序列,
[0414]
(ii)位于所述第一部分的3’的第二部分,其包含第二衔接头序列,其中3
’ꢀ
端的末端核苷酸被封闭,并且其中所述第二衔接头包含第二引物结合序列,
[0415]
b.将所述靶核酸片段化成多个片段,并且将多个转移链插入所述片段的 至少一条链的5’端,从而将所述靶核酸片段固定化至所述固体支持物;
[0416]
c.使包含所述转座子末端的靶核酸片段与包含所述结合对的第二成员 的所述多个固体支持物接触,其中所述结合对的第一成员与所述结合对的第 二成员的结合将所述靶核酸固定化至所述固体支持物;
[0417]
d.用dna聚合酶延伸所述片段化的靶核酸的3’端;
[0418]
e.将所述非转移链与所述片段化的靶核酸的3’端连接;
[0419]
f.对所述固定化的靶核酸片段进行亚硫酸氢盐处理;
[0420]
g.通过使用dna聚合酶延伸所述亚硫酸氢盐处理期间损伤的固定化靶 核酸片段的3’端,使得所述固定化靶核酸片段的3’端包含同聚体尾;
[0421]
h.将第二衔接头序列引入所述亚硫酸氢盐处理期间损伤的固定化靶核 酸片段的3’端;
[0422]
i.使用第一和第二引物扩增固体支持物上固定化的经亚硫酸氢盐处理 的靶核酸片段,从而生成测序文库以测定靶核酸的甲基化状态。
[0423]
52.项50-51中任一项的方法,其中所述固体支持物是珠。
[0424]
53.项50-52中任一项的方法,其中所述结合对的所述第一和第二成员是 生物素和链霉亲合素。
[0425]
54.项50-51中任一项的方法,其中所述第一衔接头进一步包含条形码。
[0426]
55.项50-51中任一项的方法,其中所述第二衔接头进一步包含条形码。
[0427]
56.项50-51中任一项的方法,其中所述第一和第二衔接头包含第一和第 二衔接头包含第一和第二条形码。
[0428]
57.项50-51中任一项的方法,其中通过末端转移酶延伸所述亚硫酸氢盐 处理期间损伤的固定化靶核酸片段的3’端。
[0429]
58.项50-57中任一项的方法,其中所述第二衔接头的3’端的末端核苷酸 被选自下组的成员封闭:二脱氧核苷酸、磷酸基团、硫代磷酸基团、和叠氮 基基团。