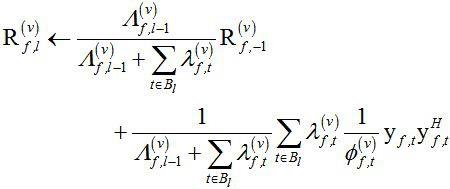
1.本发明属于语音信号处理的技术领域,具体涉及一种复杂环境中使用传声器阵列的语音前端,用于提升服务型机器人的语音采集质量。
背景技术:
2.语音交互系统,作为最快捷有效的智能人机交互系统,在我们的生活中无处不在。语音交互系统需要在不同的场景下捕捉使用者的说话音频,在语音增强与分离等预处理步骤后进行自动语音识别(automatic speech recognition, asr)。在远场、嘈杂等声学环境恶劣的情况下,识别准确率迅速下降。为了提高系统的鲁棒性,需要利用各种算法进行语音增强以提高语音的质量和可靠度。语音增强主要包括:语音分离、语音去混响和语音降噪,三者要解决的干扰分别来源于其他说话人的声音信号、空间环境对声音信号反射产生的混响和各种环境噪声。语音增强通过有效抑制这些噪声或人声来提高语音质量,现已应用于语音识别、助听器以及电话会议等。
3.传声器阵列指两个或以上的传声器单元以特定空间位置排列组成的声学系统,配合信号处理方法,能够达到声源定位、盲源分离、声全息和语音增强等目的。此技术在传统的通信、生物医学工程等领域以及最近热门的虚拟现实(vr)、增强现实(ar)和人工智能(ai)领域皆有广泛的应用前景。基于阵列的增强方案包括阵列波束形成(beamforming)与盲源分离(higuchi t, ito n, yoshioka t, et al. robust mvdr beamforming using timefrequency masks for online/offline asr in noise[c] // 2016 ieee international conference on acoustics, speech and signal processing (icassp). 2016 :5210
ꢀ–ꢀ
5214.)等。
[0004]
传声器阵列波束形成,即按照阵列和声源的相关空间位置的导向矢量(steering vector)设计空间滤波器。按照空间滤波器参数可变与否,分为固定波束形成和自适应波束形成。固定波束由于滤波器参数不可调整,具有相对自适应波束更差的抗干扰能力和分辨率。当声源位置时变时,固定波束性能显著下降。但是其运算量较小、易于实现、且对传声器和声源位置的准确性有更好的鲁棒性。
[0005]
固定波束设计的设计目标是使波束主瓣指向目标声源,达到增强声源信号,抑制其他方向噪声信号的目的。延时求和(delay and sum, ds)波束(brandstein m, ward d. microphone arrays: signal processing techniques and applications[m]. [s.l.] : springer science & business media, 2013.)是最常用的固定波束算法,它对于扰动鲁棒性好,但是主瓣随频率升高而变窄,即频率越高指向性越强,导致信号低通畸变。另外,延时求和波束要获得好的指向,需要足够多的单元数量。固定波束算法难以设计具有任意指向性的波束,而宽带波束的方法可以根据不同的代价函数和滤波求和结构,设计满足空间特征的波束:最小二乘法(least square, ls)、特征滤波器法(eigenfilter method)、基于阵列特征参数的方法、非线性优化波束(doclo s. multimicrophone noise reduction and dereverberation techniques for speech applications[j], 2003.)等。
[0006]
自适应波束设计结合了波束指向性和空间信息自适应的特点,通过一定的迭代方式使实际响应接近期望响应。自适应波束根据不同的策略,如线性约束最小化方差(linearly constrained minimum variance, lcmv)策略、广义旁瓣抵消(generalized sidelobe cancellation, gsc)策略等。其中,lcmv的应用之一最小方差无失真响应(minimum variance distortionless response, mvdr)波束是应用得最广泛的自适应波束之一,也是本发明阵列的波束形成策略。
[0007]
常用的语音增强算法一般将处理重点放在音频信号本身。而人脑在处理别人传达的信息时,往往是将多种模态的信息,例如肢体语言、嘴唇动作和面部表情等,融合在一起处理的。与之类似,在设计语音增强解决方案时,若能充分关注这些多模特征,有望进一步提升系统性能。另外,在机器人人机交互、车载交互、视频会议等语音交互系统中,信息的传入设备同时包含传声器(阵列)和摄像头,这也为结合视频信息处理语音增强问题提供了基本的硬件条件。
[0008]
图像序列的行为识别任务有一个通用的框架,即用卷积神经网络(convolutional neural networks, cnn)提取特征,再通过几层循环神经网络(recurrent neural network, rnn)以方便利用帧与帧之间的关联信息(donahue j, anne hendricks l, guadarrama s, et al. longterm recurrent convolutional networks for visual recognition and description[c]// proceedings of the ieee conference on computer vision and pattern recognition.2015 : 2625
ꢀ–ꢀ
2634.)。本发明也采取类似的网络设置来对唇部图像的vad判决进行预测,以期望达到图像唇读vad的sota方案的准确性。
技术实现要素:
[0009]
发明目的:传统只依赖音频信息的语音增强方法在对低信噪比、非稳态噪声、强混响环境下的语音进行增强时往往难以去除噪声成分,这对后续机器人的语音识别和语义理解造成了巨大的困难,本发明提供一种服务型机器人语音交互的音视频混合语音前端处理方法,本发明提出结合图像和视频分析的多模语音增强方案,其具有不错的鲁棒性,并且在低信噪比时对语音识别效果提升很明显。
[0010]
技术方案:为实现上述目的,本发明采用的技术方案为:一种服务型机器人语音交互的音视频混合语音前端处理方法,包括以下步骤:步骤1,模型训练:采集训练音视频样本,将训练音视频样本中视频部分按帧分成图像,将训练音视频样本中语音部分按对应帧图像进行标签,得到对应帧的干净语音vad标签。将图像和对应帧的干净语音vad标签导入cnn
‑
rnn图像分类网络中,对图像中的唇动状态和应帧的干净语音vad标签进行训练,得到训练好的cnn
‑
rnn图像分类网络。
[0011]
步骤2,采集目标说话人嘴部动作视频和对应的含噪语音。嘴部动作视频用卷积神经网络方法标记出目标说话人人脸五官定位,并裁出嘴唇区域图像。嘴唇区域图像逐帧进行灰度图重塑得到嘴唇区域灰度图像,将嘴唇区域灰度图像输入到图像活动语音检测器。
[0012]
步骤3,图像活动语音检测器根据输入的嘴唇区域灰度图像检测到目标说话人正在说话,则将嘴唇区域灰度图像输入到训练好的cnn
‑
rnn图像分类网络中,得到此帧嘴唇区域灰度图对应的图像语音vad概率。
[0013]
步骤4,对含噪语音做短时傅里叶变换得到短时傅里叶频谱。
[0014]
使用清晰视频数据集的音频、多通道噪声数据集,并根据相应的传声器空间位置以及随机声源位置模拟出相应传声器采集到的含噪语音。
[0015]
步骤5,将图像语音vad概率通过非线性的映射函数得到映射后图像语音概率,映射后图像语音概率与相应帧的所对应音频信号的短时傅里叶频谱进行时域上的加权操作,进行图像vad和传声器阵列信号的多模融合,得到图像vad加权后的传声器阵列信号频谱。
[0016]
本发明相比现有技术,具有以下有益效果:本发明从传声器阵列和声源的相对空间位置入手,利用复高斯混合模型(cgmm),期望最大化(em)方法以及最小方差无失真响应(mvdr)波束来增强目标源方向的语音。其中时频掩模的使用能够避免使用不准确的先验知识,例如阵列几何和平面波传播假设,从而提供稳健的导向矢量估计。在此基础上,为了提高在低信噪比、非稳态噪声等多种复杂噪声场景下算法的有效性,采用了对噪声不敏感的图像模态的信息作为补充,用唇部图像生成可靠的vad判决。在 cgmm分类系统的前端融合 vad 可有效提高语音时频掩膜的准确性,从而得到更好的音质和语音可懂度,为后续语音识别任务提供更优质的前端输入。
附图说明
[0017]
图1是本发明的结合图像和视频处理的多模语音增强处理流程图。
[0018]
图2是用卷积神经网络方法标记出目标说话人人脸的五官定位,并裁出嘴唇区域的处理结果。
[0019]
图3为嘴唇图像处理部分的2d cnn
‑
rnn神经网络的框架,其中包括二维卷积层组成的编码器,随后经过长短期记忆网络块,接着得到此刻唇动状态vad的预测。
[0020]
图4为一个声源时的问题框架示意图。
[0021]
图5为模拟含噪语音生成的空间示意图。
具体实施方式
[0022]
下面结合附图和具体实施例,进一步阐明本发明,应理解这些实例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本技术所附权利要求所限定的范围。
[0023]
一种服务型机器人语音交互的音视频混合语音前端处理方法,如图1所示,包括以下步骤:步骤1,模型训练:采集训练音视频样本,将训练音视频样本中视频部分按帧分成图像,将训练音视频样本中语音部分按对应帧图像进行标签,得到对应帧的干净语音vad标签。将图像和对应帧的干净语音vad标签导入cnn
‑
rnn图像分类网络中,对图像中的唇动状态和应帧的干净语音vad标签进行训练,得到训练好的cnn
‑
rnn图像分类网络。
[0024]
步骤2,采集目标说话人嘴部动作视频和对应的含噪语音。嘴部动作视频用卷积神经网络方法标记出目标说话人人脸五官定位,并裁出嘴唇区域图像,截取如图2所示。嘴唇区域图像逐帧进行90
×
110像素的灰度图重塑,并归一化数据格式到16位浮点数,得到嘴唇区域灰度图像,将嘴唇区域灰度图像输入到图像活动语音检测器。
[0025]
步骤3,图像活动语音检测器根据输入的嘴唇区域灰度图像检测到目标说话人正
在说话,则将嘴唇区域灰度图像输入到训练好的cnn
‑
rnn图像分类网络中,得到此帧嘴唇区域灰度图对应的图像语音vad概率,如图3所示,首先第一列嘴唇区域灰度图序列经过二维卷积层组成的编码器,随后经过长短期记忆网络块,接着得到此刻唇动状态的预测,输出根据图像信息判决此帧为图像语音vad概率。
[0026]
步骤4,使用清晰视频数据集的音频、多通道噪声数据集,并根据相应的传声器空间位置以及随机声源位置模拟出相应传声器采集到的含噪语音,如图5所示,对含噪语音做短时傅里叶变换得到短时傅里叶频谱,其中信号处理的参数设置见表1。
[0027]
表1 音频算法的实验参数步骤5,将图像语音vad概率通过非线性的映射函数得到映射后图像语音概率,映射后图像语音概率与相应帧的所对应音频信号的短时傅里叶频谱进行时域上的加权操作,进行图像vad和传声器阵列信号的多模融合,得到图像vad加权后的传声器阵列信号频谱。
[0028]
其中映射函数的定义域和值域都在[0,1],可以理解为一种额外设计的激活函数,目的是为了让加权操作更加平滑。映射具体函数关系见式(1),加权方式见式(2):
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)其中,表示映射后图像语音概率,是图像语音vad概率,即cnn
‑
rnn图像分类网络预测结果,是图像的时间帧索引,表示短时傅里叶频谱,表示频域,表示时刻。
[0029]
步骤6,将得到的图像vad加权后的传声器阵列信号频谱输入基于复数高斯混合模型cgmm的时频掩模估计器,然后用最大似然法估计cgmm 参数,得到时频掩膜序列。然后对于所有频域点数,依次在线递归更新空间相关矩阵,含噪语音和噪声的协方差矩阵,以及聚类的混合权重。最后更新所有源的期望协方差矩阵并作时间平滑,分离它们的特征向量作为对应源导向矢量的估计,用mvdr波束的空间最优权矢量滤波器得到目标方向增强的语音信号。
[0030]
一、问题框架k ∈ {1, ..., k}是源索引,k表示源信号个数,m ∈ {1, ..., m} 是传声器索引,m表示传声器个数。在时域中,第 m 个传声器的语音信号可以写为:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)其中,表示第 m 个传声器的语音信号,表示第 k 个源信号的噪声信号,表示第 m 个传声器采集到的噪声信号,表示对应于第k 个源和第 m 个传声器之间的脉冲响应,如图4所示,是图像的时间帧索引,表示时刻。
[0031]
第 m 个传声器的语音信号通过应用短时傅立叶变换(shorttime fourier transform, stft),公式 (3)可以在频域中表示为:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)其中,为的频域表示,为的频域表示,为的频域表示,为的频域表示。
[0032]
这里我们假设脉冲响应的长度远小于 stft 窗口的长度,因此,脉冲响应和源信号在时域中的卷积表示为时不变频率响应和时变源信号在频域中的乘积,引入矢量符号,式(4)可以改写为:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)其中:其中:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)其中,表示被噪声混合的观测信号,表示第 k 个信号源和各个传声器之间的频率响应,
ꢀꢀ
是导向矢量,表示源信号的短时傅立叶变换,表示噪声信号的短时傅立叶变换,t 表示非共轭转置。
[0033]
源分离 (或语音增强) 问题的目标是凭借被噪声混合的观测信号估计每个目标源信号。
[0034]
二、结合图像信息的cgmm
‑
mvdr在线方法:初始化协方差矩阵,掩膜和,聚类的混合权重,取前1000ms作为空间相关矩阵的粗略估计。分别表示含噪语音、噪声、干净语音。
[0035]
首先通过基于复数高斯混合模型cgmm的时频掩模估计器进行cgmm的em方法掩膜估计,在掩膜估计期望步骤(e step)中后验概率用以下式子计算:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)其中,表示类的掩膜,表示类的混合权重,表示条件概率,表示含噪语
音、噪声、干净语音中的任意一类,表示一系列cgmm参数。
[0036]
步骤5得到的图像vad加权后的传声器阵列信号频谱得到混合权重为的复高斯混合模型,如下所示:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)其中,表示复数高斯混合分布,表示时频点的信号方差,表示类的空间相关矩阵。
[0037]
具有均值
µ
和协方差矩阵σ的多元复高斯分布为:
ꢀꢀꢀꢀꢀꢀꢀ
(9)其中,表示随机变量为x均值为方差为的复数高斯混合分布,表示随机变量,表示均值,表示方差,表示共轭转置。
[0038]
在掩膜估计最大化步骤(m step)中,cgmm 参数用以下式子更新:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)其中,表示类时频点的信号方差,表示空间相关矩阵的维度,表示取矩阵的迹,表示含噪语音的观测信号的时频点,表示空间相关矩阵取逆。
[0039]
在每个 em 迭代步骤里被最大化的 q 函数为:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)直至em方法迭代达到指定次数。
[0040]
em方法迭代指定次数后,第批处的空间相关矩阵由下式递归估计:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(12)含噪语音和噪声的协方差矩阵被在线递归更新为:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(13)
递归更新混合权重:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(14)以上步骤对于所有频率点都更新完,随后进行导向矢量的估计。
[0041]
通过导向向量估计器进行导向向量估计:先计算含噪语音和噪声的协方差矩阵估计:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(15)得到k
‑
th语音信号协方差矩阵估计:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(16)然后对执行特征向量分解,提取最大特征值相关联的特征向量作为导向向量的估计。
[0042]
最后进行mvdr波束形成,得到增强语音。
[0043]
mvdr波束的k
‑
th源的滤波器系数:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(17)得到增强的k
‑
th源信号估计:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(18)表示增强的k
‑
th源信号估计。
[0044]
由于是在线算法,故以上操作都只针对某一批次的每个时间点,结束这一批次以后,需要更新掩膜和:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(19)然后进行下次批次的更新,直到音频结束。
[0045]
三、.数据集与评价指标噪声来自demand多通道噪声库,纯净目标源来自 timit 库。共模拟数据 120(干净音频)*12(噪声种类)=1440(组)。对于在线处理,每个音频的前 1000ms,约31帧作为训练数据以估计可靠的初始空间相关矩阵。由于 timit 库的音频说话开始时间皆小于 1000ms,这样做是可行的。
[0046]
评价指标包括经常被用来衡量语音分离效果的尺度不变的信号失真比(si
‑
sdr),其定义为
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(20)
其中,和分别是干净语音和估计的目标语音,它们被零均值归一化以保证尺度不变性。表示干净语音在干净语音和估计语音相关系数的归一化的方向的投影,表示编程语言里的赋值语句的符号,表示估计的噪声信号。
[0047]
除了si
‑
sdr之外,评价指标还有语音质量客观评价指标pesq。
[0048]
四、实验结果对比是否结合图像信息的cgmm
‑
mvdr在线算法,对不同信噪比混合语音处理前后的效果用处理前后指标的差值表示,数值越大代表改善越大,测试结果如表2所示:表2 测试结果标准cgmm
‑
mvdr算法不含图像的多模处理,为混合处理为否的部分。它在含噪语音为0db左右的时候si
‑
sdr改善最多,而pesq则是含噪语音信噪比越低处理前后改善越多。因为含噪语音信噪比越低,初始分数越低。
[0049]
多模混合处理方案在极低信噪比snr=
‑
10db时,相对于标准方案,si
‑
sdr还能再提高1.06db,babble类人声噪音此提高幅度更甚。由于多模融合时粗暴的幅度加权,pesq效果略逊色。但是实际在使用时,由于多模检测为不说话的时间段上本来就不需要语音识别,所以pesq的逊色只会影响听感,而不影响后续语音识别。反而准确的图像vad判决会为后续的语音识别任务强调重点识别的地方,在目标说话人闭嘴时忽略其他类似的人声噪声。
[0050]
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。